���O�t���p�C�v�������Ă݂�
Unix/Linux �ɂ� ���O�t���p�C�v�Ƃ������̂�����܂��B
Unix�h���C���\�P�b�g�̐����Łu���O�t���p�C�v�ɗގ������@�\������`�v�Ə����Ă����� ���܂ʼn��ƂȂ��u�p�C�v�ɖ��O�t�����ȁv���炢�ɂƎv���Ă܂����� ���ۂɎg�������Ƃ��Ȃ������̂ŁA�����Ă݂܂��B
�g�p����̂� mkfifo �Ƃ����R�}���h�B
$ mkfifo /tmp/namedpipe
����ō쐬�����B
$ ls -l /tmp/namedpipe prw-rw-r-- 1 xxxxx xxxxx 0 Oct 22 22:06 /tmp/namedpipe
�Ȃł��Ă܂��� �����̐擪�� "p" �ɂȂ��Ă܂��B
�@�\�͂Ȃ�ƂȂ��z���ł��܂��ˁB
������m�F���邽�߂ɁA �܂��ʂ̃R���\�[���� ���̖��O�t���p�C�v�� tail ���܂��B
$ tail -f /tmp/namedpipe
�ҋ@��ԂɂȂ�܂����B
tail ���Ă���R���\�[���Ƃ͕ʂ̃R���\�[���� ���O�t���p�C�v�Ɍ������ă��_�C���N�g���Ă݂܂��B
$ echo test1 > /tmp/namedpipe $ echo test2 > /tmp/namedpipe
tail ���Ă���R���\�[������ �o�͂���Ă����܂��B
$ tail -f /tmp/namedpipe
test1
test2
�Ȃ�قǁA���ڂȂ����Ă��Ȃ��Ă� ���O�t���p�C�v��ʂ��ăf�[�^���A�g�ł��Ă܂��ˁB
rm �R�}���h�ō폜�ł��܂��B
$ rm /tmp/namedpipe
�����܂ł��ƁA�قڒʏ�̃t�@�C�����g���Ă������悤�Ȃ��Ƃ��ł��܂��� ���� tail ���Ă��Ȃ���ԂŃ��_�C���N�g����� �ʏ�̃t�@�C���Ƃ͈Ⴄ�����ɂȂ�܂����B
$ echo test3 > /tmp/namedpipe
���� ���O�t���p�C�v�� tail ���Ă��Ȃ��Ƃ��̏�Ԃ� ���_�C���N�g����� ���_�C���N�g���������ҋ@��ԂɂȂ�܂��B
���� ���O�t���p�C�v�� tail �� cat �Ȃǂ���� ���_�C���N�g���̑ҋ@����������܂��B
$ cat /tmp/namedpipe
test3
�֗��Ɏg����P�[�X�͂��肻���ł��ˁB
bash �� ��C���^���N�e�B�u���[�h �ł� alias �͎��s�ł��Ȃ�
������ƃn�}�肩�����̂Ń����B
bash �� �ualias ���g������֗��I�v�� �v�����������������̂� �g�����Ǝv������ł����g���܂���ł����B
[�Q�l]
�yBash�z �X�N���v�g����alias�R�}���h�����s�ł��Ȃ� - takafumi blog
��{�I�� �Θb���[�h����Ȃ��ƃ_���炵���ł��B
�m���� �ʂ̃R�}���h�� alias ����Ă�����댯�ł��ˁB
watch �R�}���h�ň��Ԋu�ŃR�}���h�����s����
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
watch �R�}���h�� �w�肵���R�}���h�����Ԋu�Ŏ��s���� �o�͌��ʂ̍�����\�����Ă���܂��� ���́u���Ԋu�ŃR�}���h�����s����v�Ƃ����@�\�� ���ꂾ���ŕ֗��ł��B
���̂悤�ɂ���� 3�b���Ƃ� Web�T�[�o�ɃA�N�Z�X���܂��B
$ watch -n 3 wget -q http://localhost/hogehoge -O - > /dev/null
�J��Ԃ������Ȃ� while �Ȃǂł��ł��܂��� ���Ԋu�Ŏ��s����Ȃ� watch �R�}���h���g���̂��ȒP�ŕ֗��ł��B
Linux �� �X�g�b�v�E�H�b�`�ɂ���
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
����ȏ����邩�ǂ����킩��܂��� Linux ���g���Ă��� �X�g�b�v�E�I�b�`���K�v�ɂȂ����ꍇ�̕��@�ł��B
$ time read
���ꂾ���ł��B
�R�}���h�̎��s�ŊJ�n�A [Enter] �������Ǝ��Ԃ��o�܂��B
$ time read
real 0m4.696s
user 0m0.000s
sys 0m0.000s
bash �� �I������ �ꎞ�t�@�C���������I�ɍ폜����
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
�V�F���X�N���v�g�ō쐬���� �ꎞ�t�@�C���� �I����Ɏ����I�ɏ����܂��B
�|�C���g�� 2�_����܂��B
�@�q�v���Z�X�ō쐬�����ꎞ�t�@�C���̃p�X�� �e�v���Z�X�Ŏ擾����̂� �V�F���X�N���v�g�ł͑�ςȂ̂ŁA �ꎞ�t�@�C���͍ŏ��ɋN�������V�F���X�N���v�g�� �쐬����f�B���N�g���̔z���Ɋi�[���܂��B
�A�ŏ��ɋN�������V�F���X�N���v�g�̏I������ builtin�R�}���h�� trap �� �ꎞ�t�@�C�����폜���鏈���ifunction�j�������I�Ɏ��s���܂��B
�܂��A�ꎞ�t�@�C���p�̃f�B���N�g�����쐬���܂��B
declare -r SCRIPT_PATH=${BASH_SOURCE:-$0}
declare -r SCRIPT_NAME=$(basename "${SCRIPT_PATH}")
declare -r SCRIPT_TMP_DIR=$(mktemp -d -t "${SCRIPT_NAME}.XXXXXX")
�����������Ƃ��ɒ������₷���悤�� �V�F���X�N���v�g�̖��O��t�����f�B���N�g�����쐬���܂��B
��L�̏ꍇ ���ϐ� TMPDIR �ɏ]���� ���̂悤�ȃf�B���N�g�����ɂȂ�܂��B �iTMPDIR �� /tmp�̏ꍇ�j
/tmp/hogehhoge.sh.mBzqNx
���̒l�� ���ϐ� TMPDIR �ɃZ�b�g���܂��B
export TMPDIR=${SCRIPT_TMP_DIR}
����� �q�v���Z�X�� function�Ȃǂ� �ꎞ�t�@�C�������ۂ� mktemp �� ���ϐ� TMPDIR ���g�p����I�v�V������t���Ă����� �����f�B���N�g���� �ꎞ�t�@�C�����쐬���邱�Ƃ��ł��܂��B
���� �����I�� �ꎞ�t�@�C�����폜����d�g�݂ł��B
�ꎞ�t�@�C�����폜���ďI������ function���`���܂��B
function on_exit_event() {
local script_exit_code=${1}
rm -Rf "${SCRIPT_TMP_DIR}"
exit ${script_exit_code}
}
rm�R�}���h�̃I�v�V������ "-f" ��t���ăt�@�C�����Ȃ��Ƃ����G���[���o�Ȃ��悤�ɂ��A "-R" �ŁA�t�@�C���ł͂Ȃ��A�ꎞ�f�B���N�g�����쐬�����ꍇ���폜�ł���悤�ɂ��܂��B
����� trap �ŋN������悤�ɂ��܂��B
trap 'on_exit_event ${?}' EXIT
����� �ꎞ�t�@�C���� �ŏ��ɋN�������V�F���X�N���v�g�̏I������ �����I�ɍ폜����܂��B
�S�͎̂��̂悤�ɂȂ�܂��B
#!/usr/bin/env bash
declare -r SCRIPT_PATH=${BASH_SOURCE:-$0}
declare -r SCRIPT_NAME=$(basename "${SCRIPT_PATH}")
declare -r SCRIPT_DIR=$(cd $(dirname "${SCRIPT_PATH}"); pwd)
declare -r SCRIPT_FULL_PATH=${SCRIPT_DIR}/${SCRIPT_NAME}
declare -r SCRIPT_TMP_DIR=$(mktemp -d -t "${SCRIPT_NAME}.XXXXXX")
export TMPDIR=${SCRIPT_TMP_DIR}
function on_exis_sub_event() { :; }
function on_exit_event() {
local script_exit_code=${1}
on_exis_sub_event
rm -Rf "${SCRIPT_TMP_DIR}"
exit ${script_exit_code}
}
trap 'on_exit_event ${?}' EXIT
�i�又���j
on_exis_sub_event�� �I�����̏�����lj��������Ȃ����ꍇ�� �㏑�����邽�߂� function�ł��B �Ƃ肠���� ��Œ�`���Ă����� �K�v�ɉ����� ��ōĒ�`���܂��B
bash �� ":"(�R����) �́Abuiltin command
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
bash �̃V�F���X�N���v�g��ǂ�ł���� �Ƃ��ǂ� ":" (�R����) ���o�ꂵ�܂��B ���� ":" �� bash �� builtin �ł��B
���s����ƁA�A�A
$ :
�����Ԃ��Ă��܂��� �G���[���o�܂���B
���Ȃ݂� ";"(�Z�~�R����) ���� ���̂悤�ɃG���[���o�܂��B
$ ;
-bash: syntax error near unexpected token `;'
type �R�}���h�Ō���� builtin �ƂȂ��Ă܂��B
$ type :
: is a shell builtin
���̂悤�ɃR�����g�Ƃ��Ďg�����Ƃ��ł��܂��B
: comment comment : comment comment : comment comment
�R�}���h�v�����v�g�� REM �Ɠ����ł��ˁB
�����Ԃ��Ȃ��̂� ���̂悤�ɂ��� ��t�@�C�����쐬���邱�Ƃ��ł��܂��B
$ : > blank.log
�v���Z�X�u���Ƒg�ݍ��킹�� ���̂悤�ɂ��ċ�t�@�C�����쐬���邱�Ƃ��ł��܂��B
$ cat <(:)> blank.log
�m���Ă���Γǂ߂܂��� �m��Ȃ��ƋL���ɂ��������܂���B
bash �� �v���Z�X�u��
script �R�}���h���g�������Z�ł��B
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
bash �ɂ� �u�v���Z�X�u���v�Ƃ����@�\������܂��B
Process Substitution
Process substitution is supported on systems that support named pipes (FIFOs) or the /dev/fd method of naming
open files. It takes the form of <(list) or >(list). The process list is run with its input or output con�]
nected to a FIFO or some file in /dev/fd. The name of this file is passed as an argument to the current com�]
mand as the result of the expansion. If the >(list) form is used, writing to the file will provide input for
list. If the <(list) form is used, the file passed as an argument should be read to obtain the output of
list.
When available, process substitution is performed simultaneously with parameter and variable expansion, com�]
mand substitution, and arithmetic expansion.
�������̈ꎞ�t�@�C���̍쐬�����点��@�\�ŁA �����Ă����̕��@�ő�p�͌����̂ł��� �ǂ������Ŏg���ƃR�}���h���ǂ݂₷���Ȃ����肵�܂��B
�������́A���� 2�B
<(�R�}���h)
>(�R�}���h)
���O�̎��Ă�u�R�}���h�u���v�Ə����������Ă܂��ˁB
�R�}���h�u���ƃv���Z�X�u��
$(�R�}���h) #�R�}���h�u��
�u�R�}���h�u���v�́A�R�}���h�̌��ʂ� �R�}���h��R�}���h�̈����Ƃ��Ďg�p���邱�Ƃ��ł��܂����B
$ echo $(echo date) date
$ $(echo date) Thu Dec 8 22:58:19 JST 2018
�u�v���Z�X�u���v�́A�R�}���h�̌��ʂ� �t�@�C���̓��͂̂悤�Ɉ������� �o�͂��R�}���h�ɓn������ł��܂��B
<(�R�}���h)
�܂��� "<(�R�}���h)" �̕��ł����A�R�}���h�œ��̓t�@�C���̃p�X�� �w�肷��Ƃ���ɏ������Ƃ��ł��܂��B
�悭�g�����Ƃ��Ă�
diff �R�}���h�ł��B
diff �R�}���h�́A2�̃t�@�C�����r����ۂ�
�W���o�͂� 1�����w��ł��Ȃ�����
2�̃R�}���h�̎��s���ʂ��r�������ꍇ
��r����R�}���h�̕Е��͎��̂��K�v�ɂȂ�܂��B
$ ls -l /var/xxxx > xxxx.txt $ ls -l /var/yyyy > yyyy.txt $ diff xxxx.txt yyyy.txt
$ ls -l /var/xxxx > xxxx.txt $ ls -l /var/yyyy | diff - xxxx.txt
�u�v���Z�X�u���v���g���� �ꎞ�t�@�C�����쐬������ 2�̃R�}���h�̎��s���ʂ� ���̂܂ܔ�r���邱�Ƃ��ł��܂��B
$ diff <(ls -l /var/xxxx) <(ls -l /var/yyyy)
�R�}���h�����₷���ł��ˁB
�ꎞ�t�@�C�����폜�����Ԃ��Ȃ��Ȃ�܂��B
echo �ŏo�͂���� �u�v���Z�X�u���v�̎��̂� �t�@�C���f�X�N���v�^���Ƃ킩��܂��B
$ echo <(echo 1)
/dev/fd/63
�킩��ɂ����Ȃ�܂��� ���̂悤�Ȃ��Ƃ��ł��܂��B
$ $(cat <(echo date))
Thu Dec 8 22:14:36 JST 2018
����� �܂� ���̂悤�ɏ�������� "date" ���Ԃ��Ă��܂��B
$ echo date > /dev/fd/63 $ cat /dev/fd/63
�Ԃ��Ă��� date �����s���� �������o�͂���܂����B
$ date
Thu Dec 8 22:14:36 JST 2018
�܂� ���̂悤�� do ... done �̃��[�v�� �p�C�v�łȂ��� ���̏������ʃv���Z�X�ɂȂ� ���ϐ��� �㏑�����Ă���Ȃ��悤�ȏꍇ�A�A�A
$ filename=none $ ls | grep -v "test." | while read filepath > do > filename=$(basename $filepath) > done $ echo $filename none #���ʃv���Z�X�̂��ߏ㏑������Ȃ�
�u�v���Z�X�u���v���g���� �t�@�C�����w�肷��̂Ɠ����悤�� �����v���Z�X�ŏ������邱�Ƃ��ł��܂��B
$ filename=none $ while read filepath > do > filename=$(basename $filepath) > done < <(ls | grep -v "test.") $ echo $filename xxxxx.txt #�������v���Z�X�̂��ߏ㏑�����ꂽ
>(�R�}���h)
���� ">(�R�}���h)" �̕��ł����A������� ���������p�C�v�łł��Ă��܂����� ���܂�ǂ��Ⴊ�v�������т܂���ł����B
�悭�g���͎̂��̂悤�� �W���G���[�o�͂� �s�v�ȍs���I�~�b�g����P�[�X���ł��B
$ command 2> >(grep -v ^Notice: >&2)
����́A�W���G���[�o�͂���U �v���Z�X�u���� grep �R�}���h�ɓn���� "Notice:" ���� �n�܂�s���Ȃ��āA�ēx�W���G���[�o�͂ɓn���Ă��܂��B
���ɂ� tee �R�}���h�Ƒg�ݍ��킹�� ����̏o�͂����U�蕪���� �Ȃ�Ă��Ƃ��ł��܂��B
$ cat test.txt | \ > tee >(grep ^case1 > case1.txt) \ > tee >(grep ^case2 > case2.txt) \ > tee >(grep ^case3 > case3.txt) \ > > /dev/null
���̗�ł́A�o�͂��ꂽ�s�̐擪�̕����ɂ���� �ʂ̃t�@�C���ɕۑ����Ă��܂��B
script �R�}���h�ŁA�ʂ̒[���̑�������j�^�����O����
script �R�}���h���g�������Z�ł��B
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
script �R�}���h�� ��Ƃ̃��O���Ƃ��Ă����֗��ȃR�}���h�ł��� ���̃R�}���h�𗘗p����� �ʂ̒[���̑�������j�^�����O���邱�Ƃ��ł��܂��B
�[�� A
���삷�鑤�� �[�� A �ł́A
script �R�}���h��
"-f" �I�v�V�����t���Ŏ��s���܂��B
$ script -f /tmp/test.log
-f, --flush run flush after each write
"-f" �� �����Ƀ��O�ɏo�͂��邽�߂̃I�v�V������ �ڑ����ꂽ�ꍇ�ɂ����S�̃I�v�V�����ł��B
�[�� B
���j�^�����O���鑤�� �[�� B �ł́A
tail �R�}���h��
"-f" �I�v�V�����t����
���s���A
�[�� A ��
script �R�}���h�̃��O���Q�Ƃ��܂��B
$ tail -f /tmp/test.log
���̏�Ԃ� �[�� A �ő��������� �[�� B �̃R���\�[���ɂ��������e���o�͂���܂��B
�_�u���`�F�b�N�� �w������ꍇ�Ȃǂɕ֗����Ǝv���܂��B
�� �ԈႦ�� "script -f" �����s���� �[�� A �� script �R�}���h�� ���O�t�@�C���� "tail -f" �ŊJ���Ă��܂��� �������[�v�ɓ����Ă��܂��̂Œ��ӂ��Ă��������B
�����t�@�C�������� tar �R�}���h�Ōł߂�
�����ł��B
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
find �R�}���h�Ŏ擾�����X�V�����V�����t�@�C�������� tar �R�}���h�� �ł߂���@�ł��B
�X�V���́A��r�Ώۂ̃t�@�C�����V�������̂��擾���܂��B �i���̕��@�ɂ��ẮA�O�ɏ����Ă����̂ŁA��������Q�Ƃ��Ă��������j
�܂��͊��ϐ��̐ݒ�B
��r�Ώۂ̃t�@�C���iBASE_FILE_PATH�j��
�ł߂�TAR�t�@�C���iTAR_FILE_PATH�j�̃p�X��ݒ肵�܂��B
$ BASE_FILE_PATH=./last_update.txt $ TAR_FILE_PATH=/tmp/xxxxxx
������TAR�t�@�C�������݂���Ƃ�낵���Ȃ����� �O�̂��߂ł����A0�o�C�g�ŏ㏑�����Ă����܂��B
$ cat /dev/null > ${TAR_FILE_PATH}.tar
find �R�}���h�Ńt�@�C�����擾���� tar �R�}���h�Ōł߂܂��B ���̂Ƃ��Atar �R�}���h�ł� �NjL "r" ���w�肷��̂� ���k�� "z" �͎w�肵�Ȃ��悤�ɂ��܂��B
$ find ./ -type f -newer ${BASE_FILE_PATH} -exec tar rf ${TAR_FILE_PATH}.tar {} \;
TAR �{�[�����������ň��k���܂��B
$ gzip -f ${TAR_FILE_PATH}.tar
�Ō�ɔ�r�Ώۂ̃t�@�C���� touch �R�}���h�ōX�V���Ă����� �������̌ォ��̍������擾���邱�Ƃ��ł��܂��B
$ touch ${BASE_FILE_PATH}
find �R�}���h�œ������w�肵�Č��o����
�����ł��B
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
find �R�}���h�� -mtime �I�v�V�������g���� �t�@�C���̍X�V���������ɂ��āu�`���O�v�̂悤�Ȍ��o���ł��܂��B
$ find ./ -mtime -3
��̓I�ɓ������w�肵�Č��o����ɂ� ���̂悤�� -newermt �I�v�V�������g�p���܂��B �i-newermt �� m �� Modify �� m �ŁAa �ɂ���� Access�Ac ���� Change �ɂȂ�܂��j
$ find ./ -newermt "2018/10/30 12:00"
�i���t�̏����͐F�X�w��ł��܂��j
����Ŏw�肵�����������^�C���X�^���v���傫���i�w�肵�������͊܂܂�Ȃ��j�t�@�C�������o���邱�Ƃ��ł��܂��B
-newerXY reference
Compares the timestamp of the current file with reference. The reference argument is normally the name
of a file (and one of its timestamps is used for the comparison) but it may also be a string describing
an absolute time. X and Y are placeholders for other letters, and these letters select which time
belonging to how reference is used for the comparison.
a The access time of the file reference
B The birth time of the file reference
c The inode status change time of reference
m The modification time of the file reference
t reference is interpreted directly as a time
Some combinations are invalid; for example, it is invalid for X to be t. Some combinations are not
implemented on all systems; for example B is not supported on all systems. If an invalid or unsup�]
ported combination of XY is specified, a fatal error results. Time specifications are interpreted as
for the argument to the -d option of GNU date. If you try to use the birth time of a reference file,
and the birth time cannot be determined, a fatal error message results. If you specify a test which
refers to the birth time of files being examined, this test will fail for any files where the birth
time is unknown.
find �R�}���h�œ���̃t�@�C���ȍ~�̍X�V�����o����
�����ł��B
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
find �R�}���h�� -mtime �I�v�V�������g���� �t�@�C���̍X�V���������ɂ��āu�`���O�v�̂悤�Ȍ��o���ł��܂��B
$ find ./ -mtime -3
�����̍�ƂōX�V�����t�@�C���ȍ~�ɍ쐬�E�X�V���ꂽ�t�@�C�������o�������ꍇ -newer �Ƃ����I�v�V�������g���܂��B
$ find ./ -newer hogehoge.txt
-newer file
File was modified more recently than file. If file is a symbolic link and the -H option or the -L
option is in effect, the modification time of the file it points to is always used.
���̃I�v�V�����́A�����̃t�@�C���̃^�C���X�^���v���^�C���X�^���v���V�����t�@�C�������o���Ă���܂��B
�����̃t�@�C���̃^�C���X�^���v�g���傫���h���߁A���̃t�@�C�����̂͊܂܂�܂���B �����̃t�@�C�����Ώۂ̒��ɂ����Ă��A���o����Ȃ��悤�ɂȂ��Ă�킯�ł��B �悭�l�����Ă܂��ˁB
tar �R�}���h�Ńp�X��ύX���ēW�J������
�����ł��B
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
tar �R�}���h�œW�J����Ƃ��� �i�[����Ă���p�X�����̂܂g������ �p�X�̈ꕔ��ύX���ēW�J�������Ƃ�������܂��B
[�i�[�������p�X] home/hogehoge/test1/xxxxxx [�W�J�������p�X] /home/hogehoge/test2/xxxxxx
���̂悤�ɃI�v�V�����ƕύX���e���w�肷�邱�ƂŁA �p�X��ύX���Ȃ���W�J���邱�Ƃ��ł��܂��B
$tar xzvf xxxxx.tar.gz --transform='s/test1/test2/g'
File name transformations:
--transform=EXPRESSION, --xform=EXPRESSION
use sed replace EXPRESSION to transform file
names
�f�B���N�g���́u / �v���ύX�������ꍇ�� ���̂悤�ɋ�蕶�����u | �v�ȂǂɕύX���Ă����Ɨǂ��Ǝv���܂��B
$tar xzvf xxxxx.tar.gz --transform='s|hogehoge/test1|hugahuga/test2|g'
tar �R�}���h�ňꕔ������W�J������
�����ł��B
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
tar �R�}���h�œW�J����Ƃ��� ����̃t�@�C����A����̃f�B���N�g���ȉ��̃t�@�C��������W�J�������Ƃ�������܂��B
���̂悤�Ƀp�X���w�肷�邱�ƂŁA���̃t�@�C��������W�J���邱�Ƃ��ł��܂��B
$ tar xvzf xxxxx.tar.gz home/hogehoge/test.html
���l�ɁA�f�B���N�g���̃p�X���w�肷��ƁA���̃f�B���N�g���ȉ���W�J�ł��܂��B
$ tar xvzf xxxxx.tar.gz home/hogehoge
�p�X�̎w��ɂ̓��C���h�J�[�h���g�����Ƃ��ł��܂��B
$ tar xvzf xxxxx.tar.gz --wildcards */hogehoge.png
File name matching options (affect both exclude and include patterns):
--wildcards use wildcards (default for exclusion)
--no-wildcards verbatim string matching
�]�k�ł����ATAB�L�[�̓��͕⊮�� .tar.gz �t�@�C���̒��̃p�X�܂� �w��ł��ăr�b�N�����܂����B
Bash �̃G���[�������ɏI������I�v�V����
�ʏ�ABash �̏����� �G���[���������Ă����̃X�e�b�v�ւ� �i��ōs���܂��B
[test1.sh]
true
echo 1=$?
false
echo 2=$?
true
echo 3=$?
false
echo 4=$?
$ bash test1.sh
1=0
2=1
3=0
4=1
�G���[�����������Ƃ��Ɏ~�߂�ɂ� �I�v�V���� "-e" ��t���܂��B
$ bash -e test1.sh 1=0
�܂��A�p�C�v���Ă���ꍇ �Ō�̃R�}���h�̌��ʂ��Ԃ�܂��B
[test2.sh]
true | true
echo 1=$?
true | false | true
echo 2=$?
false | true
echo 3=$?
true | false
echo 4=$?
