2010年 05月
- Linux の paste コマンドで カンマ区切りのデータを作る
- Linux の sort コマンドでソートする列を指定する
- awk コマンドでヘッダーやフッターを出力する
- 積ん読 2010/05/29
- vi が怖いときの view コマンド
- 積ん読 2010/05/26
- 積ん読 2010/05/25
- CSS の visited を利用してブラウザの訪問履歴をチェックする
- Linux の find コマンドを使ってみる
- 積ん読 2010/05/22
- 積ん読 2010/05/20
- 積ん読 2010/05/19
- 積ん読 2010/05/18
- 積ん読 2010/05/16
- Bash で計算してみる
- 積ん読 2010/05/15
- Linux の echo で改行させない
- 積ん読 2010/05/14
- FTP コマンドで、接続先サーバのファイルの属性を変更する
- 積ん読 2010/05/11
- 積ん読 2010/05/10
- 積ん読 2010/05/07
- PostgreSQL の PREPARE
- cal コマンドで月曜日を先頭にする
- Linux で cd する前のディレクトリに戻る
- 積ん読 2010/05/04
- chown コマンドでグループも変更する
- Excel のフィル
- なにわオラクル倶楽部のノベルティ
- 積ん読 2010/05/01
Linux の paste コマンドで カンマ区切りのデータを作る
paste というコマンドがあります。
2 つのファイルを行ごとに連結するするコマンドなのですが 何か“ちょっと違う”使い道がないか考えていました。 今回は、このコマンドでカンマ区切りのデータを作ってみたいと思います。
まずは paste コマンドのおさらい。
次の 2 つのファイル user.txt と color.txt を処理します。
sato suzuki watanabe yamada
red black white
この 2 つのファイルをを列ごとに連結します。
$ paste user.txt color.txt
sato red
suzuki black
watanabe white
yamada
デフォルトでは、列は TAB で連結されます。 color.txt が 1 行少ないので 最後の行は "yamada" のみ出力されます。
区切りを変えることもできます。
$ paste -d "=" user.txt color.txt sato=red suzuki=black watanabe=white yamada=
"-s" オプションを付けると、ファイルごとに 1 行になります。
$ paste -s user.txt color.txt
sato suzuki watanabe yamada
red black white
標準入力を受けることもできます。
$ cat color.txt | paste -s
red black white
これを利用することで、 標準入力を受けて カンマ区切りで出力することができます。
$ ls | paste -s -d ","
a.txt,b.txt,c.txt,d.txt
Linux の sort コマンドでソートする列を指定する
Linux の sort コマンドはソートする列を指定することができます。
次のテキストファイル( score.txt )を処理してみます。
yamada 90 tanaka 100 sato 64 suzuki 93
オプションなしのソートだと次のようになります。
$ sort score.txt
sato 64
suzuki 93
tanaka 100
yamada 90
2 