$ bash test2.sh
1=0
2=0
3=0
4=1
����ɃI�v�V���� "-e" ��t���Ď��s���Ă�
$ bash -e test1.sh 1=0 2=0 3=0
�Ō�̃R�}���h�Ŕ������Ă���G���[���� �������Ă���܂���B
���̂悤�ȂƂ��� ����� �I�v�V���� "-o pipefail" ���w�肵�܂��B
$ bash -e -o pipefail test1.sh 1=0
����Ńp�C�v���̃G���[���Ԃ�悤�ɂȂ�܂��B
Bash �̖���`�̕ϐ����`�F�b�N����I�v�V����
Bash �ɂ� �v���O��������̂悤�� ����`�̕ϐ����`�F�b�N�ł��� �I�v�V���� "-u" ������܂��B
���̃I�v�V�������w�肵�Ă���� ����`�̕ϐ����o�Ă����Ƃ���� �G���[�ɂ��Ă���܂��B
�����Ă݂܂��B
[test.sb]
A=a
C=c
echo A=$A
echo B=$B
echo C=$C
�܂��͕��ʂɎ��s�B
$ bash test.sh A=a B= C=c $ echo $? 0
�ϐ� B ������`����Ă��Ȃ��̂Œl����ł��B
���ɃI�v�V������t���Ď��s�B
$ bash -u test.sh A=a test.sh: line 4: B: unbound variable $ echo $? 1
�r���ŃG���[�ɂȂ�܂����B ���S�ł��ˁB
���̃I�v�V�������l set �R�}���h�Ȃǂł��w��ł��܂��B
Bash �̎��s���e�̃g���[�X�̃I�v�V����
Bash �ɂ� �����̎��s���e���g���[�X�ł��� �f�o�b�O�ɕ֗��� �I�v�V���� "-x" �� "-v" ������܂��B
���@�`�F�b�N�� "-n" �Ɠ����l�� �F�X�ȕ��@�Ŏw��ł��܂��B
$ bash -xv test.sh
#!/bin/bash -xv
set -xv
���Ȃ݂ɁA�I�v�V���� "-x" �͎��s���ꂽ���e���o�͂� �I�v�V���� "-v" �͎��s����ȃR�}���h���o�͂��܂��B
���̃V�F���X�N���v�g�Ŏ����Ă݂܂��B
[test.sh]
YESTERDAY=$(date --date "1 day ago")
echo $YESTERDAY
�܂����ʂɎ��s�B
$ bash test.sh
Sun Oct 1 21:55:13 JST 2017
�܂� �I�v�V���� "-x" �������w��B
$ bash -x test.sh ++ date --date '1 day ago' + YESTERDAY='Sun Oct 1 21:55:23 JST 2017' + echo Sun Oct 1 21:55:23 JST 2017 Sun Oct 1 21:55:23 JST 2017
�lj��ŏo�͂��ꂽ�s�̐擪�� "+" �� "++" ���t���Ă܂��B
"++" �� "$()" �Ŏ��s���ꂽ�����ł��ˁB
�ϐ����l�ɓ]������Ă��܂��B
���� �I�v�V���� "-v" �������w��B
$ bash -v test.sh YESTERDAY=$(date --date "1 day ago") date --date "1 day ago" echo $YESTERDAY Sun Oct 1 21:55:28 JST 2017
������� "+" �Ȃǂ͕t�����A�ϐ������̂܂܂ł��ˁB
"$()" �̎��s���肾����Ă��܂��B
����� �I�v�V���� "-x" "-v" �𗼕��w��B
$ bash -xv test.sh YESTERDAY=$(date --date "1 day ago") date --date "1 day ago" ++ date --date '1 day ago' + YESTERDAY='Sun Oct 1 21:55:44 JST 2017' echo $YESTERDAY + echo Sun Oct 1 21:55:44 JST 2017 Sun Oct 1 21:55:44 JST 2017
���s����R�}���h�A���s���e���S�ďo�͂���܂����B
�܂� �I�v�V���� "-x" "-v" �̎w����������ɂ� �I�v�V���� "+x" "+v" ���w�肵�܂��B
$ set -x $ YESTERDAY=$(date --date "1 day ago") ++ date --date '1 day ago' + YESTERDAY='Sun Oct 1 22:06:42 JST 2017' $ echo $YESTERDAY + echo Sun Oct 1 22:06:42 JST 2017 Sun Oct 1 22:06:42 JST 2017 $ set +x + set +x $ YESTERDAY=$(date --date "1 day ago") $ echo $YESTERDAY Sun Oct 1 22:06:57 JST 2017 $ set -v $ YESTERDAY=$(date --date "1 day ago") YESTERDAY=$(date --date "1 day ago") date --date "1 day ago" $ echo $YESTERDAY echo $YESTERDAY Sun Oct 1 22:07:09 JST 2017 $ set +v set +v $ YESTERDAY=$(date --date "1 day ago") $ echo $YESTERDAY Sun Oct 1 22:07:20 JST 2017
���@�`�F�b�N�̃I�v�V���� "-n" �� "-v" ��g�ݍ��킹��� ���s�����ɁA���s���e�������m�F���邱�Ƃ��ł��܂��B
$ bash -nv test.sh YESTERDAY=$(date --date "1 day ago") echo $YESTERDAY
Bash �� ���@�`�F�b�N�̃I�v�V����
Bash �ɂ� ���������s������ ���@�̃`�F�b�N���������Ă����I�v�V���� "-n" ������܂��B
[test.sh]
if [ -z test.txt ]; then
echo "OK"
endif
$ bash -n test.sh test.sh: line 4: syntax error: unexpected end of file
���̃I�v�V������t���邱�Ƃ�
�R�}���h�����s������
���@�������`�F�b�N���Ă���܂��B
�i�t�ɃR�}���h�̎��s�Ȃǂ̓`�F�b�N�ł��܂���j
���̎�� Bash �̃I�v�V�����̎w����@�� ����������܂��B
�@bash �R�}���h�̈������Ɏw�肷��B
$ bash -n test.sh
�A�X�N���v�g�̐擪�ɋL�ڂ���B
#!/bin/bash -n
�Bset �R�}���h�Ŏw�肷��B
set -n
�X�N���v�g�̋N���������m�F�������Ƃ��Ȃ� �F�X�Ɖ��p�ł��܂��B
Bash �Ń��[�v��ʃv���Z�X�ɂ��Ȃ�
Bash �ňȉ��̂悤�ȃ��[�v������������ �p�C�v�ȍ~���ʃv���Z�X�ɂȂ��Ă��܂����� ���̒��Őݒ肵���ϐ����A���[�v�����̊O�ŎQ�Ƃ��邱�Ƃ��ł��܂���B
cat test1.txt | while read val1 val2
do
val3=$val1
done
echo $val3 # ���Ō��val1�͓����Ă��Ȃ�
�P���Ƀe�L�X�g����ǂݍ��ޏꍇ ���̂悤�ɏ����� �ʃv���Z�X����炸�ɍςނ��� ���[�v�̒��Őݒ肵���ϐ��� ���[�v�̊O�ŎQ�Ƃ��邱�Ƃ��ł��܂��B
while read val1 val2
do
val3=$val1
done < test1.txt
echo $val3 # ���Ō��val1�������Ă���
�R�}���h�̎��s���ʂ����[�v�� �n���Ă���ꍇ���E�E�E
cat test1.txt | grep -v "^a" | while read val1 val2 do val3=$val1 done echo $val3 # ���Ō��val1�͓����Ă��Ȃ�
���悤�ȏ����������邱�Ƃ��ł��܂��B
while read val1 val2
do
val3=$val1
done < <(cat test1.txt | grep -v "^a")
echo $val3 # ���Ō��val1�������Ă���
�i "<" �̌�̋ɒ��ӂ��Ă��������j
�v���O�����I�ȏ������K�v�ȂƂ��� ������܂��B
Linux �Ńv���Z�X�̊��ϐ����m�F����
�ȑO�APostgreSQL �̃p�X���[�h��
���ϐ��Őݒ肷��L���������܂�����
PostgreSQL �I�ɂ͔��̂悤�ł��B
�i�ꕔ�̃I�y���[�e�B���O�V�X�e���ł�root�ȊO�̃��[�U�Ŋ��ϐ���������ꍇ���邽�߂Ƃ̂��Ɓj
[�Q�l]
���ϐ� - PostgreSQL 9.3.2����
�ꕔ�̃I�y���[�e�B���O�V�X�e�����ǂ���w���̂��킩��܂��A �v���Z�X���g���Ă���ϐ��̌������C�ɂȂ����̂� ������Ɗm�F���Ă݂܂����B
�܂����ϐ���ݒ肵�܂��B
$ export PGPASSWORD=testpassword
PostgreSQL �̃f�[�^�x�[�X�ɐڑ�����v���Z�X���쐬���܂��B
$ psql -U testuser -d testdb
psql (9.3.10, server 9.3.12)
Type "help" for help.
testdb=#
[Ctrl]+[z] �v���Z�X�点�܂��B
[1]+ Stopped psql -U testuser -d testdb
�N�����̃v���Z�X���m�F���܂��B
$ ps PID TTY TIME CMD 28796 pts/0 00:00:00 bash 29754 pts/0 00:00:00 psql 29834 pts/0 00:00:00 ps
�Q�l�T�C�g�ɂ��ƁA���ϐ��́u/proc/%{PID}/environ�v�� �i�[����Ă��邻���ł��B
[�Q�l]
Linux/Unix�v���Z�X�N�����̊��ϐ����_���v���� | �M�[�N��ڎw����
�m�F���Ă݂܂��B
$ cat /proc/29754/environ | sed -e 's/\x0/\n/g' | grep PGPASSWORD PGPASSWORD=testpassword
�������Ɋm�F�ł��܂����B
�g�p���Ă�����ł� root ���[�U�łȂ���� �����ȊO�̊��ϐ��͌���܂���ł������A �����̊��ϐ����iroot�̌������g����A���̃v���Z�X�̊��ϐ����j�m�F���������Ƃ�����Ǝv���̂� �o���Ă����Ɨǂ��̂�������܂���B
���C���h�J�[�h�œ���̃t�@�C�����������O����
�ʏ�A���C���h�J�[�h���g���� �ȉ��̂悤�ɂȂ�Ƃ�����E�E�E�B
$ ls -1 *.txt
1-1.txt
1-2.txt
2-1.txt
2-2.txt
3-1.txt
"!" ���g�����ƂŁA�t�ɏ��O���邱�Ƃ��ł��܂��B
$ ls -1 !(*-2.txt)
1-1.txt
2-1.txt
3-1.txt
���̗�ł́u*-2.txt�v�Ƀ}�b�`���Ȃ��t�@�C���� �\������܂����B
tail �R�}���h�Ńt�@�C�����č쐬����Ă��ǂ�������
tail �R�}���h�� "-f" �I�v�V������ "--follow=descriptor" �Ƃ������Ƃ� �Ώۂ̃t�@�C�����č쐬�����ƒǂ��������Ȃ��Ȃ�܂��B
$ tail -f test.txt
���������Ƃ��́A"--follow=name" �� "-F" ���g���܂��B
$ tail -F test.txt
-f, --follow[={name|descriptor}]
output appended data as the file grows;
-f, --follow, and --follow=descriptor are
equivalent
-F same as --follow=name --retry
$ tail -F test.txt Fri Sep 9 12:14:01 JST 2017 Fri Sep 9 12:14:02 JST 2017 tail: 'test.txt' has become inaccessible: No such file or directory tail: 'test.txt' has appeared; following end of new file Fri Sep 9 12:14:12 JST 2017 Fri Sep 9 12:14:13 JST 2017
���Ȃ݂� �t�@�C�����č쐬�����Ə�̂悤�ɕ\������܂��B
Linux �̃p�X��W�J���� glob
�t�@�C����f�B���N�g���𑀍삷��Ƃ��� "*" �� "?" �Ȃǂ̃��C���h�J�[�h���g���܂��� ���ꂪ���ɂ���Ē�`����Ă���̂��� �l�������Ƃ�����܂���ł����B
����A Linux �ł� glob �Ƃ������O�������ł��B
[�Q�l]
Dev Basics�^Keyword�Fglob�i�O���u�j - ��IT
�L����ǂ�ŋ������̂� Linux �ł͕����N���X�i[0-9a-z]�݂����Ȃ�j���g����Ƃ̂��ƁB Windows �̃R�}���h�v�����v�g�ł͎g���Ȃ����� ���C���h�J�[�h�������Ǝv������ł܂����B
$ ls -1 /var/log/vsftpd.log* /var/log/vsftpd.log /var/log/vsftpd.log.1 /var/log/vsftpd.log.2 /var/log/vsftpd.log.3 /var/log/vsftpd.log.4 $ ls -1 /var/log/vsftpd.log.? /var/log/vsftpd.log.1 /var/log/vsftpd.log.2 /var/log/vsftpd.log.3 /var/log/vsftpd.log.4 $ ls -1 /var/log/vsftpd.log.[2-3] /var/log/vsftpd.log.2 /var/log/vsftpd.log.3 $ ls -1 /var/log/vsftpd.log.[^3-5] /var/log/vsftpd.log.1 /var/log/vsftpd.log.2
���[��A����͕֗��B
���������͓̂�����O�߂��āA �m���Ă�l�́u���̐l���m���Ă�v�Ǝv���� �킴�킴�`���Ȃ����̂Ȃ̂�������Ȃ��ł��ˁB
���Ȃ݂ɁA�t�@�C�����R�s�[����Ƃ��ɂ悭�g�� {} �̓W�J�� glob �̎d���������ł��B
$ ls -1 /var/log/syslog* /var/log/syslog $ cp -p /var/log/syslog{,.keep} $ ls -1 /var/log/syslog* /var/log/syslog /var/log/syslog.keep
find �̓��t�����̊����
find �� "-mtime" �Ȃǂ̓��t������ �I�v�V�����͕֗��ł��� �R�}���h�̎��s�������_�� ������i��������24���Ԉȓ��Ȃǁj�ɂȂ邽�� ��₱���������肷�邱�Ƃ�����܂��B
�P�[�X�ɂ����܂����A
���t������
�֗��ȃI�v�V������
"-daystart" ������܂��B
�g�����͊ȒP�B�t���邾���B
$ find . -daystart -mtime -3
"-daystart" �� "-mtime" �Ȃǂ���ɏ����܂��B
���̃I�v�V�����ŁA���t�����̊��00��00���ɂȂ邽�� ���ݎ����ł͂Ȃ��A���t�P�ʂōl���邱�Ƃ��ł���悤�ɂȂ�܂��B
date �R�}���h�ŁA���t�̏����ϊ�
���l�^�B
$ date -d "2017/3/4 1:15" +"%Y/%m/%d %H:%M"
2017/03/04 01:15
date �R�}���h�� ���t�������^���� �o�͂̏������w�肷��A������0�l�߂��ȒP�B
Linux �����̌��̃h�b�g�ɂ���
Redhat7.2��G���Ă��āA����H�Ǝv���܂����B
$ ls -l -rw-r--r--. 1 root root 108 9�� 25 2015 xxxxxxxxxxx
ls ����ƁA�����̌��Ƀh�b�g���t���Ă��܂����B
���ׂĂ݂�ƁA���̃h�b�g�́uSELinux�̃Z�L�����e�B�R���e�L�X�g���ݒ肳��Ă����v�Ƃ̂��ƁB
[�Q�l]
RHEL6�ŁAls -l �ł������Ɍ����̌���".�i�h�b�g�j"���t���A�t���Ȃ��͉����Ӗ����Ă�H - Qiita
ls �� "-Z" �t���Ă݂�ƁA�Z�L�����e�B�R���e�L�X�g���\�������悤�ł��B
-Z, --context Display security context so it fits on most
displays. Displays only mode, user, group,
security context and file name.
$ ls -Z -rw-r--r--. root root system_x:object_x:system_xxxx:s0 xxxxxxxxxxx
�F�X�ƒm��Ȃ����Ƃ�������Ȃ��A�Ƃ����b�B
test �R�}���h�� -v �I�v�V����
Bash �V�F�������s����Ƃ��� ���ϐ��̐ݒ�̗L�����m�F���Ă���̂ł��� ��{������Ȃ̂ŁA�p�b�ƌ���������Ղ� ���̂悤�ȏ��������悭���Ă��܂����B
if [ "${VAR_XXXXX}" = "" ]; then
echo "���ϐ������ݒ�"
�l���K�{�������̂ŁA�ǂ������̂ł��� ���܂��ܔz����g�����ƂɂȂ�A ����������������Ɩ��ݒ�Ƀ}�b�`���Ă��܂��܂����B
���ׂĂ݂�ƍŋ߂� test �R�}���h�� -v �I�v�V���������� �ϐ��̒�`�̗L�����`�F�b�N�ł���Ƃ��B
if [ ! -v VAR_XXXXX ]; then echo "���ϐ������ݒ�"
����ŃC�P�܂����B
�܂����͑I�Ԃ悤�ł����A�����ڂ��킩��₷���ėǂ��ł��ˁB
Ubuntu14.04 �ŁAsendmail �̃I�v�V�������g���Ȃ��Ȃ��Ă��b
�O���ɑ����AUbuntu14.04 �����ł��B
Ubuntu10.04 �ł́A�ȉ��̂悤�� mail �R�}���h�� sendmail �̃I�v�V�������g�p�ł��Ă��܂����B
MAIL(1) BSD General Commands Manual MAIL(1)
NAME
mail, mailx, Mail �\ send and receive mail
SYNOPSIS
mail [-dEIinv] [-a header] [-b bcc-addr] [-c cc-addr] [-s subject] to-addr ... [-- sendmail-options ...]
mail [-dEIiNnv] -f [file]
mail [-dEIiNnv] [-u user]
�n�C�t�� 2 �t���Ĉȉ��̂悤�ɂ��Ă��܂����B
$ mail -s "subject" to@xxx -- -f from@xxx
Ubuntu14.04 �ł́Asendmail �̃I�v�V������ �w��ł��Ȃ��Ȃ��Ă��܂����B �i�w�肷��ƁA���M��̃A�h���X�Ɣ��肳��Ă��܂��܂��j
MAILX(1) User Commands MAILX(1)
NAME
mailx - send and receive Internet mail
SYNOPSIS
mailx [-BDdEFintv~] [-s subject] [-a attachment ] [-c cc-addr] [-b bcc-addr] [-r from-addr] [-h hops]
[-A account] [-S variable[=value]] to-addr . . .
mailx [-BDdeEHiInNRv~] [-T name] [-A account] [-S variable[=value]] -f [name]
mailx [-BDdeEinNRv~] [-A account] [-S variable[=value]] [-u user]
�O���̘b�̂悤�� bsd-mailx ���� heirloom-mailx �� �ւ�������炩�Ǝv�� mail �R�}���h�� bsd-mailx �ɖ߂��Ă݂܂����B
$ sudo update-alternatives --config mailx
There are 3 choices for the alternative mailx (providing /usr/bin/mailx).
Selection Path Priority Status
------------------------------------------------------------
* 0 /usr/bin/heirloom-mailx 60 auto mode
1 /usr/bin/bsd-mailx 50 manual mode
2 /usr/bin/heirloom-mailx 60 manual mode
3 /usr/bin/mail.mailutils 30 manual mode
Press enter to keep the current choice[*], or type selection number: 1
update-alternatives: using /usr/bin/bsd-mailx to provide /usr/bin/mailx (mailx) in manual mode
������ ��͂�Asendmail �̃I�v�V������ �Ȃ��Ȃ��Ă��܂����B
MAIL(1) BSD General Commands Manual MAIL(1)
NAME
mail, mailx, Mail �\ send and receive mail
SYNOPSIS
mail [-dEIinv] [-a header] [-b bcc-addr] [-c cc-addr] [-s subject] to-addr ...
mail [-dEIiNnv] -f [file]
mail [-dEIiNnv] [-u user]
���Ȃ݂� Ubuntu14.04 �� heirloom-mailx �ł́A���M���͈ȉ��̂悤�Ɏw�肵�܂��B
$ mail -s "subject" -r from@xxx to@xxx
Ubuntu14.04 �ŁA�W�����[���� heirloom-mailx �ɂȂ��Ă��b
Ubuntu14.04 �ł̘b�ł��B
mail �R�}���h�̃V���{���b�N�����N��ǂ��Ă����܂��B
$ readlink -f `which mail` /usr/bin/heirloom-mailx
heirloom-mailx �ł��B
Ubuntu10.04 �ł́Absd-mailx �ł����B
$ readlink -f `which mail` /usr/bin/bsd-mailx
�����̃��[���p�b�P�[�W�����Ă���ꍇ�� update-alternatives �R�}���h�� ��ւ��邱�Ƃ��ł��܂��B
$ sudo update-alternatives --config mailx There are 3 choices for the alternative mailx (providing /usr/bin/mailx). Selection Path Priority Status ------------------------------------------------------------ * 0 /usr/bin/heirloom-mailx 60 auto mode 1 /usr/bin/bsd-mailx 50 manual mode 2 /usr/bin/heirloom-mailx 60 manual mode 3 /usr/bin/mail.mailutils 30 manual mode Press enter to keep the current choice[*], or type selection number:
LC_ALL �� LANG ��ݒ肵�����̈Ⴂ
������ƋC�ɂȂ����̂Ń����B ���� Ubuntu14.04 �ł��B
�ݒ肷��O�B
$ locale
LANG=en_US.UTF-8
LANGUAGE=en_US:en
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
LC_ALL �� C ��ݒ肵���ꍇ�B
$ env LC_ALL=C locale LANG=en_US.UTF-8 LANGUAGE=en_US:en LC_CTYPE="C" LC_NUMERIC="C" LC_TIME="C" LC_COLLATE="C" LC_MONETARY="C" LC_MESSAGES="C" LC_PAPER="C" LC_NAME="C" LC_ADDRESS="C" LC_TELEPHONE="C" LC_MEASUREMENT="C" LC_IDENTIFICATION="C" LC_ALL=C
LANG �� C ��ݒ肵���ꍇ�B
$ env LANG=C locale LANG=C LANGUAGE=en_US:en LC_CTYPE="C" LC_NUMERIC="C" LC_TIME="C" LC_COLLATE="C" LC_MONETARY="C" LC_MESSAGES="C" LC_PAPER="C" LC_NAME="C" LC_ADDRESS="C" LC_TELEPHONE="C" LC_MEASUREMENT="C" LC_IDENTIFICATION="C" LC_ALL=
LC_ALL �ɐݒ肵���ꍇ�� LANG �͕ς��܂���ł����B
�R�}���h�̌��ʂ�2�s�ڈڍs���\�[�g����
1�s�ڂɃw�b�_�[���o�͂����R�}���h�̌��ʂ� 2�s�ڈȍ~�݂̂��\�[�g���悤�Ǝv���ė͋Z�B
$ df -T | sed '1d' | sort
sed �� 1�s�ڂ��폜���Ă��܂��B
�ŁA�w�b�_�[�s��lj��B
$ (df -T | head -n 1) && (df -T | sed '1d' | sort)
Filesystem Type 1K-blocks Used Available Use% Mounted on
/dev/sda1 ext3 19091584 2018084 16097016 12% /
none tmpfs 102400 0 102400 0% /run/user
none tmpfs 16432604 0 16432604 0% /run/shm
none tmpfs 4 0 4 0% /sys/fs/cgroup
none tmpfs 5120 0 5120 0% /run/lock
tmpfs tmpfs 3286524 844 3285680 1% /run
udev devtmpfs 16421864 4 16421860 1% /dev
netstat ���[�e�B���O����\������
�m��Ȃ��I�v�V�����������̂ŁA�����B
$ netstat -r
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
localnet * 255.255.255.0 U 0 0 0 eth0
default 192.168.1.1 0.0.0.0 UG 0 0 0 eth0
2�̃R�}���h�̏o�͂�1�ɂ܂Ƃ߂�
�����������Ƃł͂Ȃ��̂ł����B
�R�}���h�̌��ʂɃw�b�_�[��t������������ł��� cat �łł��������H�ǂ����悤���ƍl���Č��ʗ͋Z�B
$ (echo "MByte Directory") && (du -sm /home /opt /tmp /var)
MByte Directory
1 /home
1 /opt
87 /tmp
2 /var
�R�}���h���J�b�R�ň͂�� && �łȂ�����ł��܂����B
Linux �ŃO���[�v�Ƀ��[�U��lj�����
Linux �Ń��[�U��lj�������@�͂�������܂��� usermod ���g���ꍇ�͒��ӂ��K�v�ł��B
$ usermod -aG "�O���[�v��" "���[�U��"
���̂Ƃ��A"-G" �������ƌ��݂̐ݒ肳��Ă���O���[�v�������Ă��܂��̂� "-aG" �̂悤�� "a" ��t���Y��Ȃ��悤�ɂ��܂��B
gpasswd �Ƃ����R�}���h���g�����@������܂��B
$ gpasswd -a "���[�U��" "�O���[�v��"
���̃R�}���h�́A�O���[�v�𑀍삷��R�}���h�Ȃ̂� �O���[�v�����Ō�ɗ��邱�Ƃɒ��ӂ��܂��B ���[�U���́A"-a" �I�v�V�����̈������ɂȂ�܂��B
�ǂݎ���p�ŊJ�� view �R�}���h
vi �ŊJ���������� �㏑�����Ă��܂��ƕ|���� �Ƃ����Ƃ��� �ǂݎ���p�� vi ���J�� view �Ƃ����R�}���h������܂��B
�J���Ƃ��� vi �Ɠ����ł��B
$ view test.txt
����Ȃ� ������ƈ��S�Ɏg���܂��ˁB
���Ȃ݂� �ǂݎ���p�ŊJ���܂��� :w! �̂悤�Ɋ��Q���t�����Ə㏑���ł��܂��B
touch �R�}���h�ő��ΓI�ȓ��t���w�肷��
�T�[�o�̃o�b�`�����Ȃ�����Ă���ƁA �u����̃^�C���X�^���v�̃t�@�C���v�� �~�����Ȃ�Ƃ�������܂��B
touch �R�}���h�œ��t���w�肵����A ���̃t�@�C�������� �^�C���X�^���v��ݒ肷�邱�Ƃ͂ł��܂��� �������g�������ΓI�Ȏw�肾�� �ȒP�ɐݒ肷�邱�Ƃ��ł��܂��B
$ touch -d "1 day ago" test.txt
ago ����Ȃ��ĕ��ł� OK �ł��B
$ touch -d "-1 hour" test.txt
�����w��ł��܂��B
$ touch -d "-2 day -1 hour" test.txt
���̗Ⴞ�ƍ��v���� 4 ���O�ɂȂ�܂��B
$ touch -d "-2 day -2 day" test.txt
���̕����̑��Ύw��́A date �R�}���h�ł��g�p�ł���̂� ���O�ɂǂ��Ȃ邩�m�F���邱�Ƃ��ł��܂��B
$ date -d "-2 day -2 hour"
seq �Ƃ����֗����ۂ��R�}���h
�ȉ��̋L����ǂ�ŁAseq �Ȃ�ăR�}���h������E�E�E�Ǝv�����̂Ń����B
[�Q�l]
seq�R�}���h���ƂĂ��֗��������� - �ԂĂ��̃��O�łԃ��O
�����Ă݂܂��傤�B
$ seq 3
1
2
3
�ǂ��ł��ˁB
�J�n�I�����w��ł���悤�ł��B
$ seq 2 5
2
3
4
5
���Z���ł���݂����ł��B
$ seq 10 -2 5
10
8
6
���ɂ��������낦����A��蕶����ς�����i�f�t�H���g�͉��s�j�A�������w�肵����ł���悤�ł��B
$ seq -s, 2 8 2,3,4,5,6,7,8 $ seq -w 9 12 09 10 11 12 $ seq -f "%03g" 2 4 002 003 004
����Ȏg�������B�i2�����Ƃ̓��t���j
$ for i in `seq 0 2 30`; do date +"%Y-%m-%d (%a)" -d "$i day"; done; 2015-08-26 (Wed) 2015-08-28 (Fri) 2015-08-30 (Sun) 2015-09-01 (Tue) 2015-09-03 (Thu) 2015-09-05 (Sat) 2015-09-07 (Mon) 2015-09-09 (Wed) 2015-09-11 (Fri) 2015-09-13 (Sun) 2015-09-15 (Tue) 2015-09-17 (Thu) 2015-09-19 (Sat) 2015-09-21 (Mon) 2015-09-23 (Wed) 2015-09-25 (Fri)
�ȒP�ɐ������鐔�����w��ł���̂� �m���ɕ֗��ł��ˁB
bash �őO�̃R�}���h�̈����������g�p����
�R�}���h�����s����Ƃ��� �R�}���h�̑O�� echo ��t���Ď����Ă݂邱�Ƃ�����܂��B
$ export testfile=dummy.txt $ echo rm $testfile rm dummy.txt
���̌�Aecho �������Ď��s����킯�ł��� !* ���g�����Ƃ� �������Ƃ��ȒP�Ɏ��s�ł��܂��B
$ export testfile=dummy.txt $ echo rm $testfile rm dummy.txt $ !* rm $testfile rm: cannot remove `dummy.txt': No such file or directory
!* �ɂ́A�O�Ɏ��s�����R�}���h�́u�R�}���h�����̃��[�h�v���i�[����邽�� echo �̌�납����s�����킯�ł��B
!^ ���Ɓu�R�}���h�����̃��[�h�v�̐擪�A !$ ���u�R�}���h�����̃��[�h�v�̍Ō�ɂȂ�܂��B
$ echo 1 2 3 4 5 1 2 3 4 5 $ echo !^ echo 1 1 $ echo 1 2 3 4 5 1 2 3 4 5 $ echo !$ echo 5 5
���Ȃ݂ɑO�Ɏ��s�����R�}���h�S�̂� !! �Ɋi�[����邽�� !! �������ƁA�O�̃R�}���h���Ď��s�ɂȂ�܂��B
$ echo 1 2 3 4 5 1 2 3 4 5 $ !! echo 1 2 3 4 5 1 2 3 4 5
���Ȃ݂ɁA���́u�R�}���h�����̃��[�h�v�̓p�C�v��_�C���N�g���܂݂܂��B
$ echo 1 2 3 4 5 > /tmp/test.txt $ echo !$ echo /tmp/test.txt /tmp/test.txt
�g���Ƃ��́A������Ƃ������ӂł��B
���_�C���N�g������ 0�o�C�g�㏑��
bash �ł́A���̂悤�Ƀ��_�C���N�g������ 0�o�C�g�̃t�@�C������邱�Ƃ��ł���悤�ł��B
����܂ł̓R�������_�C���N�g�Ƃ� /dev/null ���g���Ă܂����B
$ : > zero.txt $ cat /dev/null > zero.txt
���_�C���N�g�����ł����܂��B
$ > zero.txt $ ls -l zero.txt -rw-r--r-- 1 xxxxxx xxxxxx 0 2015-08-19 21:24 zero.txt
�V���v���ł����A�����ԈႢ�Ǝv��ꂻ���ł��ˁB
���ƒ��Ɏg�p����̂ɂ͕֗��ŗǂ������ł��B
SQLite �̃f�[�^�x�[�X�t�@�C���̃o�[�W�������m�F����
SQLite �ō쐬�����f�[�^�x�[�X�̃t�@�C���� SQLite �̂ǂ̃o�[�W�����ō쐬�������ł��� file �R�}���h�Ŋm�F���邱�Ƃ��ł��܂����B �iUbuntu10.04���j
$ file database.sqlite2 database.sqlite2: SQLite 2.x database $ file database.sqlite3 database.sqlite3: SQLite 3.x database
Linux �Ńe�L�X�g���烉���_���� 1�s�擾����
���Ђ����Ԃ�ł��B
cowsay �R�}���h�Ń����_���ɊG����ς������Ǝv���Ă�����ł����A ���̂��߂ɂ̓����_���ŊG�����w�肷��K�v������܂��B
�G���̈ꗗ�͎��̂悤�ȃR�}���h�Ŏ擾�ł��܂��B
$ cowsay -l | grep -v "^Cow"
��������A�����_���� 1�s�擾���܂��B �ŏ��� Bash �̔z����g���� ���̂悤�ɂ���Ă܂����B
$ LIST=(`cowsay -l | grep -v "^Cow"`) $ FMT=${LIST[$(($RANDOM % ${#LIST[@]}))]}
1�s�łł��Ȃ����ƒ��ׂĂ����� sort �R�}���h�ɂ� -R �I�v�V������ �������肷�邱�Ƃ�m��܂����B
���̂悤�ɂȂ�܂����B
$ cowsay -l | grep -v "^Cow" | sed -e "s/ /\n/g" | sort -R | head -n 1
cowsay �� fortune ������āA����Ŋ����ł��B
$ fortune | cowsay -n -f `cowsay -l | grep -v "^Cow" | sed -e "s/ /\n/g" | sort -R | head -n 1`
�E�E�E�Ǝv���Ă�����Ashuf �Ȃ�ăR�}���h������悤�� ���̂悤�ɂȂ�܂����B
$ fortune | cowsay -n -f `cowsay -l | grep -v "^Cow" | sed -e "s/ /\n/g" | shuf -n 1`
�F�X�Ƃ���܂��ˁB
�e�L�X�g�����͊o���Ă����ƁA�J�����̂�����Ƃ������ƂɎg���ĕ֗��Ȃ̂� �V�тȂ���o���Ă����������̂ł��B
watch �R�}���h
Linux �ɂ� watch �Ƃ����֗��ȃR�}���h������܂��B
�f�B���N�g���Ƀt�@�C���������������̂�҂��Ă�Ƃ��� �悭 ls �R�}���h��A�ł���̂ł��� watch �R�}���h���g���A��������ɂ���Ă���܂��B
$ watch ls -l /tmp
����ŁA�i�f�t�H���g�́j2�b�Ԋu�Ō��ʂ�\�����Ă���܂��B
�Ԋu��ύX����Ƃ��� "-n" �I�v�V�����ł��B
$ watch -n 5 ls -l /tmp
����� 5�b�Ԋu�ɂȂ�܂��B
"-d" �I�v�V�����ŁA�ύX�ӏ����n�C���C�g���邱�Ƃ��ł��܂��B
$ watch -d ls -l /tmp
�������A���̍X�V�^�C�~���O�Ńn�C���C�g�������Ă��܂��̂� �n�C���C�g���c�������ꍇ�� "-d" �I�v�V������ �X�� "=cumulative"��t���܂��B
$ watch -d=cumulative ls -l /tmp
bash �� cd - �� ���ϐ� OLDPWD
bash �ł� cd - �Ƃ��邱�Ƃ� 1�O�icd ����O�j�̃f�B���N�g���Ɉړ����邱�Ƃ��ł��܂��B
/var$ cd - /tmp /tmp$
���� 1�O�̃f�B���N�g���̃p�X�� ���ϐ� OLDPWD �Ɏ����Ă��܂��B
1�x�� cd ���g���Ă��Ȃ��ꍇ ���ϐ� OLDPWD �� ��Ȃ̂� cd - ���Ă� �f�B���N�g�����ړ��ł��܂���B
~$ bash ~$ cd - bash: cd: OLDPWD not set
�t�� ���ϐ� OLDPWD �� �l��ݒ肷��� cd - �� ���̃f�B���N�g���Ɉړ��ł��܂��B
~$ export OLDPWD=/tmp ~$ cd - /tmp /tmp$
find �R�}���h�� -exec �I�v�V������ + �� ; �ɂ���
find �� man �����Ă����� -exec �ɂ��� �ȉ��̂悤�ɏ����Ă���܂����B
-exec command ;
-exec command {} +
�v���X�H �Ǝv�����p���ǂ܂��ɑ������B �����Ă���y�[�W������܂����B
[�Q�l]
Linux - find �� -exec option�̖����ɂ� \; �� + �̈Ⴂ�B
- Qiita (2013/10/01)
$ find . -exec echo {} \; ./test1.txt ./test2.txt ./test3.txt
$ find . -exec echo {} + ./test1.txt ./test2.txt ./test3.txt
�Ȃ�قǁB
join �R�}���h�łł��邱�ƃC���C��
Linux �ɂ� join �Ƃ��� SQL�g���ɂ�����݈Ղ����ȃR�}���h������܂��B
���̃R�}���h�� 2�̃t�@�C���i�Е��͕W�����͉j�� �w�肵���t�B�[���h�Ō����������ʂ�Ԃ��Ă���܂��B
[text1.txt] 11111 aa1 22222 bb1 33333 cc1 55555 ee1
[text2.txt] 11111 aa2 33333 cc2 44444 dd2 66666 ff2
�t�B�[���h���w�肵�Ȃ��� 1�ڂ̃t�B�[���h�Ō������܂��B
$ join test1.txt test2.txt
11111 aa1 aa2
33333 cc1 cc2
INNER JOIN �ł��ˁB
test1.txt �� test2.txt �̗����ɑ��݂���
"11111" �� "33333" ���o�͂���܂����B
�O���������ł��܂��B
$ join -a1 test1.txt test2.txt 11111 aa1 aa2 22222 bb1 33333 cc1 cc2 55555 ee1
LEFT JOIN �ɂȂ�܂����B
test1.txt ����͑S�s���o�͂���Ă��܂��B
RIGHT JOIN ���ł��܂��B
$ join -a2 test1.txt test2.txt 11111 aa1 aa2 33333 cc1 cc2 44444 dd2 66666 ff2
test2.txt �̑S�s�ɂȂ�܂����B
"-a1" "-a2" �𗼕��w�肷�邱�Ƃ��ł��܂��B
$ join -a1 -a2 test1.txt test2.txt 11111 aa1 aa2 22222 bb1 33333 cc1 cc2 44444 dd2 55555 ee1 66666 ff2
����ŁA�ǂ��炩�̃t�@�C���� �t�B�[���h�����݂���s�� �o�͂���܂����B
cut �R�}���h�ȂǂŐ�o���� �����Ɏg�������ł��ˁB
$ join -a1 -a2 test1.txt test2.txt | cut -f1
11111
22222
33333
44444
55555
66666
�t�B�[���h���}�b�`���Ȃ��ꍇ�� �o�͂��邱�Ƃ��ł��܂��B
$ join -v1 test1.txt test2.txt 22222 bb1 55555 ee1
test1.txt �ɂ̂݃t�B�[���h�����݂���s�� �o�͂���܂����B
"-v1" �� "-v2" �� �ǂ�����w�肷��� �ǂ��炩�̃t�@�C���ɂ̂݃t�B�[���h�����݂���s���o�͂���܂��B
$ join -v1 -v2 test1.txt test2.txt 22222 bb1 44444 dd2 55555 ee1 66666 ff2
�w�肵���t�B�[���h�ł̔�r�Ȃ̂� diff �Ƃ͂�����ƈႢ�܂��ˁB
2�̃t�@�C���̍����Ȃ̂� �����̃`�F�b�N�Ɏg�������ł��B
$ join -v1 -v2 test1.txt test2.txt | cut -f1 22222 44444 55555 66666
�s�ԍ���t���� nl �R�}���h
Linux �ɂ͍s�ԍ���t���� nl �Ƃ����R�}���h������܂��B
�s�ԍ��t���邾���ł͂Ȃ��̂ł��� �[���@�艺�����g�����͂��܂���B
[test.txt] aaaaaaaaa bbbbbbbbb ccccccccc ddddddddd
$ nl test.txt
1 aaaaaaaaa
2 bbbbbbbbb
3 ccccccccc
4 ddddddddd
����Ȋ����ł��B
���ꂭ�炢�Ȃ� cat �ł��ł��܂��B
$ cat -n test.txt
1 aaaaaaaaa
2 bbbbbbbbb
3 ccccccccc
4 ddddddddd
nl �̓I�v�V�����Ȃ����Ƌ�s�͔ԍ���t���܂���B
$ nl test.txt
1 aaaaaaaaa
2 bbbbbbbbb
3 ddddddddd
4 eeeeeeeee
��s���ɂ��ԍ���t����ꍇ�̓I�v�V�������w�肵�܂��B
$ nl -b a test.txt 1 aaaaaaaaa 2 bbbbbbbbb 3 4 ddddddddd 5 eeeeeeeee
nl �Ȃ�ȒP�ɏ����l��ς��邱�Ƃ��ł��܂��B
$ nl -v 3 test.txt 3 aaaaaaaaa 4 bbbbbbbbb 5 ccccccccc 6 ddddddddd
1�s���Ƃ̑����l���w�肷�邱�Ƃ��ł��܂��B
$ nl -i 3 test.txt 1 aaaaaaaaa 4 bbbbbbbbb 7 ccccccccc 10 ddddddddd
awk �Ȃǂł��ł��Ȃ��͂Ȃ��ł��� �ȒP�Ȃ̂Ŋo���Ă����ƕ֗��ł��B
ls �R�}���h�̃^�C���X�^���v�̏���
ls �R�}���h�ŕ\�������^�C���X�^���v������ ���ϐ� LANG �ɂ���ĕς��܂��B
Ubuntu10.04 �� ls ���Ǝ��̂悤�ɂȂ�܂��B
LAMG=C
$ env LANG=C ls -lt -rw-r--r-- 1 root root 847 May 27 15:41 snmpd -rw-r--r-- 1 root root 258 Nov 28 2013 samba -rw-r--r-- 1 root root 876 Mar 17 2011 exim4 -rw-r--r-- 1 root root 64 Mar 17 2011 ntpdate
�^�C���X�^���v���Â��ꍇ�� �����ł͂Ȃ��A�N���\������܂��B
LANG=ja_JP.UTF-8
$ env LANG=ja_JP.UTF-8 ls -lt -rw-r--r-- 1 root root 847 May 27 15:41 snmpd -rw-r--r-- 1 root root 258 Nov 28 2013 samba -rw-r--r-- 1 root root 876 Mar 17 2011 exim4 -rw-r--r-- 1 root root 64 Mar 17 2011 ntpdate
LAMG=C �Ɠ����ł��ˁB
LANG=en_US.UTF-8
$ env LANG=en_US.UTF-8 ls -lt -rw-r--r-- 1 root root 847 2014-05-27 15:41 snmpd -rw-r--r-- 1 root root 258 2013-11-28 17:56 samba -rw-r--r-- 1 root root 876 2011-03-17 11:20 exim4 -rw-r--r-- 1 root root 64 2011-03-17 11:12 ntpdate
YYYY-MM-DD hh:mm �ɂȂ�܂��B
�w�肵�����Ƃ��� "--time-style" �I�v�V�������g���܂��B
$ ls -lt --time-style=+"%Y/%m/%d %H:%M:%S" -rw-r--r-- 1 root root 847 2014/05/27 15:41:05 snmpd -rw-r--r-- 1 root root 258 2013/11/28 17:56:50 samba -rw-r--r-- 1 root root 876 2011/03/17 11:20:45 exim4 -rw-r--r-- 1 root root 64 2011/03/17 11:12:01 ntpdate
����ōD���ȏ����ŕ\���ł��܂��B
find �R�}���h�ŕ����̃R�}���h�����s����
�����B
$ find /usr/local/lib/ -type d -exec dirname {} \; -exec basename {} \; /usr/local lib /usr/local/lib python2.6 /usr/local/lib/python2.6 site-packages /usr/local/lib/python2.6 dist-packages
-exec �I�v�V��������g���B
find �R�}���h�Ńf�B���N�g���̊K�w���[��������擾����
�����B
$ find /usr/local/lib/ -depth -type d /usr/local/lib/python2.6/site-packages /usr/local/lib/python2.6/dist-packages /usr/local/lib/python2.6 /usr/local/lib/
-depth �I�v�V������t����B
Raspberry Pi �� MRTG �����Ă݂� (3)
�O��̑��� SNMP �̐ݒ�ł��B �Ƃ肠���� SNMP ����f�[�^���擾�ł���悤�ɐݒ肵�Ă����܂��B
�܂� snmpd �̐ݒ�t�@�C����ҏW���܂��B
$ sudo vi /etc/snmp/snmpd.conf
���e�͎��̂悤�Ȋ����ł��i�S���j�B
############################################################################### # # AGENT BEHAVIOUR # # Listen for connections from the local system only agentaddress udp:161 ############################################################################### # # ACCESS CONTROL # # sec.name source community com2sec PI_LOCAL localhost RASPBERRY_PI com2sec PI_NETWOEK 192.168.3.0/24 RASPBERRY_PI # group.name sec.model sec.name group LOCAL_GROUP v1 PI_LOCAL group LOCAL_GROUP v2c PI_LOCAL group LOCAL_GROUP usm PI_LOCAL group NETWORK_GROUP v1 PI_NETWOEK group NETWORK_GROUP v2c PI_NETWOEK group NETWORK_GROUP usm PI_NETWOEK # view.name incl/excl subtree mask view all included .1 80 # group.name context sec.model sec.level match read write notif access LOCAL_GROUP "" any noauth exact all none none access NETWORK_GROUP "" any noauth exact all none none ############################################################################### # # SYSTEM INFORMATION # syslocation Raspberry Pi raspbian syscontact Studio ODIN <xxxxx@xxxxx.xx.xx> sysservices 72
�l�b�g���[�N�� 192.168.3.x ���g�p���Ă���̂ŁA���͈̔͂���̃A�N�Z�X�������Ă��܂��B community ���� "RASPBERRY_PI" �̓p�X���[�h�̈Ӗ����܂܂�Ă���̂ŁA �R�s�y����ꍇ�́A�K�X�ύX���Ă��������B
syslocation �� syscontact �́A�����̏��ł��̂œK���ɁB
�ݒ�t�@�C���̕ҏW���I������� �T�[�r�X���ċN�����܂��B
$ sudo service snmpd restart
���Ƃ͎����� snmpd �ɃA�N�Z�X���Ă݂܂��B
$ sudo snmpwalk -v 2c -c RASPBERRY_PI localhost 1.3.6.1.4.1.2021
"RASPBERRY_PI" �́A�ݒ�t�@�C������ community ���A "1.3.6.1.4.1.2021" ���擾������̎��ʎq�ł��B
���̃R�}���h�����s���āA�����_�[���ƋA���Ă����琬���ł��B
����͂����܂ŁB
Raspberry Pi �� MRTG �����Ă݂� (2)
�Z���ł����A�O���̑����B
�O��A MRTG �ŃO���t������f�[�^���擾���邽�߂� SNMP �̃p�b�P�[�W������܂����B
�C���X�g�[���������ŋN�����Ă���̂Ō��Ă݂܂��B
$ netstat -lun Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State udp 0 0 127.0.0.1:161 0.0.0.0:*
���̂悤�� UDP 127.0.0.1 �őҋ@���Ă��܂��B
�T�[�o�����Ŏg�p����ꍇ�͂���ł��ǂ��̂ł��� �ʂ̃T�[�o����� SNMP �ɃA�N�Z�X���邱�Ƃ� �l���Đݒ��ύX���܂��B
SNMP �̐ݒ�t�@�C����ҏW���܂��B
$ sudo vi /etc/snmp/snmpd.conf
������B
# Listen for connections from the local system only agentAddress udp:127.0.0.1:161
�������܂��B
# Listen for connections from the local system only agentAddress udp:161
���Ƃ̓T�[�r�X���ċN���B
$ sudo /etc/init.d/snmpd restart
����ŕʃT�[�o������A�N�Z�X�ł���悤�ɂȂ�܂����B
$ netstat -lun Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State udp 0 0 0.0.0.0:161 0.0.0.0:*
����͂����܂ŁB
Raspberry Pi �� MRTG �����Ă݂� (1)
������� MRTG �̕��K���Ă� Raspberry Pi �� MRTG �����Ă݂����Ǝv���܂��B
�Ƃ肠�����p�b�P�[�W���ŐV�̏�ԂɁB
$ sudo apt-get update
���Ȃ݂� 2014-01-07-wheezy-raspbian �������Ă��܂��B
$ sudo apt-get upgrade
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages have been kept back:
wolfram-engine
The following packages will be upgraded:
curl dpkg dpkg-dev file libcurl3 libcurl3-gnutls libdpkg-perl libgnutls26 libmagic1 libxfont1 libyaml-0-2
lsb-base python3-pifacedigital-scratch-handler tzdata udisks wget
16 upgraded, 0 newly installed, 0 to remove and 1 not upgraded.
Need to get 8,296 kB of archives.
After this operation, 570 kB of additional disk space will be used.
Do you want to continue [Y/n]?
�C���X�g�[���O��̃p�b�P�[�W�̃��X�g���擾���Ă����܂��B
$ sudo dpkg -l > ~/package_list_before_mrtg.txt
MRTG �� SNMP �̃f�[�����ƃN���C�A���g�����܂��B
$ sudo apt-get install snmpd snmp mrtg
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following extra packages will be installed:
libio-socket-inet6-perl libperl5.14 libsensors4 libsnmp-base libsnmp-session-perl libsnmp15
libsocket6-perl
Suggested packages:
lm-sensors snmp-mibs-downloader mrtg-contrib
The following NEW packages will be installed:
libio-socket-inet6-perl libperl5.14 libsensors4 libsnmp-base libsnmp-session-perl libsnmp15
libsocket6-perl mrtg snmp snmpd
0 upgraded, 10 newly installed, 0 to remove and 1 not upgraded.
Need to get 5,863 kB of archives.
After this operation, 9,507 kB of additional disk space will be used.
Do you want to continue [Y/n]?
�r���� "Make /etc/mrtg.cfg owned by and readable only by root?" �Ƃ��������̂� "Yes" �Ɠ����Ă����܂��B
$ sudo dpkg -l > ~/package_list_after_mrtg.txt
�C���X�g�[���O��̃p�b�P�[�W�̍����͎��̂悤�Ȋ����B
$ cd $ diff package_list_after_mrtg.txt package_list_before_mrtg.txt 292d291 < ii libio-socket-inet6-perl 2.69-2 all object interface for AF_INET6 domain sockets 357d355 < ii libperl5.14 5.14.2-21+rpi2 armhf shared Perl library 403d400 < ii libsensors4:armhf 1:3.3.2-2+deb7u1 armhf library to read temperature/voltage/fan sensors 413,416d409 < ii libsnmp-base 5.4.3~dfsg-2.7 all SNMP (Simple Network Management Protocol) MIBs and documentation < ii libsnmp-session-perl 1.13-1 all Perl support for accessing SNMP-aware devices < ii libsnmp15 5.4.3~dfsg-2.7 armhf SNMP (Simple Network Management Protocol) library < ii libsocket6-perl 0.23-1 armhf Perl extensions for IPv6 549d541 < ii mrtg 2.17.4-2 armhf multi router traffic grapher 639,640d630 < ii snmp 5.4.3~dfsg-2.7 armhf SNMP (Simple Network Management Protocol) applications < ii snmpd 5.4.3~dfsg-2.7 armhf SNMP (Simple Network Management Protocol) agents
�ȂF�X�Ɠ���܂����B
����͂����܂ŁB
Raspberry Pi �� rasbian �� 2014-01-07 �ɂ���
�v���Ԃ�� Raspberry PI �l�^�ł��B
����� raspbian ��z�z����Ă���ŐV�ɂ������Ǝv���܂��B �Ƃ����킯�ŁA 2014-01-07-wheezy-raspbian �����܂��B
[�Q�l�T�C�g]
Raspberry Pi ���� (26) �܂Ƃ� - Jun's homepage
�����̂悤�� ��L�T�C�g���Q�l�ɐi�߂܂��B
�_�E�����[�h���āA�𓀂��āASD�J�[�h�ɏ�������ŋN���B
2013-12-20-wheezy-raspbian �� Mathematica �������Ă܂��B �K���ɃR�}���h�����s�B
$ mathematica -v
10.0
�Ȃo�܂����B
2013-09-25-wheezy-raspbian ���� Java �������Ă܂��B
$ java -version
java version "1.7.0_40"
Java(TM) SE Runtime Environment (build 1.7.0_40-b43)
Java HotSpot(TM) Client VM (build 24.0-b56, mixed mode)
�Ƃ肠���������܂ŁB
���炭�����Ă����ƒǂ�������̂���ςł��ˁB
bash �ŗ������g��
bash �ɂ͗������擾�ł���ϐ��H�� �p�ӂ���Ă��܂��B
$ echo $RANDOM 2036
�J��Ԃ��ĂԂƈႤ�l���Ԃ�܂��B
$ echo $RANDOM 2036 $ echo $RANDOM 17653
man �ɂ͎��̂悤�ɂ���܂��B
RANDOM Each time this parameter is referenced, a random integer between 0 and 32767 is generated. The sequence of random numbers may be initialized by assigning a value to RANDOM. If RANDOM is unset, it loses its special properties, even if it is subsequently reset.
�͈͂� 0 �` 32767 �̂悤�ł��B
�͈͂��w�肵�����ꍇ�́A % �ŗ]������߂܂��B
$ echo $(($RANDOM % 10)) 7
printf �� 0�l�߂ɂ��ł��܂��B
$ VAL=`printf "%05d" $RANDOM` $ echo $VAL 02036
RANDOM �ɒl��ݒ肷��ƁA�����̎�����߂邱�Ƃ��ł��܂��B
$ RANDOM=3 $ echo $RANDOM 17653 $ echo $RANDOM 12499 $ RANDOM=3 $ echo $RANDOM 17653 $ echo $RANDOM 12499
��������w�肷��ƁA�����l���Ԃ��Ă��܂��B
find �� �����̃R�}���h�����s����
find �R�}���h�擾�����p�X�� -exec �I�v�V�������g���� �R�}���h�����s���邱�Ƃ��ł��܂��B
$ find . -mtime 3 -exec rm {} \;
-exec �������� �����̃R�}���h�����s���邱�Ƃ��ł��܂��B
$ find . -mtime 3 -exec echo {} \; -exec rm {} \;
type �R�}���h�̌��ʂ� "is hashed"
type �R�}���h�� ����\������� ���܂� "is hashed" �ƕ\������邱�Ƃ�����܂��B
$ type sl sl is hashed (/usr/games/sl)
�Ȃ낤�H�Ǝv���Ē��ׂĂ݂�� ���̃T�C�g�Ɂu�R�}���h�̏ꏊ�֍����ɃA�N�Z�X���邽�߂ɁA�悭�g�p����p�X���L���b�V���ɂƂ��Ă��āA�n�b�V���e�[�u�������̃L���b�V���v�� �����Ă���܂����B
[�Q�l]
type��which�̈Ⴂ���āH - OpenGroove
�Ȃ�قǁB
���݃n�b�V���e�[�u���ɃL���b�V������Ă���R�}���h�� hash �R�}���h�Ŋm�F�ł��܂��B
$ hash
hits command
1 /usr/bin/man
3 /usr/games/sl
hash �R�}���h�� �V�F���̑g�ݍ��݃R�}���h�ł��B
$ type hash
hash is a shell builtin
"-r" �I�v�V������ �n�b�V���e�[�u�����폜�ł��܂��B
$ hash -r
�폜��Ɋm�F���Ă݂܂��B
$ hash
hash: hash table empty
��ɂȂ��Ă��܂��B
�n�b�V���e�[�u������ɂȂ�����Ԃ� ���� 1 �x���Ă݂܂��B
$ type sl
sl is /usr/games/sl
"is hashed" ���\������Ȃ��Ȃ�܂����B
trap �R�}���h�́A�V�F���̑g�ݍ��݃R�}���h
���̑O�� �⑫�ɂȂ�̂ł����A trap �R�}���h�� �V�F���̑g�ݍ��݃R�}���h�ł��B
�Ƃ肠���� which �R�}���h�B
$ which trap
�����p�X�ɂȂ����� �����\������܂���B
type �R�}���h�� ����\�����邱�Ƃ��ł��܂��B
$ type trap trap is a shell builtin
�V�F���̑g�ݍ��݃R�}���h�̏ꍇ �p�X�ł͂Ȃ� "shell builtin" �ƕ\������܂��B
cd �� alias �R�}���h�Ȃǂ����l�ł��B
$ type cd cd is a shell builtin $ type alias alias is a shell builtin
�g�ݍ��݃R�}���h�łȂ��� "shell builtin" �ȊO���\������܂��B
$ type find find is /usr/bin/find $ type ls ls is aliased to `ls -F'
�������A�g�ݍ��݃R�}���h�ł�
�R�}���h�� alias ��ݒ肳��Ă���� "is aliased" ��
�\������܂��B
�i"-t" �I�v�V�����͌^�̂ݕ\���j
$ type -t cd builtin $ alias cd="cd" $ type -t cd alias $ unalias cd $ type -t cd builtin
���Ȃ݂� type �R�}���h���g�ݍ��݃R�}���h�ł��B
$ type type
type is a shell builtin
�V�F���X�N���v�g�̏I�����ɏ��������s��������
���b�N�t�@�C����ꎞ�t�@�C���̍폜�ȂǁA�V�F���X�N���v�g�̏I������ ���s�����������Ƃ����̂�����܂��B �ُ�I�����ɍ폜���Ă����Ȃ���Ȃ�Ȃ��ꍇ�Ȃ� ����L�q����̂͑�ςł��B
����ȂƂ��Ɏg���� trap �Ƃ����R�}���h������܂��B
trap �R�}���h�͎��̂悤�ɏ����ƃV�O�i�����w�肵�܂��B
trap "echo hogehoge" EXIT
�Ƃ肠�����R�}���h���C���Ŏ����Ă݂܂��B
INT �� [Ctrl]+[c] �Ȃǂɂ�銄�荞�݂̃V�O�i���ł��B
$ trap "echo hogehoge" INT
[Ctrl]+[c] �������� "echo hogehoge" �����s���܂��B
$ trap "echo hogehoge" INT $ ^Chogehoge $ ^Chogehoge
��������ɂ̓V�O�i���������w�肵�܂��B
$ trap INT $ ^C
[Ctrl]+[c] �������Ă�����������܂���B
�V�F���X�N���v�g�̒��� ���̂悤�ɏ����Ă����� �I�����Ƀt�@�C�����폜���Ă���܂��B
trap "rm text1.txt" EXIT
EXIT �̓v���Z�X�I�����̃V�O�i���Ȃ̂� �V�F���X�N���v�g�̏I�����g���b�v���Ă���܂��B
�����̐i�s��Ԃɂ���č폜����t�@�C����������Ƃ��� ���̂悤�ɍĒ�`������@�őΉ����邱�Ƃ��ł��܂��B
DELFILE="${DELFILE} test1.txt"
trap "rm ${DELFILE}" EXIT
(...����....)
DELFILE="${DELFILE} test2.txt"
trap "rm ${DELFILE}" EXIT
���݂̐ݒ���e�� "-p" �I�v�V�����A �V�O�i���̈ꗗ�� "-l" �I�v�V������ �\�������邱�Ƃ��ł��܂��B
find �R�}���h�̌��ʂŃt�@�C�����폜����Ƃ��̃���
���������ł��B
find �R�}���h�ň�莞�Ԍo�߂����t�@�C���� �폜����Ƃ��Ɏ��̂悤�ɏ������肵�܂��B
$ find /var/log/hoge -mtime +3 -exec rm {} \;
����� 3 ���ȏソ�����t�@�C���������Ă����E�E�E�Ǝv����ł��� ���ꂾ�ƃf�B���N�g�� /var/log/hoge ���܂܂�Ă��܂��܂��B
�e�X�g�� /var/log/hoge �����������i3���o�߂��Ă��Ȃ��ꍇ�j�� ���̃f�B���N�g����3���ȓ��Ƀt�@�C�����i�[�����ꍇ�́A ���o����Ȃ��̂ŋC�t���ɂ����̂ł����A ���炭�Ώۂ̃f�B���N�g���ɑ���X�V���Ȃ���Ԃ� ��̂悤�ȃR�}���h�����s����� �u�f�B���N�g���Ȃ̂ō폜�ł��Ȃ���v�G���[���o�܂��B
�ł��̂� "-type" �I�v�V�����̎w���Y��Ȃ��悤�ɂ��܂��B
$ find /var/log/hoge -type f -mtime +3 -exec rm {} \;
����Ńt�@�C���������ΏۂɂȂ�܂��B
�R�}���h�̃G�C���A�X���ɂ���
Redhat �ō�Ƃ��Ă��鎞�ɃA���H�Ǝv���� ���ׂ��̂Ń����Ƃ��ď����Ă����܂��B
Redhat �� root �ɂ� ���S�̂��߂� �G�C���A�X���g���� cp �R�}���h�̏㏑���m�F���f�t�H���g�ɂȂ��Ă��܂��B
# alias
alias cp='cp -i'
���̏�Ԃ��Ƌ����� "-f" �I�v�V������t���Ă� �m�F���Ă��܂��B ���̊m�F���~�߂��������Ƃ��� �G�C���A�X���폜����ȊO�ŕ��@�͂Ȃ��̂��Ǝv���� ���ׂĂ݂�Ƃ����Ƃ���܂����B
�G�C���A�X���ꎞ�I�ɖ����ɂ���ɂ� - @IT
�R�}���h�̑O�Ƀo�b�N�X���b�V����t����� �G�C���A�X���ɂł��邻���ł��B
�����Ă݂܂��B
$ alias cp='cp -i' $ alias alias cp='cp -i'
�܂��G�C���A�X��ݒ�B
�e�X�g�p�Ƀt�@�C�����쐬�B
$ touch test1.txt test2.txt
�����t�����Ɏ��s�B
$ cp test1.txt test2.txt
cp: overwrite `test2.txt'?
�m�F���Ă��܂��B
�o�b�N�X���b�V����t�����s�B
$ \cp -f test1.txt test2.txt
�m�F���Ă��܂���ł����B �G�C���A�X�������ɂȂ��Ă��܂��ˁB
�l�b�g���[�N�C���^�[�t�F�[�X���̌Œ艻
�ŋ߂� CentOS �� Fedora ������� �l�b�g���[�N�̃C���^�[�t�F�[�X���� eth0 �Ƃ��ł͂Ȃ� em1 �݂����Ȗ��O�ɂȂ��Ă��܂����Ƃ����邻���ł��B
em �Ƃ����̂� ethernet-on-motherboard �̗��̂悤�ł��B
����� biosdevname �Ƃ��� NIC �� �C���^�[�t�F�[�X�̑Ή����Œ艻���邽�߂� �d�g�݂������ŁA CentOS �ł́ANIC�i�� MAC �A�h���X�j���ς��� ethX �� X ���ς���Ă��܂����� ������Œ艻���邽�߂� 1�i�K���ۉ����Ă���悤�ł��B
[�Q�l�T�C�g]
ALL about Linux: CentOS 6.0 �� NIC �� ethX �̑Ή����Œ艻����
��L�T�C�g�ɂ��� DELL �̃}�V���� biosdevname �� ON �ɂȂ��Ă��邽�� ethX �ł͂Ȃ� emX �ƂȂ����悤�ł��B
RHEL �����l�ŁA�@�\�̗L���E�������ɂ��ď����Ă���܂����B
[�Q�l�T�C�g]
A.3. ���̋@�\�̗L�����Ɩ����� - Red Hat Customer Portal
Raspberry Pi �� tripwire �����Ă݂�
11/10 ���ŊJ�Â��ꂽ�wLPIC ���x��3 303 Security �Z�p��������Z�~�i�[�x�� tripwire ���������Ă����̂ŁA ���������Ȃ̂� Raspberry Pi �ɓ���Ă݂܂��B
tripwire �́A�t�@�C����₂Ȃǂ����o���邽�߂̃c�[���ł��B
���鎞�_�̃t�@�C���̏�Ԃ��f�[�^�x�[�X�ɕۑ����Ă����� �����_�̏�ԂƔ�r���邱�Ƃ��ł��܂��B
tripwire �̐ݒ�t�@�C����f�[�^�x�[�X���̂�������Ȃ��悤�� �F�ؗp�̃L�[���쐬����K�v������̂ł��� �ŋ߂́A�C���X�g�[���̗���ō쐬���邱�Ƃ��ł��܂��B
apt-get ���܂��B
$ sudo apt-get update $ sudo apt-get install tripwire
�r���A�T�C�g�L�[���쐬���邽�߂̃p�X�t���[�Y�����߂��܂��B
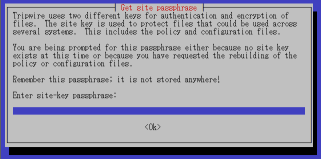
�T�C�g�L�[�́A�ݒ�t�@�C����������Ȃ����߂̃L�[�ł��B
���[�J���L�[���쐬���邽�߂̃p�X�t���[�Y�����߂��܂��B
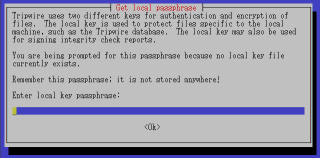
���[�J���L�[�́A�f�[�^�x�[�X��������Ȃ����߂Ɏg�p����L�[�ł��B
�C���X�g�[�����I��������A�f�[�^�x�[�X�����������܂��B ����ɂ���āA�u���̎��_�v�̃t�@�C���̏����f�[�^�x�[�X�ɕۑ����܂��B
$ sudo tripwire --init
Please enter your local passphrase:
���[�J���L�[�̃p�X�t���[�Y�����߂��܂��B
�f�[�^�x�[�X�ɕۑ��������ƁA�u�����_�v�̃t�@�C���̏��� ��r����ɂ� "--check" �I�v�V�������g�p���܂��B
$ sudo tripwire --check
���|�[�g���\������܂��B
���|�[�g���ēx�\������ɂ́A��r���ɐ������ꂽ twr �t�@�C����ǂݍ��݂܂��B
$ cd /var/lib/tripwire/report $ sudo twprint --print-report --twrfile raspberrypi-20121115-211440.twr
�u��r�������_�v�̃t�@�C���̏��Ńf�[�^�x�[�X���X�V����ɂ́A ��r���ɐ������ꂽ twr �t�@�C�����g���Ĉȉ��̂悤�ɃR�}���h�����s���܂��B
$ cd /var/lib/tripwire/report $ sudo tripwire --update -a --twrfile raspberrypi-20121115-211440.twr Please enter your local passphrase:
�f�[�^�x�[�X�̍X�V�Ȃ̂ł�͂胍�[�J���L�[�̃p�X�t���[�Y�����߂��܂��B
Linux �Ń��[�U���̕ύX
���[�U����ύX���郁���ł��B
�Ƃ����Ă��܂��O���[�v���B groupmod �R�}���h�� "-n" �I�v�V�����ŐV�������O���w�肵�܂��B
# groupmod -n NEW_NAME OLD_NAME
���[�U���� usermod �R�}���h�� "-l" �I�v�V�������g���܂��B
# usermod -l NEW_NAME OLD_NAME
�z�[���f�B���N�g�����ς���ꍇ�� ���̃z�[���f�B���N�g�������l�[�����Ă����� "-d" �I�v�V�����Ŏw�肵�܂��B
# mv /home/OLD_NAME /home/NEW_NAME # usermod -l NEW_NAME -d /home/NEW_NAME OLD_NAME
�Ώۂ̃��[�U�����O�C�����̏ꍇ�͕ύX�ł��܂���B
Bash �Ńp�C�v���Ă���Ƃ��̏I���X�e�[�^�X
Bash �Ńp�C�v���g���ăR�}���h�����s����� �I���X�e�[�^�X�́A�Ō�̃R�}���h�̌��ʂɂȂ�܂��B
���Ƃ��Ύ��̂悤�ȏꍇ
$ true | false | true
�Ԃ� false (�I���X�e�[�^�X 1�j������̂ł��� $? �Ŋm�F����� 0 �ɂȂ��Ă��܂��B
$ true | false | true $ echo $? 0
����� �Ō�� true �̏I���X�e�[�^�X�� 0 �̂��߂Ȃ̂ł��� ����ł͓r���ɃG���[�����������ǂ����킩��܂���B
�E�E�E�ƁA���炭�v���Ă����̂ł����A�ȉ��̃T�C�g�ɕ��@�������Ă���܂����B
[�Q�l]
�I���X�e�[�^�X - UNIX & Linux �R�}���h�E�V�F���X�N���v�g ���t�@�����X
Bash �̓���ϐ� $PIPESTATUS �ɓ��邻���ł��B
$ true | false | true $ echo ${PIPESTATUS[@]} 0 1 0 $ exit 3 | exit 12 | exit 0 $ echo ${PIPESTATUS[@]} 3 12 0
�z��̌`�œ���̂ŁA������g���p�C�v���̃R�}���h�̏I���X�e�[�^�X�� �m�F���邱�Ƃ��ł��܂��ˁB
Ubuntu10.04 �� /tmp �̑|��
Ubuntu10.04 �ɂ� tmpwatch �͓����ĂȂ����A�ł��ċN������� /tmp �͋�ɂȂ�̂� �����|�����Ă���̂��H�Ǝv���Ă�����ł��� ���̃T�C�g������� /etc/init/mounted-tmp.conf �ɐݒ肪����悤�ł��B
[�Q�l]
���܂ʂ���������(2010-07-21)
/etc/default/rcS �� TMPTIME �Ƃ����p�����[�^�� �폜�����܂ł̗P�\���Ԃ�ݒ�ł��邻���ł��B
wget �Ńv���L�V���o�R���Ȃ�
�Г��� wget ���g���Ă�Ƃ��͊O���ɐڑ����邽�߂� �v���L�V�̐ݒ�����Ă���̂ł����A �Г��̃T�[�o�ɐڑ�����Ƃ��Ȃ� �v���L�V���o�R���Ăق����Ȃ����Ă��Ƃ�����܂��B
$ wget --no-proxy http://.....
����Ȋ����Ńv���L�V���g�p���Ȃ��I�v�V���������܂��B
while ���[�v���̕ʃv���Z�X
while ���D���Ȃ̂Ŏ��̂悤�ȃ��[�v�� �悭�����܂��B
ls -1 | while read FILE
do
echo $FILE
done
����̓p�C�v���g���Ă���̂� while �ȍ~���ʃv���Z�X�ɂȂ��Ă��܂��܂��B �i���̐ԕ����̕������ʃv���Z�X�ł��j
ls -1 | while read FILE
do
echo $FILE
done
�Ȃ̂ŁA ���[�v���ŕϐ��̒l��ݒ肵�Ă� ���[�v�̊O�ł͎Q�Ƃ��邱�Ƃ��ł��܂���B
�Ⴆ�Ύ��̂悤�ȏꍇ
AAA=0 ls -1 | while read FILE do echo $FILE AAA=1 done echo $AAA
���ʂƂ��� 0 ���o�͂���܂��B
Linux �̃f�B�X�g���r���[�V�������ׂ�
�����Ă� Linux �̃f�B�X�g���r���[�V�������킩��Ȃ��ꍇ Ubuntu ���Ǝ��̂悤�� /etc/lsb-release ������킩���ł��� CentOS �́H�ƕ����ꂽ�̂Ń����B
$ cat /etc/lsb-release
[�Q�l]
�C���X�g�[������ Linux �f�B�X�g���r���[�V�������ƃo�[�W�������m�F����ɂ� - PRiMENON:DiARY
��̎Q�l�T�C�g�ɂ��� �Ƃ肠���� /etc/issue �A ���Ƃ� /etc �̉��� xxxx-release �݂����ȃt�@�C��������悤�ł��B
�Ȃ̂Ŏ��̂悤�ɂ��Ă����悢���ƁB
$ cat /etc/issue /etc/*-release
sshd �� IPv6 ���g�p���Ȃ�
Ubuntu10.04 �ł̐ݒ胁���ł��B
�i���̊����ꏏ���Ǝv���܂����E�E�E�j
�f�t�H���g�ł� IPv6 ���g�p����ݒ�ɂȂ��Ă���̂� netstat ����Ǝ��̂悤�ɂȂ�܂��B
$ netstat -ant | grep 22
tcp�@�@�@�@0�@�@�@0 0.0.0.0:22�@�@0.0.0.0:*�@�@�@ LISTEN
tcp6�@�@�@ 0�@�@�@0 :::22�@�@�@�@ :::*�@�@�@�@�@�@LISTEN
sshd �̐ݒ�t�@�C����ҏW���܂��B
$ sudo vi /etc/ssh/sshd_config
���̐ݒ��lj����܂��B
AddressFamily inet
sshd ���ċN�����܂��B
$ sudo service ssh restart
����� IPv6 �� LISTEN ���Ȃ��Ȃ�܂��B
$ netstat -ant | grep 22
tcp�@�@�@�@0�@�@�@0 0.0.0.0:22�@�@0.0.0.0:*�@�@�@ LISTEN
Ubuntu10.04 �ł� wget �̃v���L�V�ݒ�
Ubuntu10.04 �� wget �R�}���h���v���L�V�o�R�� �g�p����Ƃ��̃����ł��B
���ϐ��Őݒ肵�Ă���Ă��g���܂���ł����B
�ݒ�t�@�C����ύX���܂��B
$ sudo vi /etc/wgetrc
���̐Ԏ��̂悤�ɒlj����܂��B
# You can set the default proxies for Wget to use for http, https, # They will override the value in the environment. #https_proxy = http://proxy.yoyodyne.com:18023/ #http_proxy = http://proxy.yoyodyne.com:18023/ #ftp_proxy = http://proxy.yoyodyne.com:18023/ http_proxy = http://192.168.1.200:3128/ # If you do not want to use proxy at all, set this to off. #use_proxy = on use_proxy = on
�����OK�ł��B
�v���L�V�Ƀ��[�U�F���K�v�ȏꍇ�� ���̂悤�ɃR�}���h�ł��n�����Ƃ��ł��܂��B
$ wget --proxy-user=USERNAME \ --proxy-password=PASSWORD \ http://www.odin.hyork.net/
Ubuntu10.04 �� Webmin ������
Ubuntu10.04 �� Webmin �����郁���ł��B
Webmin �� obsolete �Ȃ̂� �f�t�H���g�ł� apt-get �œ���邱�Ƃ��ł��܂���B ����� deb �t�@�C���������Ă��ē���܂��B
�܂� deb �t�@�C���̎擾�B
$ wget http://prdownloads.sourceforge.net/webadmin/webmin_1.570_all.deb
Webmin �̃T�C�g�ɏ�����Ă��� URL ���� Not Found �ɂȂ�̂Œ��ӂ��Ă��������B
[�Q�l]
Webmin http://www.webmin.com/deb.html
�ˑ��W�̂���t�@�C�������܂��B Ubuntu10.04 �ł͎��̂悤�Ȋ����ł����B
$ sudo apt-get install apt-show-versions $ sudo apt-get install libapt-pkg-perl $ sudo apt-get install libnet-ssleay-perl $ sudo apt-get install libauthen-pam-perl $ sudo apt-get install libio-pty-perl
�Ō�ɗ��Ƃ��Ă��� deb �t�@�C�������܂��B
$ sudo dpkg --install webmin_1.570_all.deb
����ŏI���ł��B 10000 �|�[�g�� Webmin ���N�����܂��B
�p�X���[�h�����b�N����
Linux �ł� passwd �R�}���h���g���� ���[�U�̃p�X���[�h�����b�N���邱�Ƃ��ł��܂��B
�����p���[�U�̏����B
$ sudo useradd -M -d /tmp -s /bin/bash test01 $ echo "test01:hogehoge" | sudo chpasswd
���R�A����������[�U test01 �ɐ�ւ��邱�Ƃ��ł��܂��B
$ su - test01 �p�X���[�h: $ id uid=1002(test01) gid=1002(test01) �����O���[�v=1002(test01)
passwd �R�}���h�� "-l" �I�v�V������t���Ď��s���܂��B
$ sudo passwd -l test01 passwd: password expiry information changed.
����� test01 �ɐ�ւ��邱�Ƃ��ł��Ȃ��Ȃ�܂��B
$ su - test01 �p�X���[�h: su: �F�؎��s
���O�C�����ł��܂���B
������ root ����� ��ւ��邱�Ƃ��ł��܂��B
$ sudo su - test01 $ id uid=1002(test01) gid=1002(test01) �����O���[�v=1002(test01)
��������ɂ� "-u" �I�v�V�������g���܂��B
$ sudo passwd -u test01 passwd: password expiry information changed.
usermod �R�}���h���g���Ă��������Ƃ��ł��܂��B
$ sudo usermod -L test01
"-L" �����b�N�� "-U" �������ł��B�啶���Ȃ̂Œ��ӂł��B
$ sudo usermod -U test01
�������Ƃ����Ă���̂� passwd �R�}���h�Ń��b�N���� usermod �R�}���h�ʼn������邱�Ƃ��ł��܂��B
���[�U�̏�������O���[�v��\������
���[�U�̃O���[�v��\������ groups �Ƃ����R�}���h������܂��B
$ groups
ubuntu adm dialout cdrom plugdev lpadmin sambashare admin
���[�U���w�肵�Ȃ��� ���݂̃��[�U�̃O���[�v��\�����܂��B
���[�U���w�肷��ƃR�����ŋ���ĕ\�����Ă���܂��B
$ groups root
root : root
���[�U���w�肷�邱�Ƃ��ł��܂��B
$ groups root ubuntu
root : root
ubuntu : ubuntu adm dialout cdrom plugdev lpadmin sambashare admin
�Ȃ̂ŁA����Ȃ��Ƃ��ł��܂��B
$ groups `cut -f 1 -d : /etc/passwd` root : root daemon : daemon bin : bin sys : sys sync : nogroup games : games man : man lp : lp mail : mail news : news uucp : uucp proxy : proxy www-data : www-data backup : backup list : list irc : irc gnats : gnats nobody : nogroup libuuid : libuuid syslog : syslog sshd : nogroup landscape : landscape ubuntu : ubuntu adm dialout cdrom plugdev lpadmin sambashare admin postgres : postgres ssl-cert
�A�N�Z�X�����w�肵�ăf�B���N�g�����쐬����
mkdir �R�}���h�� �f�B���N�g�����쐬����Ƃ��� �A�N�Z�X�����ɐݒ肷�邱�Ƃ��ł��܂��B
"-m" �I�v�V�������w�肵�܂��B
$ mkdir -m 700 a
���Ă݂܂��B
$ ls -lF ���v 4 drwx------ 2 ubuntu ubuntu 4096 2011-11-20 23:54 a/
���R chmod ���g���Ă��ł��܂��� �o�b�`�����Ŏ��s������Ƃ��Ȃ� �R�}���h�̐��۔��肪 1 ��ōςނ̂ŕ֗��ȂƂ�������܂��B
find �Ŋm�F���Ȃ���R�}���h���s����
find �R�}���h�� "-exec" �ŃR�}���h�����s���邱�Ƃ��ł��܂��B
$ find . -type f -exec echo {} \; ./bbb.txt ./ccc.txt ./aaa.txt
rm �R�}���h�Ȃǂ� ���s���m�F����I�v�V���� "-i" ������̂� ������w�肷��ƃt�@�C�����ƂɊm�F���Ă���܂��B
$ find . -type f -exec rm -i {} \; rm: �ʏ�̋�t�@�C�� `./bbb.txt'���폜���܂���? rm: �ʏ�̋�t�@�C�� `./ccc.txt'���폜���܂���? rm: �ʏ�̋�t�@�C�� `./aaa.txt'���폜���܂���?
�R�}���h���̂Ɋm�F�̃I�v�V�������Ȃ��ꍇ find �R�}���h�� "-exec" �̑���� "-ok" ���g�p���܂��B
$ find . -type f -ok rm {} \; < rm ... ./bbb.txt > ? < rm ... ./ccc.txt > ? < rm ... ./aaa.txt > ?
����Ȋ����ɂȂ�܂��B
�ł����R�}���h�Ɏ��M���Ȃ��Ƃ��� �ڂŃ`�F�b�N���Ȃ��痬�������Ƃ��ɕ֗��ł��B
�A��������s�� 1 �s�ɂ܂Ƃ߂�
����ȃe�L�X�g������܂��B
aaaaaaaaaaa bbbbbbbbb ccccc dddddddd eeeeeeee fffff gggggg
�u��s�͍�肽�����ǁA���Ȃ̂ŏ����킯�ɂ������Ȃ��v ����ȂƂ��̘b�ł��B
���ʂ� cat ����Ǝ��̂悤�ɂȂ�܂��B
$ cat test.txt
aaaaaaaaaaa
bbbbbbbbb
ccccc
dddddddd
eeeeeeee
fffff
gggggg
�E�E�E���R�ł��ˁB
cat �̃I�v�V���� "-s" ���w�肵�܂��B
$ cat -s test.txt aaaaaaaaaaa bbbbbbbbb ccccc dddddddd eeeeeeee fffff gggggg
����ŁA�A��������s�� 1 �s�ɂȂ�܂����B
�t�@�C�����g���q�ŕ��ׂ�
�u�E�B���h�E�Y�ł�������ǂ����́H�v�Ƃ�����ł��B
�����B
$ touch aaa.txt $ touch bbb.sh $ touch ccc.log $ touch ddd.txt $ touch eee.cgi $ ls -l -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:10 aaa.txt -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:10 bbb.sh -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:11 ccc.log -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:11 ddd.txt -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:14 eee.cgi
ls �Ŋg���q�ŕ��ׂ�ɂ� "-X" �I�v�V�������g���܂��B
$ ls -lX -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:14 eee.cgi -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:11 ccc.log -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:10 bbb.sh -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:10 aaa.txt -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:11 ddd.txt
�g���q�ŕ��т܂����B
�f�B���N�g�����������Ă���ꍇ�͒��ӂ��K�v�ł��B
$ mkdir eee.d $ mkdir ggg $ ls -l -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:10 aaa.txt -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:10 bbb.sh -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:11 ccc.log -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:11 ddd.txt -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:14 eee.cgi drwxr-xr-x 2 ubuntu ubuntu 4096 2011-11-18 21:15 fff.d drwxr-xr-x 2 ubuntu ubuntu 4096 2011-11-18 21:15 ggg
"-X" �I�v�V�����̖��� ls �ł̓f�B���N�g�������O���ɕ��т܂��B
"-X" �I�v�V������t���܂��B
$ ls -lX drwxr-xr-x 2 ubuntu ubuntu 4096 2011-11-18 21:15 ggg -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:14 eee.cgi drwxr-xr-x 2 ubuntu ubuntu 4096 2011-11-18 21:15 fff.d -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:11 ccc.log -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:10 bbb.sh -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:10 aaa.txt -rw-r--r-- 1 ubuntu ubuntu 0 2011-11-18 21:11 ddd.txt
�f�B���N�g������ "." ���܂܂�Ă���ꍇ�A�t�@�C���Ɠ����悤�� "." �������g���q�Ƃ��ĕ��ׂĂ��܂��܂��B
�t�@�C�����V�����Ƃ������R�s�[��ړ�����
�ȑO�u�R�s�[��ړ�����Ƃ��ɓ����̃t�@�C����ޔ������v�Ƃ����l�^�������܂����� cp �R�}���h�� mv �R�}���h�ɂ́A���ɂ��֗��ȋ@�\�i�������Ƃ𑼂̕��@�ł�낤�Ƃ���Ə�����Ԃ�������j������܂��B
�I�v�V���� "-u" �ł��B
���̃I�v�V�����́A�R�s�[��ړ�����t�@�C���̃^�C���X�^���v���㏑������t�@�C�������V�����ꍇ�̂݁A���������s���܂��B
�����B
$ ls -l -rw-r--r-- 1 ubuntu ubuntu 2 11/16 23:40 test1.cgi -rw-r--r-- 1 ubuntu ubuntu 4 11/16 23:42 test2.cgi ���V����
�I�v�V���� "-u" ��t���ăR�s�[���܂��B
$ cp -u test1.cgi test2.cgi $ ls -l -rw-r--r-- 1 ubuntu ubuntu 2 11/16 23:40 test1.cgi -rw-r--r-- 1 ubuntu ubuntu 4 11/16 23:42 test2.cgi ���㏑������Ȃ�
�R�s�[��� test2.cgi �̕����V�����̂ŏ㏑������܂���B
�ړ����Ă݂܂��B
$ mv -u test1.cgi test2.cgi $ ls -l -rw-r--r-- 1 ubuntu ubuntu 2 11/16 23:40 test1.cgi �������Ȃ� -rw-r--r-- 1 ubuntu ubuntu 4 11/16 23:42 test2.cgi ���㏑������Ȃ�
�㏑������Ȃ������łȂ��A���t�@�C�� test1.cgi ���c��܂��B
������ȑO�̃t�@�C���ޔ��̃I�v�V���� "-b" �ƍ��킹��� �w�^�C���X�^���v���V�����ꍇ�̂݁A�R�s�[�i�ړ��j���āA����ɑޔ��t�@�C�����쐬����x�Ƃ��������ɂȂ�܂��B
���ꂾ���ł��ʔ����ł��� ������o�b�`�����ɑg�ݍ��ނƁA �^�C���X�^���v�Ƃ����ʎ��̃t���O�� �㏑������^���Ȃ��𐧌�ł���悤�ɂȂ�܂��B
locate �R�}���h�ō����Ɍ�������
locate �R�}���h�́A�R�}���h�̎��s���Ƀt�@�C������������̂ł͂Ȃ� ���O�ɍ쐬�����f�[�^�x�[�X���g���Č�������̂ŁAfind �R�}���h���������Ō������邱�Ƃ��ł��܂��B
$ locate cgi (�ȗ�) /usr/share/doc/popularity-contest/examples/popcon-submit.cgi /usr/share/doc/python-pexpect/examples/cgishell.cgi.gz /var/lib/nginx/fastcgi /var/lib/nginx/scgi
�p�^�[���}�b�`���O���F�X�ł��܂��B
$ locate "*.cgi" /usr/lib/w3m/cgi-bin/dirlist.cgi /usr/lib/w3m/cgi-bin/multipart.cgi /usr/lib/w3m/cgi-bin/w3mhelp.cgi /usr/lib/w3m/cgi-bin/w3mmail.cgi /usr/lib/w3m/cgi-bin/w3mman2html.cgi /usr/share/doc/popularity-contest/examples/popcon-submit.cgi
�����Ƀf�[�^�x�[�X���g���̂ŁA���������̃t�@�C�����������邱�Ƃ͂ł��܂���B
$ touch /var/www/test.cgi $ locate test.cgi
�f�[�^�x�[�X���X�V����ɂ� updatedb �R�}���h���g���܂��B
$ sudo updatedb
����ŏo�Ă��܂��B
$ locate test.cgi
/var/www/test.cgi
�f�[�^�x�[�X�̍X�V�� �������� cron �Ŗ��������悤�ɂȂ��Ă��܂��B Ubuntu �̏ꍇ�� /etc/cron.daily �ɂ���܂��B
$ ls -l /etc/cron.daily/mlocate
-rwxr-xr-x 1 root root 606 2010-03-24 19:16 /etc/cron.daily/mlocate
���ӂ��Ȃ��Ă͂����Ȃ��̂� /tmp �� /var/spool �Ȃǂ͏��O�̐ݒ肪����Ă��肵�� �������Ă��o�Ă��Ȃ��ꍇ������܂��B
Ubuntu �̏ꍇ /etc/updatedb.conf �ɐݒ肳��Ă��܂��B
$ cat /etc/updatedb.conf
PRUNE_BIND_MOUNTS="yes"
# PRUNENAMES=".git .bzr .hg .svn"
PRUNEPATHS="/tmp /var/spool /media"
PRUNEFS="NFS nfs nfs4 rpc_pipefs afs binfmt_misc proc smbfs autofs iso9660 ncpfs coda devpts ftpfs devfs mfs shfs sysfs cifs lustre_lite tmpfs usbfs udf fuse.glusterfs fuse.sshfs ecryptfs fusesmb devtmpfs"
�V���{���b�N�����N�̏��L�҂�ύX����
�V���{���b�N�����N�� chown �� �I�v�V�����Ȃ��Ŏ��s����� �����N��̏��L�҂��ς���Ă��܂��܂��B
�܂��������܂��B
$ mkdir directory $ ln -s directory link $ ls -l ���v 4 drwxr-xr-x 2 ubuntu ubuntu 4096 directory lrwxrwxrwx 1 ubuntu ubuntu 9 link -> directory
����Ȋ����B
�I�v�V�����Ȃ��� �V���{���b�N�����N�� chown ���܂��B
$ sudo chown root link $ ls -l ���v 4 drwxr-xr-x 2 root ubuntu 4096 directory lrwxrwxrwx 1 ubuntu ubuntu 9 link -> directory
�����N�� (directory) �̏��L�҂��ς��܂����B
"-h" �I�v�V������t���܂��B
$ sudo chown -h root link $ ls -l ���v 4 drwxr-xr-x 2 ubuntu ubuntu 4096 directory lrwxrwxrwx 1 root ubuntu 9 link -> directory
����ŃV���{���b�N�����N�̏��L�҂��ς��܂����B
�R�s�[��ړ�����Ƃ��ɓ����̃t�@�C����ޔ�����
Linux �� cp �R�}���h�ŃR�s�[�������� mv �R�}���h�ňړ�����Ƃ��ɁA �R�s�[���ړ���ɓ����̃t�@�C��������� �ʏ�͏㏑�����Ă��܂��܂��B
���� 2 �̃R�}���h�ɂ� �����̃t�@�C�����������Ƃ��� ���̃t�@�C����ޔ�������I�v�V����������܂��B
���̂悤�� a/ �� b/ �̂ǂ���ɂ� c.txt ������Ƃ��܂��B
$ ls a/ c.txt $ ls b/ c.txt
�ʏ�� cp �R�}���h���Ə㏑�����邾���ł��B
$ cp a/c.txt b/ $ ls b/ c.txt ���㏑�����ꂽ�t�@�C��
-b �I�v�V������t���܂��B
$ cp -b a/c.txt b/ $ ls b/ c.txt c.txt~
���̂悤�� c.txt~ ���ł��܂��B
������Ƃ킩��ɂ����ł��� c.txt ���㏑�����ꂽ�t�@�C����
���X������ c.txt �� c.txt~ �ɂȂ��Ă��܂��B
���Ȃ݂� Linux �ł� �t�@�C�����̍Ō�� ~ ���t���Ă���ꍇ �ޔ������t�@�C����ꎞ�t�@�C���ł���ꍇ�������ł��B
�ۑ������̂� 1 ���ゾ���Ȃ̂� ������x�R�s�[������� ���� c.txt �� c.txt~ �ɂȂ�܂��B
�o�b�`�����Ȃ� 1 ���ゾ���c���Ă����Ηǂ��Ƃ��Ȃ� ���̕��@�ł����������Ǝ�y�ł��B
LPIC Level3 Specialty 304 ���Ă��܂���
��T�A�O����悤�Ǝv���Ă� LPIC Level3 Specialty 304 ���Ă��܂����B
�M���M���ł������A�����̂悤�ɊȒP���̌��L�������܂����B
�V�F���̑g�ݍ��݃R�}���h�̈ꗗ��\������
bash �̑g�ݍ��݃R�}���h�̈ꗗ��\������ɂ� �g�ݍ��݃R�}���h�� help ���g���܂��B
$ help GNU bash, version 4.1.5(1)-release (i486-pc-linux-gnu) These shell commands are defined internally. Type `help' to see this list. Type `help name' to find out more about the function `name'. Use `info bash' to find out more about the shell in general. Use `man -k' or `info' to find out more about commands not in this list. A star (*) next to a name means that the command is disabled. job_spec [&] history [-c] [-d offset] [n] or hist> (( expression )) if COMMANDS; then COMMANDS; [ elif C> . filename [arguments] jobs [-lnprs] [jobspec ...] or jobs > : kill [-s sigspec | -n signum | -sigs> [ arg... ] let arg [arg ...] [[ expression ]] local [option] name[=value] ...
�g�ݍ��݃R�}���h�̏ڍׂ�����ɂ� help �̌�ɃR�}���h�𑱂��ď����܂��B
$ help bg bg: bg [job_spec ...] Move jobs to the background. Place the jobs identified by each JOB_SPEC in the background, as if they had been started with `&'. If JOB_SPEC is not present, the shell's notion of the current job is used. Exit Status: Returns success unless job control is not enabled or an error occurs.
tcsh �� csh �̑g�ݍ��݃R�}���h�̈ꗗ��\������ɂ� builtins �R�}���h���g���܂��B
> builtins : @ alias alloc bg bindkey break breaksw builtins case cd chdir complete continue default dirs echo echotc else end endif endsw eval exec exit fg filetest foreach
���L�҂Ńt�@�C����T��
�t�@�C����T���Ƃ��ɕ֗��ȃR�}���h find �ɂ� ���L�҂��w�肵�ĒT���I�v�V����������܂��B
$ find . -user root
����ŏ��L�҂� root �ɂȂ��Ă���t�@�C����T�����Ƃ��ł��܂��B
�O���[�v���w�肷�邱�Ƃ��ł��܂��B
$ find . -group adm
���[�U�ƃO���[�v�𗼕��w�肷�邱�Ƃ��ł��܂��B
$ find . -user root -group adm
���[�U���폜����Ƃ��� ���̃��[�U�̃t�@�C�����c���Ă��Ȃ��� �T���Ƃ��ɕ֗��ł��B
wget �œr���Ŏ~�܂������ɍĊJ����
wget �Ń_�E�����[�h���Ă���Ƃ��� �r���Ŏ~�܂邱�Ƃ�����܂��B
$ wget http://example.com/images/cdrom.iso
--2011-11-01 22:38:49-- http://example.com/images/cdrom.iso
Connecting to 192.168.3.1:3128... connected.
Proxy request sent, awaiting response... 200 OK
Length: 717225984 (684M) [application/octet-stream]
Saving to: `cdrom.iso'
99% [========================================> ] 714,444,862 --.-K/s eta 2s
����ȂƂ��� -c �I�v�V������t���Ď��s���܂��B
$ wget -c http://example.com/images/cdrom.iso --2011-11-01 22:49:16-- http://example.com/images/cdrom.iso Connecting to 192.168.3.1:3128... connected. Proxy request sent, awaiting response... 206 Partial Content Length: 717225984 (684M), 2781122 (2.7M) remaining [application/octet-stream] Saving to: `cdrom.iso' 100%[+++++++++++++++++++++++++++++++++++++++>] 717,225,984 1.00M/s in 2.6s 2011-11-01 22:49:18 (1.00 MB/s) - `cdrom.iso' saved [717225984/717225984]
����őO�̑�������_�E�����[�h���邱�Ƃ��ł��܂��B
�A���������������� 1 �����ɂ��� tr �R�}���h
tr �R�}���h�ɂ� �A���������������� 1 �����ɂ��� -s �Ƃ����I�v�V����������܂��B
�Ⴆ�Ύ��̂悤�ɃX�y�[�X�������Ă���ꍇ
abcde fghij
tr �R�}���h���g���ΊȒP�ɃX�y�[�X�� 1 �ɂ��邱�Ƃ��ł��܂��B
abcde fghij
���̂悤�Ɏw�肵�܂��B
$ echo "abcde fghij" | tr -s [:space:] abcde fghij
[:space:]�́A�X�y�[�X��^�u�Ȃǂ����������N���X�ł��B
ls �̏o�͂��ȒP�ɉ��H�ł��܂��B �i�Ӗ��͂Ȃ��ł����j
$ ls -ltr | head | tr -s [:space:]
total 9498
drwx------ 2 root root 48 1970-01-01 09:00 gconfd-root
drwx---rwx 2 root hpusers 48 2006-09-09 16:03 mmcache
drwxr-xr-x 2 apache apache 48 2006-09-09 16:11 fcgi
drwx------ 2 root root 120 2006-09-27 12:15 YaST2-06402-9kTlAk
drwxr-xr-x 4 root root 96 2007-06-03 17:21 pear
drwx------ 3 root root 80 2007-07-06 19:09 spamd-4708-init
drwx------ 3 root root 80 2007-07-06 22:28 spamd-4426-init
drwx------ 2 root root 120 2009-01-15 09:46 YaST2-04662-jtfPyg
srwxrwxrwx 1 mysql mysql 0 2010-03-04 08:29 mysql.sock
�A������u���������v�� 1 �ɂ��邾���Ȃ̂� [:alpha:] �� �w�肷��Ǝ��̂悤�ɂȂ�܂��B
$ echo "aaabbccddaaa" | tr -s [:alpha:]
abcda
�v�������Ȃ��Ƃ��ɖ��ɗ����Ƃ�����܂��B
apt-get �Ńp�b�P�[�W���w�肵�ăA�b�v�f�[�g����
apt-get �� upgrade �� �C���X�g�[���ς݂̃p�b�P�[�W��S�ăA�b�v�f�[�g���܂��B
apt-get update �� �p�b�P�[�W�̃A�b�v�f�[�g�ł͂Ȃ��A �p�b�P�[�W���X�g�̃A�b�v�f�[�g�ł��B �w�肵���p�b�P�[�W���A�b�v�f�[�g����ɂ� ��₱�����ł��� install ���w�肵�܂��B
�C���X�g�[���ς݂� apache2 ���A�b�v�f�[�g���Ă݂܂��B
$ sudo apt-get install apache2 Reading package lists... Done Building dependency tree Reading state information... Done The following packages were automatically installed and are no longer required: postgresql-doc php5-ldap postgresql-doc-8.4 Use 'apt-get autoremove' to remove them. The following extra packages will be installed: apache2-mpm-worker apache2.2-bin apache2.2-common php5-cli php5-common php5-gd php5-ldap php5-pgsql Suggested packages: apache2-doc apache2-suexec apache2-suexec-custom php-pear php5-suhosin The following packages will be REMOVED: apache2-mpm-prefork libapache2-mod-php5 php5 phpldapadmin phppgadmin The following NEW packages will be installed: apache2-mpm-worker The following packages will be upgraded: apache2 apache2.2-bin apache2.2-common php5-cli php5-common php5-gd php5-ldap php5-pgsql 8 upgraded, 1 newly installed, 5 to remove and 90 not upgraded. Need to get 6,609kB of archives. After this operation, 20.7MB disk space will be freed. Do you want to continue [Y/n]?
���̂悤�� upgraded �p�b�P�[�W�����\������܂��B
Bash �̃`���_�W�J
Bash �ł͎��̂悤�Ƀ`���_ (~) �� �J�����g���[�U�̃z�[���f�B���N�g���Ɉړ����邱�Ƃ��ł��܂��B
$ cd ~
�`���_�ɑ����ă��[�U�����w�肷��� ���̃��[�U�̃z�[���f�B���N�g���ɓW�J����܂��B
$ cat ~hogehoge/.bashrc
���̃��[�U�̃z�[���f�B���N�g���ׂȂ��Ă� �z�[���f�B���N�g�����w�肷�邱�Ƃ��ł��܂��B
exim4 �̍Đݒ�
Ubuntu �͕W���̃��[���T�[�o�Ƃ��� exim4 �����邱�Ƃ��ł��܂��B ���� exim4 �͎��̃t�@�C���� �ݒ���e���i�[���Ă��܂��B
/etc/exim4/update-exim4.conf.conf (typo ����Ȃ��ł�) /etc/mailname
/etc/exim4/update-exim4.conf.conf �ɂ� exim4 �̐ݒ���e���A /etc/mailname �ɂ� ���[�����M���ɑ��M�҂� @ �̌��ɕt����h���C����������܂��B
$ cat /etc/mailname
example.com
�t�@�C���̓��e���C�������ꍇ dpkg-reconfigure �����s����ȊO�� update-exim4.conf �Ƃ����X�N���v�g�̎��s�ōĐݒ肷�邱�Ƃ��ł��܂��B
$ sudo update-exim4.conf
������ .conf �ƕt���Ă��܂����X�N���v�g�t�@�C���ł��B exim4 �̐ݒ���X�V����̂� update-exim4.conf �� ���̐ݒ�t�@�C���Ȃ̂� update-exim4.conf.conf �ȂƎv���܂��B
�t�@�C���̃X�e�[�^�X��\������R�}���h
Linux �ɂ� �t�@�C���̃X�e�[�^�X��\������ stat �Ƃ����R�}���h������܂��B
$ stat /var/log/user.log
File: `/var/log/user.log'
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fc01h/64513d Inode: 157223 Links: 1
Access: (0640/-rw-r-----) Uid: ( 101/ syslog) Gid: ( 4/ adm)
Access: 2011-02-03 10:18:03.000000000 +0900
Modify: 2011-02-03 10:18:03.000000000 +0900
Change: 2011-06-28 18:30:39.000000000 +0900
�t�@�C���̍ŏI�A�N�Z�X�����܂Ŏ擾�ł��܂��B
���Ȃ݂� Access ���ŏI�A�N�Z�X�����A Modify ���ŏI�ύX�����A Change �������Ȃǂ̍ŏI�ύX�����ł��B
�t�@�C���̏����擾����R�}���h�� file �Ƃ����̂�����܂��� ������̓t�@�C���^�C�v��\�����܂��B
sudo �̃^�C���A�E�g�܂ł̎��Ԃ�����
Ubuntu �ł� root ���g�킸�� sudo ���邱�ƂɂȂ�̂ł��� �f�t�H���g�ł� 1 �x sudo ���Ă��� 5 �� sudo ���Ȃ��� �ēx�p�X���[�h�̓��͂����߂��܂��B
�ʏ�͂���ŗǂ��̂ł��� �܂Ƃ܂�����Ƃ����Ă���Ƃ��Ȃǂ� �������������������Ƃ�������܂��B
sudo �̐ݒ�� /etc/sudoers �� visudo �R�}���h�ŕҏW����̂ł���
Ubuntu10.04 ���ƃG�f�B�^�� nano ���N������̂� env �Ŋ��ϐ���ς��� vi �ɂ��܂��B
(����͎��� nano ���g���Ȃ�����ł��E�E�E)
$ sudo env EDITOR=/usr/bin/vi visudo
���X���� Defaults �̉��ӂ�ɒlj����܂��B
Defaults env_reset ������
Defaults timestamp_timeout = 20 ���lj�
����Ń^�C���A�E�g�܂ł̎��Ԃ� 20 ���ɂȂ�܂����B
Defaults �̓J���}�ŋ���� 1 �s�ŏ����Ă� OK �ł��B
Defaults env_reset, timestamp_timeout = 20
Bash �� �ϐ��W�J
Bash �� �ϐ��W�J�ɂ͌��\��ނ�����܂��B
�悭�g���͎̂��́u������̖�������ŒZ�}�b�`�����č폜�v�� �u�t�@�C���̊g���q�v�̍폜�ł��B
$ ls *.txt | while read FILE > do > echo ${FILE%.txt} > done
"${FILE%.txt}" �̕������ϐ��W�J�ł��B ����� ls �R�}���h�� .txt �̃t�@�C���������擾���� �t�@�C�������� .txt ���폜�����������o�͂��邱�Ƃ��ł��܂��B
�ϐ��W�J�ɂ͎��̂悤�Ȃ��̂�����܂��B
| ${�ϐ�:+������} | �ϐ������݂���łȂ�����̕�����A����ȊO�Ȃ�� |
|---|---|
| ${�ϐ�:-������} | �ϐ������݂���łȂ�����̒l�A����ȊO�Ȃ當���� |
| ${�ϐ�:=������} | �ϐ������݂���łȂ�����̒l�A����ȊO�Ȃ�ϐ��ɕ������ݒ� |
| ${�ϐ�:?������} | �ϐ������݂���łȂ�����̒l�A����ȊO�Ȃ當������o�͂��ďI�� |
| ${�ϐ�:�ʒu} | �ʒu���疖���܂ł̕��������� |
| ${�ϐ�:�ʒu:����} | �ʒu���璷�����̕��������� |
| ${�ϐ�#�p�^�[��} | �ϐ��̐擪���p�^�[���}�b�`�����ꍇ�A�ŒZ�}�b�`�������폜 |
| ${�ϐ�##�p�^�[��} | �ϐ��̐擪���p�^�[���}�b�`�����ꍇ�A�Œ��}�b�`�������폜 |
| ${�ϐ�%�p�^�[��} | �ϐ��̖������p�^�[���}�b�`�����ꍇ�A�ŒZ�}�b�`�������폜 |
| ${�ϐ�%%�p�^�[��} | �ϐ��̖������p�^�[���}�b�`�����ꍇ�A�Œ��}�b�`�������폜 |
| ${�ϐ�/�p�^�[��/������} | �ŏ��Ƀp�^�[���}�b�`������������Œu�� |
| ${�ϐ�//�p�^�[��/������} | �p�^�[���}�b�`�������ׂĂ̕�������Œu�� |
Bash �����ł��F�X�Ȃ��Ƃ��ł��܂��B
sudo ���_�C���N�g
sudo �Ń��_�C���N�g����ꍇ�A���̂悤�ɏ����ƁA���_�C���N�g��̃t�@�C���̌����� sudo �������[�U�ɂȂ�܂��B
$ sudo echo aaa > test.txt ~~~~~~~~~~ �����̕����� sudo �Ƃ͖��W
���_�C���N�g���� sudo ���������Ŏ��s�������ꍇ�� ���̂悤�ɏ����܂��B
$ sudo sh -c "echo aaa > test.txt"
Bash �̑g�ݍ��݃R�}���h�ƊO���R�}���h
Bash �ɂ� cd �̂悤�� Bash ���̂ɑg�ݍ��܂�Ă���R�}���h������܂��B �g�ݍ��݃R�}���h���O���R�}���h���� type �Ƃ����R�}���h�Ŋm�F�ł��܂��B
$ type cd
cd is a shell builtin
�g�ݍ��݃R�}���h�� "builtin" �Əo�͂���܂��B
$ type ftp
ftp is /usr/bin/ftp
�O���R�}���h�� �p�X���o�͂���܂��B
$ type ls
ls is aliased to `ls --color=auto'
�G�C���A�X�͂��̂悤�ɏo�͂���܂��B
�G�C���A�X���ׂ�ɂ� "-a" �I�v�V������t���܂��B
$ type -a ls
ls is aliased to `ls --color=auto'
ls is /bin/ls
type �R�}���h�� Bash �̑g�ݍ��݃R�}���h�ł��B
$ type -t type
builtin
Bash �̑g�ݍ��݃R�}���h pushd
bash �ɂ� pushd �Ƃ����R�}���h������܂��B
pushd �R�}���h�� cd �R�}���h�Ɠ����悤�� �f�B���N�g�����ړ����邱�Ƃ��ł��܂��B
cd �R�}���h�Ƃ̈Ⴂ�� �ړ������f�B���N�g�����f�B���N�g���X�^�b�N�� �ς�Łi�ۑ����āj����܂��B "push directory" �ȃ��P�ł��B
�f�B���N�g���X�^�b�N�̓��e�� dirs �R�}���h�Ō��邱�Ƃ��ł��܂��B ������Ԃł́A�z�[���f�B���N�g���� �f�B���N�g���X�^�b�N�ɐς܂�Ă��܂��B
~:$ dirs ~
���ۂɎg���Ă݂܂��B pushd �R�}���h�́A���s��Ɍ��݂̃f�B���N�g���X�^�b�N�� �\�����Ă���܂��B
~:$ pushd /var /var ~ /var:$ pushd /home /home /var ~ /home:$
�f�B���N�g���X�^�b�N������o���ɂ� popd �R�}���h���g���܂��B
/home:$ popd /var ~ /var:$
���̂܂܂ł��ǂ��̂ł��� ���� function ���g���Ċ����� cd �R�}���h�� �u�������Ďg�p���Ă��܂��B
function cd {
case $1 in
"")
pushd $HOME > /dev/null
;;
"-")
[ `dirs | wc -w` -gt 1 ] && popd > /dev/null
;;
*)
[ -d $1 ] && pushd $1 > /dev/null
;;
esac
}
�������w�肵�Ȃ���z�[���f�B���N�g���ɁA�f�B���N�g���� �w�肵���ꍇ�͈ړ����ăf�B���N�g���X�^�b�N�ɐς݂܂��B �n�C�t�� "-" ���w�肵���ꍇ�̓f�B���N�g���X�^�b�N������o���܂��B
tac �R�}���h�� rev �R�}���h�̎g����
�ȑO�Љ�� tac �R�}���h�� rev �R�}���h�� �g������T���Ă����̂ł����A�f���炵���l�^�������Ă���T�C�g������܂����B
�y�Q�l�T�C�g�z
�����ӂ݃��� : Linux��rev�R�}���h�ŕ������t�ɕ��ׂ�
�\�[�g�╶���̐�o���͍l���Ă����̂ł��� banner �R�}���h���g�����l�^�͑z��O�ł����B
banner �� ���̂悤�ȏo�͂��ł���R�}���h�ł��B
$ banner Linux
# ### # # # # # #
# # ## # # # # #
# # # # # # # # #
# # # # # # # #
# # # # # # # # #
# # # ## # # # #
####### ### # # ##### # #
����� tac �R�}���h�ɒʂ��Ə㉺���t�ɂȂ�܂��B
$ banner Linux | tac
####### ### # # ##### # #
# # # ## # # # #
# # # # # # # # #
# # # # # # # #
# # # # # # # # #
# # ## # # # # #
# ### # # # # # #
rec �R�}���h�ɒʂ��ƍ��E���t�ɂȂ�܂��B
$ banner Linux | rev
# # # # # # ### #
# # # # # ## # #
# # # # # # # # #
# # # # # # # #
# # # # # # # # #
# # # # ## # # #
# # ##### # # ### #######
2 �̃R�}���h�ɒʂ��� 180 �x��]�����邱�Ƃ��ł��܂��B
$ banner Linux | rev | tac
# # ##### # # ### #######
# # # # ## # # #
# # # # # # # # #
# # # # # # # #
# # # # # # # # #
# # # # # ## # #
# # # # # # ### #
�A�C�f�A���悾�Ɗ��S�������܂��B
������]������ rev �R�}���h
�ȑO������ tac �R�}���h�� �s�]����R�}���h�ł����B �����ŁA�s���̕�����]����R�}���h���������ƒT���Ă݂��� rev �Ƃ����R�}���h������܂����B
���̃e�L�X�g�i test.txt �j���������܂��B
1 2 3 4 5 6 7 8 9
rev �R�}���h�ŏo�͂��܂��B
$ rev test.txt
3 2 1
6 5 4
9 8 7
�s�̏��Ԃ͂��̂܂܂ł����A�s���ŕ��������]���Ă��܂��B
�W�����͂��邱�Ƃ��ł��܂��B
$ cat test.txt | rev
3 2 1
6 5 4
9 8 7
tac �ƍ��킹�Ďg���ƑS�Ĕ��]�����邱�Ƃ��ł��܂��B
$ tac test.txt | rev
9 8 7
6 5 4
3 2 1
�\�[�g�Ɏg�����炢�ŁA���Ɂu���ꂼ�I�v�Ƃ����g�����͎v�����܂��� �����K�v�ɂȂ�Ƃ��̂��߂ɁA�����������R�}���h���p�ӂ���Ă���͈̂��S�ł��ˁB
tac �R�}���h�Ƃ�
Linux �ɂ� tac �Ƃ����R�}���h������܂��B
���i�̊w�Z�Ƃ͑S���W�͂���܂���B
�u cat �R�}���h�̋t�v�Ƃ������Ƃ� tac �ł��B
$ cat test.txt
abc
123
efg
456
$ tac test.txt 456 efg 123 abc
���̂悤�� cat �Ƃ� �t���̏o�͂ɂȂ�܂��B
�f�t�H���g�ł́A��蕶�������s�ɂȂ��Ă���̂� �s�P�ʂŋt�ɂȂ�܂��B ���̃R�}���h�ōs���t�ɂ���̂͌��\��ςȂ̂� �o���Ă����Ɩ��ɗ��Ƃ��������Ȃ��ł��傤���B
���ɂ� if �` fi�Acase �` esac �Ƃ������悤�� �u�t�̕�����v�ʼn�����\�����邱�Ƃ�����܂����A �e�L�X�g�Ȃ�ł͂̔��z�Ŗʔ��Ǝv���܂��B
newgrp �R�}���h�ŃO���[�v��ύX����
Linux �� newgrp �Ƃ����O���[�v��ύX����R�}���h������܂��B
���̃R�}���h�A�ݒ�t�@�C���Ȃǂ�ύX����R�}���h�ł͂Ȃ� su �R�}���h�̂悤�Ɉꎞ�I�ɏ�Ԃ�ύX����R�}���h�ł��B
�܂��O���[�v�ɂ��Ăł����A Linux �̃��[�U�� ���̗�̂悤�ɕ����̃O���[�v�ɑ����邱�Ƃ��ł��܂��B
$ id uid=501(hoge) gid=502(develop) groups=497(manage),502(develop)
id �R�}���h�ŏo�͂���� groups �́A�⏕�O���[�v�ƌĂ��
���[�U�������Ă���O���[�v�ł��B
gid �̕��́A�ꎟ�O���[�v�ƌĂ�A�t�@�C�����쐬�����Ƃ���
���̃O���[�v�̌������ݒ肳��܂��B
���̃R�}���h�ŁA�ꎟ�O���[�v��ύX���邱�Ƃ��ł��܂��B
$ newgrp manage $ id uid=501(hoge) gid=497(manage) groups=497(manage),502(develop)
�t�@�C�����쐬����ƃO���[�v���ς���Ă���̂��킩��܂��B
$ ls -l -rw-r--r-- 1 hoge develop 0 2010-06-01 22:55 a.txt -rw-r--r-- 1 hoge manage 0 2010-06-01 22:56 b.txt
���̏ꍇ�Anewgrp ����Ƃ��Ƀp�X���[�h�̓��͂����߂��܂��B
- ���[�U�ɂ̓p�X���[�h���Ȃ��O���[�v�ɂ͂���
- ���[�U���O���[�v�̃����o�[�ł͂Ȃ��O���[�v�Ƀp�X���[�h������
su �R�}���h���l�Aroot �̏ꍇ�̓p�X���[�h�̓��͂��s�v�ł��B
newgrp ����� su �Ɠ��l�ɐV�����V�F�����N�����܂��B
$ pstree init�� �� ��sshd��sshd��bash��pstree $ newgrp manage $ pstree init�� �� ��sshd��sshd��bash��bash��pstree
su �R�}���h�Ɠ��l�Ɋ�������������ɂ� "-" ���w�肵�܂��B
$ newgrp - manage
�܂��Asg �Ƃ��� newgrp �Ƃقړ��@�\�̃R�}���h������܂��B
newgrp �Ƃ̑傫�ȈႢ�Ƃ��āAsu �R�}���h�Ɠ��l��
"-c" �I�v�V�����ŃR�}���h�����s���邱�Ƃ��ł��܂��B
$ sg --help
usage: sg group [[-c] command ]
���Ȃ݂ɁAsg �R�}���h�� newgrp �̃V���{���b�N�����N�̂悤�ł��B
$ ls -l /usr/bin/newgrp /usr/bin/sg -rwsr-xr-x 1 root root 27080 Mar 8 2004 /usr/bin/newgrp lrwxrwxrwx 1 root root 6 Jan 20 2004 /usr/bin/sg -> newgrp
Linux �� join �R�}���h���e�L�X�g�̒��o�Ɏg���Ă݂�
join �Ƃ����R�}���h������܂��B
�z�����Ɍ������� join ������܂��� �f�[�^�x�[�X���g���Ă�l�Ȃ�e�[�u���̌����� �v�������ׂ�̂ł͂Ȃ��ł��傤���B ������̃C���[�W�ł��B
�܂��� paste �R�}���h�̂����炢�B
���� 2 �̃t�@�C�� sugaku.txt �� kokugo.txt ���������܂��B
ito 98 1 kameda 83 2 tanaka 71 3 wada 32 4
ito 91 2 tanaka 100 1 wada 45 3
���w�ƍ���̃e�X�g���ʂŁA�u���O�A�_���A���ʁv�� �e�L�X�g�t�@�C���ɏ�����Ă��܂��B
join ���܂��B
$ join sugaku.txt kokugo.txt ito 98 1 91 2 tanaka 71 3 100 1 wada 32 4 45 3 ~~~~|~~~~ ~~~~|~~~~ sugaku.txt�̓��e kokugo.txt�̓��e
2 �̃t�@�C���� 1 �ɂ܂Ƃ܂�܂����B
�I�v�V�����Ȃ��̏ꍇ�A1 ��ڂ̒l���g���Č������܂��B
kokugo.txt �� kameda �̍s�͂Ȃ��������ߏ��O����܂����B �f�[�^�x�[�X�e�[�u���̓��������Ɠ����ł��B
���������ƂȂ���ς��邱�Ƃ��ł��܂����A
���炩���߃\�[�g����Ă���K�v������܂��B
���ʂŌ������邽�߂� kokugo.txt �����ʂ̗�Ń\�[�g����
kokugo2.txt �����܂��B
�i sugaku.txt �͏��ʂ̗�������ɂȂ��Ă���̂Ń\�[�g�s�v�j
$ sort +2 -n kokugo.txt > kokugo2.txt $ cat kokugo2.txt tanaka 100 1 ito 91 2 wada 45 3
3 ��ڂ̏��ʂ̗�� join ���܂��B
$ join -1 3 -2 3 sugaku.txt kokugo2.txt 1 ito 98 tanaka 100 2 kameda 83 ito 91 3 tanaka 71 wada 45 ~~~~|~~~~~ ~~~~|~~~~~~ sugaku.txt�̓��e kokugo2.txt�̓��e
"-1" �� 1 �ڂ̃t�@�C���̌��������ƂȂ����w�肵�܂��B "-2" �� 2 �ڂ̃t�@�C���̌��������ƂȂ��ł��B
���������ƂȂ��� �擪�ɏo�͂���܂��B
�t�@�C���� 1 ��W�����͂���邱�Ƃ��ł��܂��B ���̏ꍇ�A�t�@�C���̎w��̕ς��Ƀn�C�t�� "-" ���w�肵�܂��B
$ cat sugaku.txt | join -1 3 -2 3 - kokugo2.txt 1 ito 98 tanaka 100 2 kameda 83 ito 91 3 tanaka 71 wada 45
����𗘗p���� �W�����͂�����R�}���h�̏o�͌��ʂ̃e�L�X�g�� ���o���Ă݂����Ǝv���܂��B
ls �̌��ʂ����̂悤�ɂȂ�Ƃ��܂��B
$ ls -l
-rw-r--r-- 1 hoge hoge 54 May 31 04:12 a.txt
-rw-r--r-- 1 hoge hoge 54 May 31 04:12 b.txt
-rw-r--r-- 1 hoge hoge 54 May 31 04:12 c.txt
-rw-r--r-- 1 hoge hoge 54 May 31 04:12 d.txt
�܂����̂悤�ȃe�L�X�g�i where.txt �j��p�ӂ��܂��B
a.txt b.txt
join ���܂��B
$ ls -l | join -1 9 - where.txt
a.txt -rw-r--r-- 1 hoge hoge 54 May 31 04:12
b.txt -rw-r--r-- 1 hoge hoge 54 May 31 04:12
a.txt �� b.txt �������o�ł��܂����B
����w�肵�Ē��o�ł���̂Œ��o���������̗�ɍ������Ă��Ă� ���v�Ƃ������_������܂��B
Linux �� paste �R�}���h�� �J���}���̃f�[�^�����
paste �Ƃ����R�}���h������܂��B
2 �̃t�@�C�����s���ƂɘA�����邷��R�}���h�Ȃ̂ł��� �����g������ƈႤ�h�g�������Ȃ����l���Ă��܂����B ����́A���̃R�}���h�ŃJ���}���̃f�[�^������Ă݂����Ǝv���܂��B
�܂��� paste �R�}���h�̂����炢�B
���� 2 �̃t�@�C�� user.txt �� color.txt ���������܂��B
sato suzuki watanabe yamada
red black white
���� 2 �̃t�@�C������ƂɘA�����܂��B
$ paste user.txt color.txt
sato red
suzuki black
watanabe white
yamada
�f�t�H���g�ł́A��� TAB �ŘA������܂��B color.txt �� 1 �s���Ȃ��̂� �Ō�̍s�� "yamada" �̂ݏo�͂���܂��B
����ς��邱�Ƃ��ł��܂��B
$ paste -d "=" user.txt color.txt sato=red suzuki=black watanabe=white yamada=
"-s" �I�v�V������t����ƁA�t�@�C�����Ƃ� 1 �s�ɂȂ�܂��B
$ paste -s user.txt color.txt
sato suzuki watanabe yamada
red black white
�W�����͂��邱�Ƃ��ł��܂��B
$ cat color.txt | paste -s
red black white
����𗘗p���邱�ƂŁA �W�����͂��� �J���}���ŏo�͂��邱�Ƃ��ł��܂��B
$ ls | paste -s -d ","
a.txt,b.txt,c.txt,d.txt
Linux �� sort �R�}���h�Ń\�[�g�������w�肷��
Linux �� sort �R�}���h�̓\�[�g�������w�肷�邱�Ƃ��ł��܂��B
���̃e�L�X�g�t�@�C���i score.txt �j���������Ă݂܂��B
yamada 90 tanaka 100 sato 64 suzuki 93
�I�v�V�����Ȃ��̃\�[�g���Ǝ��̂悤�ɂȂ�܂��B
$ sort score.txt
sato 64
suzuki 93
tanaka 100
yamada 90
2 ��ڂŃ\�[�g���܂��B
$ sort -k 2,2 score.txt tanaka 100 sato 64 yamada 90 suzuki 93
"2,2" �Ƃ����w��� �u 2 ��ڂ��� 2 ��ڂ܂Łv�Ƃ����Ӗ��� 2 ��ڂ݂̂��g���ă\�[�g����Ƃ��̎w��ł��B "2" �������w�肷��� �u 2 ��ڂ���Ō�܂Łv�Ƃ����Ӗ��ɂȂ�܂��B
�������g���l�h�Ƃ��ĔF������Ă��Ȃ��̂� �\�[�g�����ςł��B "-n" �I�v�V�����ŁA���l���g���l�h�ƔF�������܂��B
$ sort -k 2,2 -n score.txt sato 64 yamada 90 suzuki 93 tanaka 100
���ł� �l�̑傫�����i�~���j�ɂ��܂��B
$ sort -k 2,2 -n -r score.txt tanaka 100 suzuki 93 yamada 90 sato 64
�\�[�g�ł��܂����B
CSV �t�@�C���̂悤�ɗ�̋�蕶�����łȂ��Ƃ��� ���̂悤�� "-t" �I�v�V�����ŋ�蕶�����w��ł��܂��B
$ sort -k 2,2 -n -r -t "," score.txt
awk �R�}���h�Ńw�b�_�[��t�b�^�[���o�͂���
�e�L�X�g������ awk �Ƃ����R�}���h������܂��B
���̃R�}���h�A���Ȃ�֗��Ȃ̂ł����A �ł��邱�Ƃ����߂���̂Ŋo����̂͌��\��ς������肵�܂��B �u��{�I�Ȏg�����͂킩�邯�ǁE�E�E�v�Ƃ����l�������̂ł͂Ȃ��ł��傤���B �����ւ̃����̈Ӗ����܂߂ċ@�\���Љ�����Ǝv���܂��B
���̃e�L�X�g���������܂��B�i test.txt �j
1 2 3 4 5 6 7 8 9 10 11 12
�܂���{�I�Ȏg�����ł��B
$ cat test.txt | awk '{print $2}'
2
5
8
11
awk �̏����� {} �̑O�ɂ̓p�^�[�����������Ƃ��ł��܂��B
{} �̑O�ɉ��������Ȃ��̂́A�S�Ă̍s�Ƀ}�b�`�i�S�Ă̍s�ɑ��ď���������j�Ƃ����w��ɂȂ�܂��B �i����ɂ��Ă͂܂��ʂ̋@��ɏڂ������������Ǝv���܂��j
����́ABEGIN �� END �Ƃ�������Ȏw����g���܂����ABEGIN �́u�ŏ��̍s�̑O�v�Ƀ}�b�`����w��� END �́u�Ō�̍s�̌�v�Ƀ}�b�`����w��ł��B������g���ăw�b�_�[��t�b�^�[���o�͂��܂��B
���̂悤�Ȏw�肪�ł��܂��B
$ cat test.txt | \ > awk 'BEGIN {print "-- header --"} END {print "-- footer --"}' -- header -- -- footer --
BEGIN �� END �̎w�肵���Ȃ��̂ŁA�w�b�_�[�ƃt�b�^�[�݂̂��o�͂���܂����B
�v���O�����̕����������Ȃ�̂ŁA�ʃt�@�C���i prog.txt �j�Ɏw�肵�� �����œǂݍ��ނ悤�ɂ��܂��B
���̂悤�Ȏw������Ă݂܂��B
BEGIN {
print " f1 | f2 | f3 ";
print "----+----+----";
}
{
printf("%4d|%4d|%4d\n", $1, $2, $3);
}
BEGIN �i�O���j�� �S�Ă̍s�Ƀ}�b�`����w��i�㔼�j�����܂����B
���̂悤�Ȍ��ʂɂȂ�܂��B
$ cat test.txt | awk -f prog.txt f1 | f2 | f3 ----+----+---- 1| 2| 3 4| 5| 6 7| 8| 9 10| 11| 12
�w�b�_�[�Ɩ{�̂��o�͂���܂����B
���̓t�b�^�[�ɍ��v�s���o�������Ǝv���܂��B
awk �͌v�Z���ł��܂��B
BEGIN {
print " f1 | f2 | f3 ";
print "----+----+----";
f1=0;
f2=0;
f3=0;
}
{
printf("%4d|%4d|%4d\n", $1, $2, $3);
f1=f1+$1;
f2=f2+$2;
f3=f3+$3;
}
END {
print "----+----+----";
printf("%4d|%4d|%4d\n", f1, f2, f3);
}
������������ BEGIN �ɏ������Ƃ��ł��܂��B
���̂悤�Ȍ��ʂɂȂ�܂��B
$ cat test.txt | awk -f prog.txt
f1 | f2 | f3
----+----+----
1| 2| 3
4| 5| 6
7| 8| 9
10| 11| 12
----+----+----
22| 26| 30
���v�s���o�͂��邱�Ƃ��ł��܂����B
������Ƃ����Ƃ��ɃT�b�Ə�����ƃJ�b�R�ǂ��ł��ˁB
vi ���|���Ƃ��� view �R�}���h
�u�t�@�C���� vi �ŊJ���ƊԈ���ď㏑���ۑ����Ă��܂��̂��|���v�� ����ꂽ���Ƃ�����܂��B vi ���I������ۂ� ":wq" �Ƒł��Ă��܂������Ȃ̂ł��� ����ł͊m���ɍX�V�������ς���Ă��܂��܂��B
������ view �Ƃ����R�}���h������܂��B
$ view a.txt
���̃R�}���h�̓t�@�C���� vi �̓ǂݎ�胂�[�h�� "-R" �I�v�V������t������ԂŊJ���Ă���܂��B
���̏�Ԃł���� ":w" �ŕۑ����悤�Ƃ��Ă��u�ǂݎ���p�ł��v�ƃG���[�ɂȂ�܂��B ������ ":w!" �̂悤�ȋ����ۑ��͂ł��Ă��܂��̂Œ��ӂ��ĉ������B
vi �̑���ŕۑ������������Ȃ��A�Ƃ����Ƃ��Ɉ��S�ȃR�}���h�ł��B
Linux �� find �R�}���h���g���Ă݂�
find �R�}���h�� �F�X�ȏ����Ńt�@�C����T���ă��X�g���o�͂��Ă���� �֗��ȃR�}���h�ł��B �������A�S�ẴI�v�V������ �ƂĂ��o������܂���B �����ō���́g�Œ�����ꂾ���́h�Ƃ������e�ɍi���� �Љ�����Ǝv���܂��B
�p�X�̎w��
�܂��̓p�X�̎w��ł��B
find �R�}���h�͎w�肵���p�X�ȉ����������܂��B
�p�X�̎w������Ȃ��� �J�����g�f�B���N�g�����w�肵�����ƂɂȂ�܂��B �܂��A�p�X�̎w��ɂ���Č��ʂ̕\�����ς���Ă��܂��܂��B �i�I�v�V�����ŕύX���邱�Ƃ͂ł��܂����A����͊������܂��j
�Ⴆ�A�p�X���u���p�X�v�Ŏw�肵���ꍇ�A���̂悤�� ���ʂ̏o�͂����p�X�ɂȂ�܂��B
$ find ./hogehoge
./hogehoge
./hogehoge/a.txt
./hogehoge/b.txt
�u��p�X�v�Ŏw�肷��� ���ʂ���p�X�ɂȂ�܂��B
$ find /home/hogehoge
/home/hogehoge
/home/hogehoge/a.txt
/home/hogehoge/b.txt
���o�����̎w��
���ɒ��o�����ł��B
�����̏ꍇ�A�u�t�@�C�����v���u�X�V���v�ɂȂ�Ǝv���܂��B
�t�@�C������ "-name" �I�v�V������ �������w��ł��܂��B
$ find . -name "*.txt" ./hogehoge/a.txt ./hogehoge/b.txt
���̗�ł� "*.txt" �Ƀ}�b�`����t�@�C���݂̂𒊏o���܂����B �}�b�`���O�ɂ� "*" �� "?" ���g�����Ƃ��ł��܂��B
�������A�}�b�`���O�̑ΏۂɂȂ�̂̓p�X�̍Ō�̃G���g���[���i��̗�ł� "a.txt" �� "b.txt"�j�݂̂ŁA�r���̃p�X�͑ΏۂɂȂ�܂���B �f�B���N�g�����̂��Ō�̃G���g���[�̏ꍇ�́A���̃f�B���N�g������ �}�b�`���O�̑ΏۂɂȂ�܂��B
$ find . -name "hoge*" ./hogehoge
�X�V���� "-mtime" �I�v�V������ �t�@�C�����X�V����Ă���̎��Ԃ��w��ł��܂��B
$ find . -mtime +3 ./hogehoge/a.txt
�l�̎w��́A�v���X "+" �̏ꍇ �`���ȏ�O�i��̗�̏ꍇ 3 ���ȏ�O�j�� �}�C�i�X "-" �̏ꍇ �`���ȓ��ƂȂ�܂��B
$ find . -mtime -3 ./hogehoge ./hogehoge/b.txt
�����̎��s
�擾�����p�X�ɑ��ď������s�Ȃ������Ƃ�������܂��B
�Ⴆ�u 3 ���ȏ�O�� zip �t�@�C�����폜����v�Ƃ������ꍇ�ł��� �Ώۂ̎擾�� ���̂悤�ȃI�v�V�����Ŏw��ł��܂��B
$ find /var/backup -mtime +3 -name "*.zip" /var/backup/a.zip /var/backup/b.zip
����ɑ��ď���������킯�ł����� �C���[�W�Ƃ��Ă̓p�C�v���g���� ���̂悤�ɂȂ�܂��B
$ find /var/backup -mtime +3 -name "*.zip" | while read path > do > rm $path > done
��������� "-exec" �I�v�V�����Ŏw�肷�邱�Ƃ��ł��܂��B
$ find /var/backup -mtime +3 -name "*.zip" -exec rm {} \;
"-exec" �ȍ~�A"\;" �܂ł��R�}���h�ɂȂ�܂��B
"{}" �̕����Ɏ擾���ꂽ�p�X������܂��B
���̑��̃I�v�V����
���̑��̃I�v�V�����ŃI�X�X���Ȃ̂� "-ls" �ł��B ���̃I�v�V������t����ƌ��ʂ̏o�͂� ls �R�}���h�Ɠ����悤�� �`�ɂ��Ă���܂��B
$ find . -ls 10767946 12 drwxr-xr-x 1 u g 4096 11�� 20 2009 ./hogehoge 10768066 4 -rw-r--r-- 1 u g 512 11�� 15 2009 ./hogehoge/a.txt 10768041 4 -rw-r--r-- 1 u g 512 11�� 20 2009 ./hogehoge/b.txt
���ɂ��F�X�ȃI�v�V����������܂��� �u�ǂ����Ă��g��Ȃ��ƂȂ�Ȃ��v�Ƃ�����ʈȊO�ł� ���̃R�}���h�Ƒg�ݍ��킹�Ďg������ �V���v���Ō��₷���Ȃ�Ǝv���܂��B
Bash �Ōv�Z���Ă݂�
sh �Ȃǂł͕ϐ����v�Z�Ɏg�p�ł��Ȃ����� ���̂悤�� expr �R�}���h���g���Čv�Z���܂��B
$ echo `expr 3 + 22` 25
$ A=15 $ B=`expr $A - 12` $ echo $B 3
Bash �ł� $ + ��d�J�b�R "$(( ))" �Ōv�Z���ł��܂��B
$ echo $((3 + 22)) 25
$ A=15 $ B=$(($A - 12)) $ echo $B 3
�J�b�R���̕ϐ��� $ ���ȗ��ł��܂��B
$ A=15 $ B=$((A - 12)) $ echo $B 3
�v�Z���邾���̏ꍇ�A�J�b�R�̑O�� $ �͕s�v�ł��B
$ A=15 $ ((B = A * 2)) $ echo $B 30
Linux �� echo �ʼn��s�����Ȃ�
�g�p������́A���傱���傱�o���Ă����̂ł��� ��������ɒP�ƂŃl�^�ɂ��Ă����܂��B
�I�v�V������t������ echo ���g���� �s���ɉ��s���t���܂��B
$ echo ABC; echo XYZ
ABC
XYZ
"-n" �I�v�V������t���邱�Ƃ� ���s�Ȃ��ɂł��܂��B
$ echo -n ABC; echo -n XYZ ABCXYZ
cal �R�}���h�Ō��j����擪�ɂ���
cal �R�}���h�� �J�����_�[��\�����邱�Ƃ��ł��܂��B
$ cal 5�� 2010 �� �� �� �� �� �� �y 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 $ cal 9 2010 9�� 2010 �� �� �� �� �� �� �y 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
.bash_profile �ɓ���ă��O�C�����ɃJ�����_�[��\���������� ������Ɨj����m�肽�����Ɏg����R�}���h�ł��B
�����A���̏ꍇ �J�����_�[�͌��j�����擪�Ȃ̂��������̂ł��� �ŋ߂� cal �͂���ȃI�v�V���� "-m" ������悤�ł��B
$ cal -m 5�� 2010 �� �� �� �� �� �y �� 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
���ɂ��N�P�ʂ̕\����D�D�D
$ cal -y 2010 1�� 2�� 3�� �� �� �� �� �� �� �y �� �� �� �� �� �� �y �� �� �� �� �� �� �y 1 2 1 2 3 4 5 6 1 2 3 4 5 6 3 4 5 6 7 8 9 7 8 9 10 11 12 13 7 8 9 10 11 12 13 10 11 12 13 14 15 16 14 15 16 17 18 19 20 14 15 16 17 18 19 20 17 18 19 20 21 22 23 21 22 23 24 25 26 27 21 22 23 24 25 26 27 24 25 26 27 28 29 30 28 28 29 30 31 31 4�� 5�� 6�� �� �� �� �� �� �� �y �� �� �� �� �� �� �y �� �� �� �� �� �� �y 1 2 3 1 1 2 3 4 5 4 5 6 7 8 9 10 2 3 4 5 6 7 8 6 7 8 9 10 11 12 11 12 13 14 15 16 17 9 10 11 12 13 14 15 13 14 15 16 17 18 19 18 19 20 21 22 23 24 16 17 18 19 20 21 22 20 21 22 23 24 25 26 25 26 27 28 29 30 23 24 25 26 27 28 29 27 28 29 30 30 31 7�� 8�� 9�� �� �� �� �� �� �� �y �� �� �� �� �� �� �y �� �� �� �� �� �� �y 1 2 3 1 2 3 4 5 6 7 1 2 3 4 4 5 6 7 8 9 10 8 9 10 11 12 13 14 5 6 7 8 9 10 11 11 12 13 14 15 16 17 15 16 17 18 19 20 21 12 13 14 15 16 17 18 18 19 20 21 22 23 24 22 23 24 25 26 27 28 19 20 21 22 23 24 25 25 26 27 28 29 30 31 29 30 31 26 27 28 29 30 10�� 11�� 12�� �� �� �� �� �� �� �y �� �� �� �� �� �� �y �� �� �� �� �� �� �y 1 2 1 2 3 4 5 6 1 2 3 4 3 4 5 6 7 8 9 7 8 9 10 11 12 13 5 6 7 8 9 10 11 10 11 12 13 14 15 16 14 15 16 17 18 19 20 12 13 14 15 16 17 18 17 18 19 20 21 22 23 21 22 23 24 25 26 27 19 20 21 22 23 24 25 24 25 26 27 28 29 30 28 29 30 26 27 28 29 30 31 31
�O�� 1 �������̕\��������܂��B
$ cal -3 4�� 2010 5�� 2010 6�� 2010 �� �� �� �� �� �� �y �� �� �� �� �� �� �y �� �� �� �� �� �� �y 1 2 3 1 1 2 3 4 5 4 5 6 7 8 9 10 2 3 4 5 6 7 8 6 7 8 9 10 11 12 11 12 13 14 15 16 17 9 10 11 12 13 14 15 13 14 15 16 17 18 19 18 19 20 21 22 23 24 16 17 18 19 20 21 22 20 21 22 23 24 25 26 25 26 27 28 29 30 23 24 25 26 27 28 29 27 28 29 30 30 31
Linux �� cd ����O�̃f�B���N�g���ɖ߂�
���̂��������l�^�ł��� �m���Ă���ƕ֗��ł��B
cd �R�}���h�̓f�B���N�g�����ړ����邱�Ƃ��ł��܂��B
~:$ cd /var/log/apache2 /var/log/apache2:$ cd /etc/apache2/conf.d /etc/apache2/conf.d:$
1 �O�̃f�B���N�g���ɖ߂肽���Ȃ����Ƃ��� ���̂悤�� �p�X�̑���Ƀn�C�t�� "-" ���w�肵�܂��B
/etc/apache2/conf.d:$ cd - /var/log/apache2:$
�����Ŏ����Ă���킯�ł͂Ȃ��̂� �J��Ԃ��n�C�t�����w�肵�Ă� 2 �̃f�B���N�g�����s�������邾���ł��B
/etc/apache2/conf.d:$ cd - /var/log/apache2:$ cd - /etc/apache2/conf.d:$ cd - /var/log/apache2:$
���O�Ɛݒ�t�@�C���̃f�B���N�g���� �s��������Ƃ��ȂǕ֗��ł��B
chown �R�}���h�ŃO���[�v���ύX����
Unix/Linux �ɂ� �t�@�C���̏��L����ύX���� chown �Ƃ����R�}���h������܂��B ���̃R�}���h�� ���[�U�����łȂ��O���[�v�������ɕύX���邱�Ƃ��ł��܂��B
���L���̃��[�U�����ς��鏑���͎��̂悤�ɂȂ�܂��B
# chown testuser1 /home/testuser1/test.txt
�O���[�v�������ɕς���ꍇ�� �R���� ":" �ŋ���� �O���[�v�����w�肵�܂��B
# chown testuser1:testgroup1 /home/testuser1/test.txt
GNU �łł́A�R�����̑���� �h�b�g "." ���g���܂��� �v���L�V�̔F�Ȃǃ��[�U�̋��� �R�����͂悭�g�p����̂� �R�����Ŋo���Ă�����������Ǝv���܂��B
���[�U���ƃR���������� �O���[�v�����w�肵�Ȃ��ꍇ�� �w�肵�����[�U���i���̏ꍇ�� testuser1 �j�� ���O�C���O���[�v���w�肵�����ƂɂȂ�܂��B
# chown testuser1: /home/testuser1/test.txt
���O�C���O���[�v�ׂȂ��Ă��ǂ��̂� �o���Ă����ƕ֗��ł��B
��̗�Ƃ͋t�Ƀ��[�U�����w�肵�Ȃ��ꍇ�� �O���[�v�̕ύX�ɂȂ�܂��B ����� chgrp �Ɠ����ł��B
# chown :testgroup1 /home/testuser1/test.txt
�I�}�P�ł����Acp �Ȃǂ̃R�}���h�Ɠ��l�� -R �I�v�V�����ōċA�i�T�u�f�B���N�g���ȉ��ɂ��K�p�j���ł��܂��B
# chown -R testuser1:testgroup1 /home/testuser1
�p�X���[�h���ꊇ�ŕύX����
Linux �ɂ� �p�X���[�h���ꊇ�ŕύX�ł��� chpasswd �Ƃ����R�}���h������܂��B �g�����͊ȒP�ŕW�����͂��烆�[�U���ƃp�X���[�h�̃Z�b�g��n�������ł��B
�Ⴆ�� testuser1 �̃p�X���[�h�� hogehoge �ɂ���ꍇ ���̂悤�� ���[�U���ƃp�X���[�h���R�����ŋ���ăp�C�v���܂��B
# echo "testuser1:hogehoge" | chpasswd
�������[�U�̃p�X���[�h���ꊇ�ŕύX����ꍇ ���̂悤�� �t�@�C���Ƀ��[�U���ƃp�X���[�h�̃Z�b�g���L�q���܂��B
# vi passwd.txt
testuser1:hogehoge1 testuser2:hogehoge2 testuser3:hogehoge3
������p�C�v�œn���܂��B
# cat passwd.txt | chpasswd
�S���[�U�̃p�X���[�h���ꊇ�ŏ���������ꍇ�ȂǕ֗��ł��B
Bash �� �z����g���Ă݂� ���� 2
�O��i Bash �� �z����g���Ă݂� ���� 1 �j�͒l�̊i�[�ł����� ����͔z��炵�� for ���[�v���g���Ēl���o�͂��܂��B
�܂��� ���ʂ́H for ���ł��B �z��̒l��S�ďo�͂���ɂ͎��̂悤�� �Y������ "@" �� "*" ���g���܂��B
$ ARRAY=(one two three four) $ echo ${ARRAY[@]} one two three four $ echo ${ARRAY[*]} one two three four
����� for ���Ŏg�p���܂��B
$ ARRAY=(one two three four) $ for item in ${ARRAY[@]} > do > echo $item > done one two three four
�������A����� 1 ��肪����܂��B
Bash �� for �� ���� 2 �ŏ����܂����� for ���� IFS (�f�t�H���g�̓X�y�[�X�Ȃ�) �ŋ��ꂽ������Ń��[�v�����邱�Ƃ��ł���̂� �z��̗v�f�� IFS ���܂ޕ�����̏ꍇ�A���̂悤�Ƀ��[�v�������Ă��܂��܂��B
$ ARRAY=("one1 one2 one3" two three four) $ echo ${ARRAY[0]} one1 one2 one3 $ for item in ${ARRAY[@]} > do > echo $item > done one1 one2 one3 two three four
�����h�����߂Ƀv���O��������̂悤�� for �����g�p���܂��B
�z��̓Y�����̍ő���擾����ɂ͎��̂悤�ɂ��܂��B
$ ARRAY=("one1 one2 one3" two three four) $ echo ${#ARRAY[@]} 4 $ echo ${#ARRAY[*]} 4
����� for ���Ŏg�p���܂��B
$ ARRAY=("one1 one2 one3" two three four) $ for (( i = 0; i < ${#ARRAY[@]}; i++ )) > do > echo ${ARRAY[$i]} > done one1 one2 one3 two three four
1 �߂̔z����������o�͂���܂����B
Bash �� �z����g���Ă݂� ���� 1
�܂��͒l�̊i�[�ł��B ���� 1 ���w�肷����@�ł��B
$ A[0]=one $ A[1]=two
������͈ꊇ�Ŏw�肷����@�ł��B
$ A=(one two three four)
�z��̒l���o�͂���ɂ� "{}" �i�u�����P�b�g�j�� �g�p����K�v������܂��B
$ echo ${A[0]}
�u�����P�b�g���w�肵�Ȃ��� �ϐ� "$A" �� "[0]" �Ƃ��������̏o�͂ɂȂ��Ă��܂��܂��B
���Ȃ݂� ���̂悤�ɓY���� 0 �̒l�� �Y�������w�肵�Ȃ��ϐ��̒l�Ɠ����ɂȂ�܂��B
$ echo ${A[0]} one $ echo $A one
�ł��̂Ńu�����P�b�g���g�p���Ȃ��ꍇ�͎��̂悤�ɏo�͂���܂��B
$ echo $A[0]
one[0]
IFS (Internal Field Separator) �̒l��\������
Bash �� for �� ���� 2 �� IFS ���o������ł����A �f�t�H���g�� IFS �̒��g��\�����邱�Ƃ��ł��Ȃ����Ȃ� �l���Ă��܂����B
���ʂɏo�͂��Ă����̂悤�ɂȂ��Ă��܂��܂��B
$ echo "[$IFS]"
[
]
���̃T�C�g�ɗǂ����@���ڂ��Ă��܂����B
�y�Q�l�T�C�g�z
IFS - http://www.curri.miyakyo-u.ac.jp/pub/doc/sh/node31.html
$ echo -n "$IFS" | od -b 0000000 040 011 012 0000003 $ echo -n "$IFS" | od -c 0000000 \t \n 0000003
040 011 012 �� 8�i���ł��B
�l�Ƃ��Ă� �X�y�[�X�i0x20�j�A�����^�u�i0x09�j�A���s�i0x0A�j�ɂȂ�܂��B
Bash �� for �� ���� 2
Bash �� for �� �̑����ł��B
��������̃��X�g
���̂悤�ɕ�����̋ŋ��ꂽ���ڂ����X�g�Ƃ��� ���[�v�����邱�Ƃ��ł��܂��B
$ ITEMS="one two three four" $ for item in $ITEMS > do > echo $item; > done; one two three four
�������͋ł͂Ȃ� IFS (Internal Field Separator) �Œ�`����Ă�����̂� ����������܂��B IFS ��ύX����Ƌ���ς��邱�Ƃ��ł��܂��B
$ ITEMS="one/two/three four" $ IFS="/" $ for item in $ITEMS > do > echo $item; > done; one two three four
�����̃��X�g
���Ɉ����̃��X�g�Ń��[�v������Ƃ����̂�����܂��B
$ function test () { > for item in $* > do > echo $item; > done; > } $ test one two three four one two three four
Bash �� for ��
Bash �Ŏg���� for ���ɂ͐F�X�Ȍ`������܂��B
���̃��X�g
$ for item in one two three four > do > echo $item > done one two three four
in �̌�ɕ��ׂ��l�����[�v�����܂��B
�f�B���N�g���E�t�@�C���̃��X�g
$ for item in /tmp/* > do > echo $item > done /tmp/aaaa.txt /tmp/bbbb.txt
�}�b�`���� �f�B���N�g����t�@�C���̃p�X�Ń��[�v�����܂��B
�R�}���h�̌��ʂ̃��X�g
$ for item in $(wc /tmp/a.txt) > do > echo $item > done 0 3 9
�R�}���h�u�����g���āA���s���ʂŃ��[�v�����܂��B
����𗘗p���� seq �R�}���h���g�����@������܂��B
$ for item in $(seq 1 3) > do > echo $item > done 1 2 3
Java �Ȃǂ̌���ɂ悭���� for ��
����ł悭�݂����� ����������J��Ԃ������� �Z�~�R�����ŋ���Ă�`�����g���܂��B
$ for (( item = 0; item < 3; item++ )) > do > echo $item > done 0 1 2
��d�J�b�R (()) ���g���܂��B
Bash �� �v�����v�g�̐F��ς���
SSH �ȂǂŃT�[�o�Ƀ��O�C������ ����ɂ�������ʂ̃T�[�o�Ƀ��O�C�������肷��� �������ǂ̃T�[�o��G���Ă��邩�킩��Ȃ��Ȃ�Ƃ�������܂��B
�v�����v�g�Ƀz�X�g����\������Ȃǂ� ������悤�ɂ��Ă� �w�i�Ɖ����Ă��܂��̂� �g�{�Ԋ������́I�h�Ƃ����Ƃ��� �v�����v�g�̐F��ς���Ƃ����̂͂ǂ��ł��傤���B
$ PS1="\[\033[0;31m\][\u@\h:\w]$\[\033[0m\] " $ PS2="\[\033[0;31m\]>\[\033[0m\] "
����Ȋ����Őݒ肵�܂��B PS1 �͒ʏ�̃v�����v�g�APS2�́A���͂������Ă���ꍇ�̃v�����v�g�ł��B
�ݒ肷��Ǝ��̂悤�ɂȂ�܂��B
[user1@host1:~]$ [user1@host1:~]$ cd \ > /usr/local/share [user1@host1:/usr/local/share]$
�ˑR�ڂɔ�э���ł���ԐF�Ƀh�L�b�Ƃ������܂��B
Bash �� �R�}���h�u��
Bash �̃R�}���h�u���ɂ́A"`" �i�o�b�N�N�H�[�g�j���g���`���� "$()" ���g���`���� 2 ��ނ�����܂��B
$ echo `pwd` /usr/local $ echo $(pwd) /usr/local
"$()" �̌`���̕����V�����悤�ł��B
���� 2 �́A��{�������������܂����A�o�b�N�X���b�V���ɂ��G�X�P�[�v�̏������Ⴂ�܂��B ���̂悤�ɂȂ�܂��B
$ AA=abc $ echo `echo $AA` abc $ echo `echo \$AA` abc $ echo $(echo $AA) abc $ echo $(echo \$AA) $AA
Bash �̕�����̕��������擾����
���̂悤�ȕϐ�������܂��B
$ K="abc def gh"
wc �R�}���h�ŕ��������擾�ł��܂��� echo ���邾���ł͍s���ɉ��s�������Ă��܂��̂� "-n" �I�v�V������t����K�v������܂��B
$ echo -n $K | wc -m
10
���̑��� "#" ��t�������������܂��B
$ echo ${#K}
10
"#" �́A�ϐ����z��̏ꍇ�͗v�f�����擾�ł��܂��� �ϐ���������̏ꍇ�A���������擾���邱�Ƃ��ł��܂��B
$ K="������" $ echo ${#K} 3
Linux �ōs�����擾����
Unix/Linux �ɂ� wc �Ƃ����R�}���h������ �s����o�C�g���A�P�ꐔ���擾���邱�Ƃ��ł��܂��B
$ wc -l test.txt
558 test.txt
"-l" �̃I�v�V������ �s�����擾�ł��܂��B
�t�@�C�������łȂ��A�R�}���h�̌��ʂ� �p�C�v�œn�����Ƃ��ł��܂��B
$ cat test.txt | sort | wc -l
558
grep �������ʂ��������邩�A�Ȃǂɂ��g�����Ƃ��ł��܂��B
$ RESULT=`cat test.txt | grep keyword | wc -l` $ echo $RESULT 32
sudo: sorry, you must have a tty to run sudo
sudo �� cron �Ȃǂ���o�b�`�����Ŏg�p���悤�Ƃ���� ���̂悤�ȃG���[���������邱�Ƃ�����܂��B
sudo: sorry, you must have a tty to run sudo
�u�[��������s���Ȃ��ƃ_���v�ƌ����Ă�̂ł��� �ǂ����Ă� cron �Ŏ��s�������ꍇ�́A sudo �̐ݒ�t�@�C�� /etc/sudoers �� Defaults requiretty �p�����[�^���C�����܂��B
/etc/sudoers �� visudo �ŕҏW���܂��B
# visudo
�y�ύX�O�z Defaults requiretty �y�ύX�O�z Defaults !requiretty
����̃��[�U�̂��������ꍇ�͎��̂悤�ɐݒ肵�܂��B
Defaults:hogehoge !requiretty
����ŁA���[�U hogehoge �� �[���Ȃ��� sudo �ł��܂��B
�I�[�v���\�[�X�J���t�@�����X2010 Kansai@Kobe 3/13
�I�[�v���\�[�X�J���t�@�����X (OSC) �� 3/13 (�y) �� �_�˂ŊJ�Â���邱�ƂɂȂ�܂����B
�I�[�v���\�[�X�J���t�@�����X2010 Kansai@Kobe - Beef Up Kobe!
���� ���s�ŊJ�Â���Ă��܂����� �_�˂��lj����ꂽ�悤�ł��B
�ȉ��́A�����ǂ���̈ē����[���̔����ł��B
������ --�y�I�[�v���\�[�X�J���t�@�����X2010 Kansai@Kobe�z-- ������ ���Z�~�i�[�Q���o�^��t���I�ˁˁ� http://www.ospn.jp/osc2010-kobe/ �������F3��13��(�y)10:00-18:00 ������F���� �����F�_�ˎs�Y�ƐU���Z���^�[ (���Ɍ��_�ˎs) ����ÁF�I�[�v���\�[�X�J���t�@�����X���s�ψ��� �����ÁF�n��ICT���i���c��iCOPLI�j �����e�F�I�[�v���\�[�X�֘A�̍ŐV���� (�W���E�Z�~�i�[)
������N�� 7���� Kansai@Kyoto ���J�Â���܂��I
7/9 (��) 7/10 (�y) @���s�R���s���[�^�w�@ �ł��B
�v�����v�g�Ɏ��s���ʂ�\������
�V�F�� (bash) �̃v�����v�g�����̃l�^�ł��B
�v�����v�g�� ���ϐ� PS1 ��ύX���邱�Ƃ� �\�����e�����R�ɕς��邱�Ƃ��ł���̂ł��� ����� �R�}���h�Ȃǂ̎��s���� ($?) ��\�������Ă݂܂��B
$ PS1="\u:\w[code:\$?]$ " hogehoge:~[code:0]$
����� OK �ł��B
���̂悤�� �G���[����������� �G���[�R�[�h���\������܂��B
hogehoge:~[code:0]$ ls aaaaaaa ls: aaaaaaa: ���̂悤�ȃt�@�C����f�B���N�g���͂���܂��� hogehoge:~[code:2] $
.bashrc �Ȃǂł킴�킴�ݒ肷��K�v�͂���܂��� �V�F�����쐬����Ƃ��� �ꎞ�I�ɐݒ肷��� ���ʂ��m�F���₷���Ȃ�܂��B
�V�F���ŕ�����̃}�b�`���O
�V�F���ŕ�����̃}�b�`���O����ɂ́A�V�F���̍\�������ł͂ł��Ȃ��̂� ���̂悤�� test �����܂��g���܂��B
$ if [ ! -z `echo $������ | grep "�p�^�[��"` ]; then
"-z" �́A������̒����� 0 �Ȃ�^�ɂȂ�I�v�V�����ł��B �o�b�N�N�H�[�e�[�V�������� echo ���������� �p�^�[���Ƀ}�b�`����� ���̕������Ԃ��̂� ������r�ɗ��p���Ă��܂��B
$ FILE=test_file_0209.csv $ if [ ! -z `echo $FILE | grep "^test_file_....\.csv$"` ]; then > echo "match" > else > echo "no match" > fi match
�Ƃ����������ɂȂ�܂��B
perl �̐��K�\�����g�������ꍇ�� "-P" �I�v�V������t���܂��B
$ if [ ! -z `echo $������ | grep -P "�p�^�[��"` ]; then
sudo �� ���ϐ��������p��
sudo ���g���� root �̌����ŃR�}���h�����s���邱�Ƃ��ł��܂��� �f�t�H���g�̐ݒ�ł́A���ϐ����ς���Ă��܂����� �������� root �ɂ��邱�Ƃ��ł��܂���B
�Ƃ����킯�ŁA���ϐ��������p���悤�ɂ��Ă݂܂��B
sudo �̐ݒ�t�@�C�� /etc/sudoers �� visudo �ŕҏW���܂��B
# visudo
���̂悤�ȉӏ�������܂��B
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE INPUTRC KD
LS_COLORS MAIL PS1 PS2 QTDIR USERNAME \
LANG LC_ADDRESS LC_CTYPE LC_COLLATE LC_IDEN
LC_MEASUREMENT LC_MESSAGES LC_MONETARY LC_N
LC_PAPER LC_TELEPHONE LC_TIME LC_ALL LANGUA
_XKB_CHARSET XAUTHORITY"
����͈����p�����ϐ���ݒ肵�Ă��܂��B
����̃��[�U (testuser1) �ŁA�S�Ă̊��ϐ��������p���ɂ� ���̂悤�ȍs��lj����܂��B
Defaults:testuser1 !env_reset
testuser1 �� sudo ���g���� ���ϐ��������p���ł���܂��B
sudo �� �p�X���[�h����Ȃ��悤�ɂ���
sudo �R�}���h���g�p����Ƃ��� �p�X���[�h����Ȃ��悤�ɂ���ݒ�̃����ł��B
sudo �̐ݒ�t�@�C���� /etc/sudoers �ł��� �ҏW����Ƃ��́A���ڊJ���̂ł͂Ȃ� visudo �Ƃ����R�}���h���g�p���܂��B
ALL ALL=(ALL) NOPASSWD: ALL
������A���[�U�A�z�X�g�A�����A�R�}���h�Ȃ̂ł����A �R�}���h�� NOPASSWD: �ƕt���邱�ƂŃp�X���[�h��������Ȃ��Ȃ�܂��B
����̃��[�U�ɑ��� ����̃R�}���h�݂̂����������ꍇ�� ���̂悤�ɋL�q���܂��B
user1 ALL=(ALL) NOPASSWD: /etc/init.d/httpd
����� user1 �� httpd �̎��s���ł���悤�ɂȂ�܂��B
�����t�@�C���̈ꊇ�u��
Linux �����̃e�L�X�g�t�@�C���̕�������ꊇ�� �u�����邽�߂̃V�F���X�N���v�g������Ă݂܂����B
#!/bin/bash # ========================================================== # �����t�@�C���ꊇ�u���R�}���h # ----------------------------------------------------- # create : 2010/01/21 Studio ODIN # update : # ========================================================== # --- init --------------------------------------------- COMMAND_NAME=bulk_replace CUR_DIR=`pwd` # -- args ---------------------------------------------- TARGET_WORD=$1 REPLACE_WORD=$2 TARGET_DIR=$3 # -- args check ---------------------------------------- if [ "$TARGET_WORD" = "" ]; then echo "target word is nothing." >&2 echo "Usage: $0 targetword replaceword [targetpath]" >&2 exit 1 fi if [ "$REPLACE_WORD" = "" ]; then echo "replace word is nothing." >&2 echo "Usage: $0 targetword replaceword [targetpath]" >&2 exit 1 fi if [ "$TARGET_DIR" = "" ]; then TARGET_DIR=. fi # -- execute ------------------------------------------- grep -R -l "${TARGET_WORD}" "${TARGET_DIR}" | while read file do tfile=`mktemp -u` cp -f -p $file $tfile > /dev/null 2>&1 if [ $? -eq 0 ]; then sed -e "s/${TARGET_WORD}/${REPLACE_WORD}/g" $file > $tfile if [ $? -ne 0 ]; then echo "Warning: failed write '$file'" fi mv -f $tfile $file > /dev/null 2>&1 if [ $? -ne 0 ]; then echo "Warning: failed rewrite '$file'" rm -f $tfile > /dev/null 2>&1 fi else echo "Warning: failed copy '$file'" fi done # -- normal end ---------------------------------------- cd $CUR_DIR exit 0 # ========================================================== # shell end # location: /usr/local/bin/bulk_replace # ==========================================================
���s����ꍇ�́A�p�X�̎w��ȂǑ厖�ȃt�@�C���� ��ςȂ��ƂɂȂ�Ȃ��悤�ɋC��t���Ă��������B �i���ȐӔC�ł��肢���܂��j
����ȃR�}���h�́A���łɂ���悤�ȋC�����܂��� �����ŏ������l���č���Ă݂�͖̂ʔ����Ǝv���܂��B
���p�X�����p�X���擾����
Linux �� realpath �Ȃǂ������Ă��Ȃ��� ���p�X�����p�X���擾���邽�߂� �V�F���X�N���v�g�ł��B
#!/bin/bash # ========================================================== # ��p�X�擾�R�}���h # ----------------------------------------------------- # create : 2010/01/07 Studio ODIN # update : # ========================================================== # --- init --------------------------------------------- COMMAND_NAME=fullpath CUR_DIR=`pwd` # -- args ---------------------------------------------- TARGET_OBJECT=$1 # -- args check ---------------------------------------- if [ "$TARGET_OBJECT" = "" ]; then pwd exit 0 fi if [ ! -e "$TARGET_OBJECT" ]; then echo "Error: '$TARGET_OBJECT' is not exists." >&2 exit 1 fi # -- get full path (is directory) ---------------------- if [ -d $TARGET_OBJECT ]; then cd $TARGET_OBJECT pwd exit 0 fi # -- get full path (is not directory) ------------------ cd `dirname $TARGET_OBJECT` TARGET_PATH=`pwd` TARGET_NAME=`basename $TARGET_OBJECT` if [ "$TARGET_PATH" = "/" ]; then echo $TARGET_PATH$TARGET_NAME else echo $TARGET_PATH/$TARGET_NAME fi # -- normal end ---------------------------------------- cd $CUR_DIR exit 0 # ========================================================== # shell end # location: /usr/local/bin/fullpath # ==========================================================
���̗�́Afullpath �Ƃ������O�� /usr/local/bin �ɍ쐬���Ď��s������t���Ă��܂��B ���ɍ��킹�ĕύX���Ă��������B
# cd /usr/local/bin # vi fullpath # chmod 755 fullpath
�������w�肵�Ȃ���A�J�����g�f�B���N�g���̃p�X�A �f�B���N�g����t�@�C�����w�肷��A���̐�p�X��Ԃ��܂��B
$ fullpath /home/odin $ fullpath ../ /home $ fullpath / / $ fullpath ../../vmlinuz /vmlinuz
Debian �� Go ����������Ă݂�
Google �� ���\���� Go ����� �Ƃ肠���������Ă݂܂��B
�����Q�l�ɂ��ăC���X�g�[�����Ă����܂��B
���� Go ����������Ă݂�I (IT��L)
���Ȃ݂Ɋ��� Debian Linux �ł��B
�R���p�C���Ȃǂ������ĂȂ��ꍇ�́A�C���X�g�[�����܂��B
# apt-get install bison gcc libc6-dev ed make
Mercurial ���C���X�g�[�����܂��B
# apt-get install python-setuptools python-dev # easy_install mercurial
Go ����ŊJ�����郆�[�U�̊��ϐ���ݒ肵�܂��B
.bashrc �Ȃǂɏ����Ă����܂��B
export GOOS=linux export GOARCH=386 export GOROOT=$HOME/go export GOBIN=$HOME/bin export PATH=$GOBIN:$PATH
GOOS �́ALinux �Ȃ� "linux"�AMac OS X �Ȃ� "darwin" ��ݒ肵�܂��B GOARCH �́A32-bit x86 �Ȃ� "386" ��ݒ肵�܂��B
�J���p�̃f�B���N�g�����쐬���܂��B
$ mkdir ~/go $ mkdir ~/bin $ mkdir -p ~/dev/go
�\�[�X�R�[�h���擾���܂��B
$ hg clone -r release https://go.googlecode.com/hg/ $GOROOT
�r���h���܂��B
$ cd $GOROOT/src $ ./make.bash
"hello world" �� �o�͂���v���O�������쐬���܂��B
�\�[�X�t�@�C���� hello.go �Ƃ��܂��B
$ cd ~/dev/go $ vi hello.go
package main
import "fmt"
func main() {
fmt.Printf("hello world\n")
}
386 �̏ꍇ�A8g �R�}���h�ŃR���p�C�����܂��B amd64 �� 6g�Aarm�Ȃ� 5g �ł��B
$ 8g hello.go
�ł��� hello.8 �Ƃ����t�@�C���� 8l �R�}���h�� �����N���܂��B
$ 8l hello.8
8.out �Ƃ������s�t�@�C�����ł���̂Ŏ��s���܂��B
$ ./8.out
hello world
����ŏI���ł��B
$GOBIN �ɂ́A8g 8l �̑��ɂ� 8c 8a �Ȃǂ̃R�}���h���쐬����Ă��܂��B 8c �� C �̃R���p�C���p�̂悤�ł��� 8a �̓A�Z���u���ł��傤���H (���m�F)
sl �R�}���h
��UNIX���w�тȂ���������̂��낢�� (�ς̉���)
���̋L����ǂ�Ŏv���o�����̂ł��� sl �Ƃ����R�}���h������܂��B ���s����� ���̂悤�� SL ����ʂ𑖂�ʂ����܂��B
==== ________ ___________
_D _| |_______/ \__I_I_____===__|_________|
|(_)--- | H\________/ | | =|___ ___|
/ | | H | | | | ||_| |_||
| | | H |__--------------------| [___] |
| ________|___H__/__|_____/[][]~\_______| |
|/ | |-----------I_____I [][] [] D |=======|__
__/ =| o |=-~~\ /~~\ /~~\ /~~\ ____Y___________|__
|/-=|___|| || || || |_____/~\___/
\_/ \__/ \__/ \__/ \__/ \_/
�K�`���K�`���� �f�B���N�g�����ړ����Ȃ��� �t�@�C����T���Ă���Ƃ��Ȃ� ls �R�}���h���ԈႦ�� sl �Ƒł��Ă��܂����Ƃ�����܂��B �i���Ȃ��Ƃ����́A�悭����܂��E�E�E�j ���̃R�}���h�������Ă���ƁASL ������ʂ���܂� �{�[���Ɖ�ʂ����邱�ƂɂȂ�܂��B
�W���[�N�R�}���h�̂悤�ł����A���݂��Ȃ��R�}���h�� �ł� PATH ����S�ĒT������ �̂̃R���s���[�^�ł� ���Ԃ�������A�_�~�[�� sl �R�}���h�����Ă����A �Ƃ����̂��N���̂悤�ł��B �i�������A���̃R�}���h�̏ꍇ�� �t�Ɏ��Ԃ�������܂��j
���Ȃ݂ɁADebian �ł́A�p�b�P�[�W���p�ӂ���Ă��܂��B
# apt-get install sl
-a, -l -F �̃I�v�V�����ŕω����܂��B
�ŋ߂� JavaScript�� �܂ł���悤�ł��B
Linux �� �R�}���h���C���œY�t�t�@�C���t�����[�����M
mutt �Ƃ����R�}���h�� �ȒP�ɓY�t�t�@�C���t���� ���[���𑗐M���邱�Ƃ��ł��܂��B
yum �̏ꍇ�A���̂悤�ɃC���X�g�[���ł��܂��B
# yum install mutt
���̃R�}���h�ŁA�{���Ɂumessage�v�A�����Ɂusubject�v�A �Y�t�t�@�C���utest.txt�v��t���� �uxxx@example.com�v�Ƀ��[���𑗐M���܂��B
$ echo "message" | mutt -a test.txt -s "subject" xxx@example.com
�T�[�o���烍�O�t�@�C���𑗂�ꍇ�ȂǕ֗��ł��B
Linux �� CD ���� ISO �C���[�W�����
Linux �� CD ���� ISO �C���[�W�����ɂ� dd �R�}���h���g�������Ȃ̂ŊȒP�ł��B
# dd if=/dev/cdrom of=./image.iso
���������ꂾ���ł��B
����� ISO �C���[�W�� �}�E���g���邱�Ƃ��ł��܂��B
# mount -o loop ./image.iso /mnt/cdrom
���������ꂾ���ł��B
1 ���ȏ�O�ɍX�V���ꂽ�t�@�C������������
������ƃn�}�����̂Ń����ł��B
Linux �� find �R�}���h�� mtime �I�v�V������ �t�@�C���̍X�V�����w�肵�Č������邱�Ƃ��ł��܂��B ����� "+/-" �ŁA������O/����w�肷�邱�Ƃ��ł��܂��B
$ find -mtime +1
�܂肱��� 1 ���ȏ�O ( 24 ���Ԃ��O ) �Ƃ������Ƃ� �Ȃ�悤�ȋC������̂ł��� ���ۂɂ͂����Ȃ�܂���B
����Ɋւ��Ăł����A���̂悤�� 1 �������w�肷��� �X�V���Ă���u 24 ���ԁ` 47 ���� 59 ���v�̃t�@�C���� �ΏۂɂȂ�킯�ł��B
$ find -mtime 1
�����āA24 ���Ԉȓ��̍X�V�t�@�C����ΏۂƂ���ꍇ ���̂悤�� 0 ���w�肵�܂��B
$ find -mtime 0
�܂� +1 �́u 47 ���� 59 ���v���O�Ƃ������ƂȂ̂� �����I�ɂ� 2 ���O�Ƃ������ƂɂȂ�܂��B ������ 1 ���ȏ�O�̃t�@�C������������ɂ� +1 �ł͂Ȃ� +0 ���w�肵�Ȃ��Ă͂Ȃ�܂���B
$ find -mtime +0
Linux �� date �R�}���h�őO���̓��t���擾����
UNIX/Linux �� date �R�}���h�́A�������w�肵�� ���t���擾�ł���̂ŁA�t�@�C�����Ȃǂɓ��t��t�������Ƃ��� �ƂĂ��֗��ł��B
���� date �R�}���h�́A���t���w�肵�Ď擾���邱�Ƃ��ł��܂��B
"--date" �I�v�V�������g���� 1 ���O�Ȃ玟�̂悤�Ɏw�肵�܂��B
$ date +"%Y/%m/%d" --date "1 day ago"
3 ����Ȃ玟�̂悤�Ɏw�肵�܂��B
$ date +"%Y/%m/%d" --date "3 days"
"day" �ł� "days" �ł��擾�ł��܂��B
�o�b�`�����ŁA�O���̓��t���K�v�ȂƂ��Ȃ� ���ɗ����܂��B
�]�k�ł����A���t�w��̃I�v�V������ "-v" ���Ǝv���Ă����̂ł��� �ǂ���炻��� BSD �n�� UNIX �� date �R�}���h�̂悤�� Redhat �� Debian �� "--date" �ɂȂ��Ă��܂����B
yum �� �v���L�V�𗘗p����
yum �R�}���h�� �v���L�V�𗘗p����ꍇ�̃����ł��B
�T�[�o�S�̂Őݒ肷��ɂ� yum �̐ݒ�t�@�C���ɒNjL���܂��B
# vi /etc/yum.conf
proxy=http://192.168.1.200:3128/ proxy_username=USER proxy_password=PASS
�ꎞ�I�ɐݒ肷��ɂ� ���̂悤�Ɋ��ϐ���ݒ肵�܂��B
$ export http_proxy="http://USER:PASS@192.168.1.200:3128/"
sshd �� blacklisted �G���[
�V���� Debian �̃T�[�o����ꂽ�Ƃ��� �ʂ̃T�[�o��������̌��� �ڍs���悤�Ƃ��ăn�}��܂����B
authorized_keys �R�s�[���� �����̔閧���� ���O�C�����悤�Ƃ����̂ł��� ���̂悤�ȃG���[���o�ă��O�C���ł��܂���ł����B
auth.log:488:Feb 21 06:31:01 XXXX sshd[1296]: error: Host key ... blacklisted (see ssh-vulnkey(1))
���ׂĂ݂�� �ǂ����ꕔ�� Debian�AUbuntu �Ȃǂ� �������ꂽOpenSSL�x�[�X�̌��́A �v���Z�X ID �����ɗ����Ƃ��Ă��� �����̎g�p���@�ɖ�肪���������� ���̍�蒼�����K�v�ɂȂ�悤�ł��B
����ɊY������悤�� �G���[���o�Ă����悤�ł��B
������蒼���Ȃ���Ȃ�Ȃ��̂ł��� �Ƃ肠���� �ꎞ�I�ɐڑ��ł���悤�ɂ���ɂ� sshd_config �� ���̐ݒ��lj����܂��B
PermitBlacklistedKeys yes
�Ƃ肠������ ����Ōq����悤�ɂȂ�܂����B
��肠�錮�i�Ǝ�Ȍ��j�ׂ邽�߂� �R�}���h���p�ӂ���Ă��܂����B ���̃R�}���h�ŁA�S�Ắi�W���̏ꏊ�Ɋi�[����Ă���j���� �`�F�b�N���܂��B
# ssh-vulnkey -a Not blacklisted: 2048 xx:xx:xx:xx:xx:xx:xx:xx:xx:xx root@xxx Not blacklisted: 1024 xx:xx:xx:xx:xx:xx:xx:xx:xx:xx root@xxx COMPROMISED: 2048 xx:xx:xx:xx:xx:xx:xx:xx:xx:xx user@xxx
COMPROMISED �Əo�Ă��錮�� NG (�Ǝ�) �ł��B
squid �̃��O�̎����ɂ�
squid �� ���O�� �擪�������Ȃ̂ł��� ���̂悤�� unix �̎����ŕ\������Ă��܂��B
1248217969.955 11 192.168.1.10 TCP_MISS/200 1939 GET http://www
���̂܂܂ł͎g���ɂ����̂� perl �ŊȒP�ɕϊ����܂��B
#!/usr/bin/perl
while (<>) {
chomp;
my ($t,$d) = /^([\d\.]+)(.*)$/;
my @lt = localtime($t); $lt[5]+=1900; $lt[4]++;
printf("%04d\/%02d\/%02d %02d:%02d:%02d%s\n",@lt[5,4,3,2,1,0],$d);
}
����� �p�C�v���邩 ���O�t�@�C���������ɂ��Ď��s���܂��B
$ cat access.log | ./convert.pl
1248217969.955 11 192.168.1.10 TCP_MISS/200 1939 GET http://www 1248217970.134 339 192.168.1.21 TCP_MISS/200 21245 GET http://cl 1248218095.936 0 192.168.1.33 TCP_MISS/200 32 GET http://www.g
���̂悤�Ȍ��ʂɂȂ�܂��B
2009/07/22 08:12:49 11 192.168.1.10 TCP_MISS/200 1939 GET http: 2009/07/22 08:12:50 339 192.168.1.21 TCP_MISS/200 21245 GET http 2009/07/22 08:14:55 5 192.168.1.33 TCP_MISS/200 32 GET http://
�I�[�v���\�[�X�J���t�@�����X 2009 Kansai 2 ����
�������s���Ă��܂����AOSC 2009 Kansai �I
�����A��u�����͎̂��̃Z�~�i�ł��B
- Firefox �o�����[�N�V���b�v�i��b��1�j
- Firefox �o�����[�N�V���b�v�i��b��2�j
- LinkStation/�������n�b�N���悤
- ����Android�P�[�^�C������Ă݂悤
- Samba���p�e�N�j�b�N���ŐV����
Firefox �̃��[�N�V���b�v�́A���@�����������̂ł����A �m�[�g PC �������Ă����̂��ʓ|�������̂� ��b�҂����u���܂����B �����������ł����A�Ƃ肠���������p�̊ȒP�ȏ����Ȃ��ꂻ���ł��B
�����́A�L���� �R������ �ł����B ��H�}�l�^��A�W�����p�[���́A�悭�킩��܂���ł������A�y�������ɃC�L�C�L�Ƙb������Ă����̂ŁA �����Ă��Ėʔ��������ł��B�������ł����B
2 ���ԃE���E�����Ă��܂������A2 ���������炢�� ���`�x�[�V���������߂�ꂽ�Ǝv���܂��B
�I�[�v���\�[�X�J���t�@�����X 2009 Kansai 1 ����
���t���b�V�������˂� OSC ( �I�[�v���\�[�X�J���t�@�����X ) 2009 Kansai �� 1 ���ڂɍs���Ă��܂����I
�험�i�ł��B

OSC �ł́A�F�X�ȃZ�~�i���J�Â��Ă���̂� ���Ԃ��ƂɁA�������̂�I�����܂��B ����͎��̃Z�~�i���Ă��܂����B
- Linux�Z�p�ҔF�莑�i�iLPIC�j���x��2�@�Z�p����Z�~�i�[
- ���E���Ŏg���Ă���wDrupal�x�B�ǂ�ȃT�C�g�ł����Ă��܂��ό����݂Ȑ��������`�����܂�
- �y���ʍu�`�z�I�[�v���\�[�X�A���̈Ӌ`�Ɖ\��
LPIC �� ���x�� 2 �͎擾�ς݂ł����A ���� �т��˂��� �̋{������̃Z�~�i���Ă���̂� �������u���܂����B �i�т��˂��Ƃ͍��� OSC �̉^�c�����Ă��܂����B�����l�łł��j
���͊֓��ɔ�ׂ��Ȃ����A�Z�~�i�Ȃǂ����Ȃ��̂ŁA���������`�����X�͓����܂���B �D���Ȃ��Ƃ�����Ă�l���D���Ȑl���m�ŏW�܂�̂ŁA���邾���Ń��`�x�[�V�������オ���Ă��܂��B ��Ђ̐�y�����Ă����̂ŁA�I�������A�M����荇���Ă��܂��܂����B
���M��p�� sendmail �̐ݒ�
�O���Ƀ��[���T�[�o�������� sendmail �� ���M�̃R�}���h�Ƃ��Ă̂ݎg�p����ꍇ�̐ݒ�ł��B LAN ���̃V�X�e�����쐬���Ă��� �ʂɃ��[���T�[�o������ꍇ���悭����܂��B
���T�[�o�ł́A���[���T�[�o�����K�v���Ȃ����� �f�[�����Ƃ��� sendmail �����K�v�͂���܂���B
sendmail.cf �� �T�[�o�p�̐ݒ�t�@�C���Ȃ̂� mail �R�}���h���g�p���� submit.cf ��ݒ肵�܂��B
�܂� submit.mc ��ҏW���܂��B
# vi /etc/mail/submit.mc
���̐ݒ��ύX���܂��B
FEATURE(`msp', `[127.0.0.1]')dnl
�O���̃��[���T�[�o�� mail.example.com �̂Ƃ� ���̂悤�ɋL�q���܂��B "dnl" �́A�R�����g�A�E�g�ł��B
dnl FEATURE(`msp', `[127.0.0.1]')dnl FEATURE(`msp', `mail.example.com')dnl
���ł� ���̂悤�ɋL�q���� �z�X�g����ݒ�ł��܂��B
���M���[���� xxxx@example.com �̗l�ɂȂ�܂��B
define(`confDOMAIN_NAME', `example.com')dnl
�ҏW���I�������A���̃R�}���h�� submit.mc ���� submit.cf ���쐬���܂��B
# m4 /etc/mail/submit.mc > /etc/mail/submit.cf
Redhat �ł� sendmail-cf �p�b�P�[�W�������Ă��Ȃ��� m4 �R�}���h���Ȃ��̂� �C���X�g�[������K�v������܂��B
# yum install sendmail-cf
sendmail �� ���M���s�������[���̃L���[���đ�����
sendmail ���g���Ă��đ��M�Ɏ��s�������[���� �L���[�Ƃ��ė��܂��Ă����܂��B
sendmail.cf �ɖ�肪�����āA sendmail �T�[�o����̑��M�Ɏ��s���Ă���ꍇ ���̃f�B���N�g���Ƀt�@�C���Ƃ��ė��܂��Ă����܂��B
/var/spool/mqueue
�s�v�ł���t�@�C�����폜���Ă��ǂ��̂ł��� �đ�����ꍇ�́A���̃R�}���h���g�p���܂��B
# sendmail -q
submit.cf �ɖ�肪�����āA SMTP �T�[�o�ւ̑��M�Ɏ��s���Ă���ꍇ ���̃f�B���N�g���Ƀt�@�C���Ƃ��ė��܂��Ă����܂��B
/var/spool/clientmqueue
������đ�����ɂ� ���̃R�}���h���g�p���܂��B
# sendmail -q -Ac
wget �� �v���L�V�𗘗p����
wget �́A�R�}���h���C���� HTTP �� FTP �� �f�[�^���擾����R�}���h�ł��B wget �� �v���L�V�𗘗p����ꍇ�̐ݒ���@�� �����Ƃ��ď����Ă����܂��B
�v���L�V�T�[�o��IP�A�h���X�� 192.168.1.200�A �|�[�g�ԍ��� 3128 �̏ꍇ�A ���̂悤�Ɋ��ϐ� http_porxy ��ݒ肵�܂��B
$ export http_porxy=192.168.1.200:3128 $ wget http://www.yahoo.co.jp/
�v���L�V�Ƀ��[�U�F���K�v�ȏꍇ�A ���̂悤�� wget �̃I�v�V�������w�肵�܂��B
$ export http_porxy=192.168.1.200:3128
$ wget --proxy-user=username \
--proxy-password=passwrod \
http://www.yahoo.co.jp/
"\" (�~�}�[�N/�o�b�N�X���b�V��)�́A�R�}���h�̓r���ʼn��s���邽�߂̋L���ł��B
�R�}���h�̏����t���A�����s
�R�}���h�� ";" (�Z�~�R����) �ŕ��ׂď������Ƃ��ł��܂��B
$ echo 1; echo 2; echo 3 1 2 3
����� "|" (�p�C�v) �̂悤�ɏo�͂����̃R�}���h�ɓn������� �����A�P���ɘA���Ŏ��s���܂��B
";" (�Z�~�R����) �ł͂Ȃ� "&&" (AND���Z�q) ���g���� �O�̃R�}���h������I�������ꍇ�̂� ���̃R�}���h�����s���܂��B
$ echo 1 && false && echo 2 1
"false" �́A�K���ُ�I������R�}���h�ł��B "false" �ňُ�I���������߁A "echo 2" �����s����܂���ł����B
�t�ɑO�̃R�}���h���ُ�I�������ꍇ�̂� ���̃R�}���h�����s���� "||" (OR���Z�q) ������܂��B
$ false || echo 1 1
�R�}���h���ُ�I�������Ƃ��� ���ʂȏ�����������Ȃǂł��܂��B
�����܂őO�̃R�}���h�̎��s���ʂ��ǂ��� �Ƃ������ƂȂ̂ŁA���̂悤�ɏ������ꍇ �擪���珇�ɔ��肳��܂��B
$ echo 1 && false || echo 2 && false || echo 3 1 2 3
�V�F���ňʒu�p�����[�^�̃Z�b�g
�V�F���ŕϐ��ɒl���Z�b�g����ꍇ�� ���̂悤�ɂ��܂��B
$ var1=KAME $ echo $var1 KAME
�R�}���h�̎��s���ʂ��Z�b�g����ꍇ�� ���̂悤�ɂ��܂��B
$ var2=`echo KAME to USAGI` $ echo $var2 KAME to USAGI
���̗�ł́A$var2 �� "KAME to USAGI" �ƃZ�b�g����Ă��܂��܂��� �ʁX�̕ϐ��ɃZ�b�g�������ꍇ������܂��B
����ȂƂ��ɂ́Aset �R�}���h���g�p���܂��B
set �R�}���h�́A���̗�̂悤�� ������ $n �̈ʒu�p�����[�^�ɃZ�b�g���邱�Ƃ��ł��܂��B
$ set KANI SARU KAKI $ echo $1 KANI $ echo $2 SARU $ echo $3 KAKI
�R�}���h�̌��ʂ��Z�b�g����ɂ� ���̂悤�ɏ����܂��B
$ set `echo KAME to USAGI` $ echo $1 KAME $ echo $2 to $ echo $3 USAGI
�R�}���h�ƒ萔�������ď������Ƃ��ł��܂��B
$ set KURI `echo KANI KAKI` ONIGIRI $ echo $1,$2,$3,$4 KURI,KANI,KAKI,ONIGIRI
�l�̒��� set �̃I�v�V�����Ƃ��ė������ꂻ���Ȃ��̂� ����ꍇ�́A"--" �I�v�V�������w�肵�܂��B "--" �I�v�V�����ȍ~�͑S�Ĉ����Ɣ��肳��܂��B
$ set -- -x $ echo $1 -x
�ʒu�p�����[�^���N���A����ɂ́A "--" �I�v�V�����������w�肵�܂��B
$ set --
nkf �ŕ����R�[�h�ϊ�
Linux �ł́Ankf �Ƃ����R�}���h���g���āA�����R�[�h�̕ϊ����ł��܂��B
���̗�� Shiht_JIS �� input_file �� UTF-8 �ɕϊ����� output_file �� �o�͂��Ă��܂��B
$ nkf -S -w -x -O input_file output_file
"-S" �́A�Ǎ��t�@�C���̕����R�[�h�� Shift_JIS �Ƃ����w��ł��B �t���Ȃ��Ă��������肵�܂����A�Ǎ��t�@�C���̕����R�[�h�� �킩���Ă���Ƃ��́A�t���Ă�����������F�����Ȃ��ėǂ��ł��B
"-w" �́A�o�͂̕����R�[�h�� UTF-8 �Ƃ����w��ł��B
"-O" �́A�Ō�� �o�̓t�@�C�����w�肷��I�v�V�����ł��B ���̃I�v�V�������w�肵�Ȃ��ƕW���o�͂ɏo�͂��܂��B �f�[�^�������Ȃ�ƁA�W���o�͂��t�@�C���Ƀ��_�C���N�g������ ���̃I�v�V�����ŏo�̓t�@�C�����w�肷��������x���o�܂��B
���̕\�́A�����R�[�h�̃I�v�V�����ł��B
| �����R�[�h | �Ǎ� | �o�� |
|---|---|---|
| Shift_JIS | -S | -s |
| JIS | -J | -j |
| EUC-JP | -E | -e |
| UTF-8/UTF-8N | -W | -w |
SELinux �̏�ԕύX
SELinux �́A�֗��ł����A�A�N�Z�X�G���[�Ȃǂ̖�肪���������Ƃ��� �����������̂� SELinux ���e�����Ă���̂����f����Ƃ�������܂��B
����ȂƂ��́ASELinux ���ꎞ�I�ɖ����ɂ��āA �������m�F����̂��L���ł��B
�܂��A���݂̏�Ԃ��m�F����ɂ́A���̃R�}���h���g���܂��B
# getenforce
Enfocing �� Permissive �Ƃ�������Ԗ����\������܂��B ��Ԗ��̓��e�͎��̕\�̂悤�ɂȂ�܂��B
| ��� | �@�\ | ���� |
|---|---|---|
| Enfocing | �L�� | �L�� |
| Permissive | �x���̂� | ���� |
| Disabled | ���� | ���� |
Enfocing �́ASELinux�� �S�ėL���ȏ�Ԃł��B
Permissive �́ASELinux�� �x����\�����邾���ŁA����͂��Ȃ���Ԃł��B ������ SELinux �����f�ł��Ȃ��Ƃ��ɁA���̏�ԂɕύX���Ċm�F���܂��B
Disabled �́ASELinux�� �S�Ė����ȏ�Ԃł��B
���̃R�}���h�� SELinux �̏�Ԃ��A �ꎞ�I�� Permissive �ɂ��邱�Ƃ��ł��܂��B �ċN������ƌ��ɖ߂�܂��B
# setenforce 0
���̃R�}���h�� SELinux �̏�Ԃ��A �ꎞ�I�� Enfocing �ɂ��邱�Ƃ��ł��܂��B ��������ċN������ƌ��ɖ߂�܂��B ���̃R�}���h�ŁA��Ԃ� Disabled �ɂ��邱�Ƃ͂ł��܂���B
# setenforce 1
�i���I�ɕύX����ɂ́A���̃t�@�C���� SELINUX �̒l��ύX���čċN�����܂��B
# vi /etc/sysconfig/selinux
SELINUX=disabled
�t�@�C���� 0 �o�C�g�ɂ���
�NjL�^�Ń��O�t�@�C���Ȃǂ��쐬���Ă���� �t�@�C���� 0 �o�C�g�ŃN���A�������Ƃ�������܂��B
���悤�ȃR�}���h�� �t�@�C���� 0 �o�C�g�ɂ��܂��B �i�t�@�C�������݂��Ȃ���A 0 �o�C�g�̃t�@�C�����쐬���܂��j
$ cat /dev/null > 0.txt
DOS �̏ꍇ�́A���̂悤�ɃR�}���h��ł��܂��B null �ł͂Ȃ��Anul �Ȃ̂Œ��ӂ��Ă��������B
C:\> type nul > 0.txt
tar �R�}���h�� �s�v�ȃt�@�C���͏��O����
tar �R�}���h���g���Čł߂�Ƃ��� �p�X�̎w��̕��@�ɂ���Ă� �s�v�ȃt�@�C����f�B���N�g����������ꍇ������܂��B
�K�v�ȃt�@�C���݂̂��w�肷��̂�����ꍇ�A �s�v�ȃt�@�C�������O������@������܂��B
�܂��͉����w�肵�Ȃ��ꍇ�ł��B
$ tar cvf test.tgz test test/ test/a/ test/a/aaa1.txt test/a/aaa2.txt test/c/ test/c/ccc1.txt test/b/ test/b/bbb1.txt
test/a �̔z�����s�v�ȏꍇ ���̂悤�� "--exclude" �I�v�V�������g���� �s�v�ȃp�X�̃p�^�[�����w�肵�܂��B
$ tar cvf test.tgz --exclude 'test/a*' test test/ test/b/ test/b/bbb1.txt test/c/ test/c/ccc1.txt
test/a �����O���邱�Ƃ��ł��܂����B
�������Atest/a.txt �̂悤�ȃt�@�C�������O���Ă��܂��̂� �p�^�[�����w�肷��ꍇ�͒��ӂ��Ă��������B
Linux �̃T�[�o�ԃt�@�C���]��
������� Linux �T�[�o���g���č�Ƃ��Ă���� �T�[�o����T�[�o�Ƀt�@�C����]���������Ƃ�������܂��B
ssh �����Ă���A�ȒP�Ƀt�@�C����]�����邱�Ƃ��ł��܂��B
���̗�́Ascp �R�}���h���g���āA ���[�J���i���O�C�����Ă���T�[�o�j�� test.txt �� 192.168.1.101 �� /tmp/test.txt �ɓ]�����Ă��܂��B
$ scp test.txt username@192.168.1.101:/tmp/test.txt
���̗�̂悤�� ssh �R�}���h���g���� �f�B���N�g�����ł߂遨���遨�W�J���� �� �p�C�v���g���� �s�����Ƃ��ł��܂��B
$ tar cf - test | ssh username@192.168.1.101 'cd /tmp;tar xf -'
�p�C�v���g���ē]������� �ꎞ�t�@�C�����s�v�Ȃ����łȂ� �R�}���h���g�����Ȃ��Ă�I �Ƃ������������܂��B
Red Hat �� vsftpd
Red Hat Enterprise Linux 5 �̓������Ă����Ƃ��̘b�ł����A vsftpd �� ftp �T�[�o������ �ڑ����悤�Ƃ����Ƃ��� �G���[�œ{���Ă��܂��܂����B
ftp �p�̃A�J�E���g���쐬���� ���̃z�[���f�B���N�g���ȉ����� �A�N�Z�X�ł��Ȃ��悤�ɂ����̂ł����A �z�[���f�B���N�g���̃A�N�Z�X�ɑ��� SELinux ���{���Ă���悤�ł����B
# setsebool -P ftp_home_dir 1
����ȏꍇ�A��L�̎����� ftp_home_dir �̒l�� active �ɂ��܂��B
���Ȃ݂� "-P"�I�v�V������t���Ȃ��ƁA�ċN����Ɍ��ɖ߂��Ă��܂��܂��B
Ecolinux��USB�u�[�g���Ă݂�
Ubuntu8.10���N������UBS�������� ��ЂɎ����čs������ł����A1�䂾���N���Ȃ�PC������܂����B ��ʂ̉𑜓x�ӂ�̖�肩�ȁA�Ƃ��v�����A ���������Ȃ̂ňႤLinux�����Ď����Ă݂邱�Ƃɂ��܂����B
- Ecolinux
- http://ja.ecolinuxos.com/
UBS��������Ubuntu8.10�������Ȃ�����PC�ł��A�Ƃ肠��������Linux�͓����܂����B
�u�K�v�ȃA�v���P�[�V�����͌ォ��C���X�g�[������v�Ƃ������j�̂��߁A�y�ʂ������ł��B �܂��A�u�ł��邾�����l�ȃn�[�h�E�F�A�ɑΉ�����v�Ƃ������Ƃ� �uUbuntu���x�[�X�Ƃ������S�ȃp�b�P�[�W�V�X�e���ƈ��肵�����|�W�g���v�Ƃ������Ƃ� USB�������Ŏ����^�Ԃɂ͒��x�ǂ������ł��B
�_�E�����[�h���Ă���ISO�t�@�C����VirtualBox�ŋN�������āA VirtualBox���USB�������ɒ��ȒP�ɃC���X�g�[�����邱�Ƃ��ł��܂����B
���̂����C���X�g�[���菇����������ł��B
�C���X�g�[������USB��������VirtualBox��ŋN�������邱�Ƃ��ł���� �X�N���[���V���b�g�Ȃ��ڂ��邱�Ƃ��ł����̂ł����E�E�E�B
����͂���Œ��ׂȂ��ƁB
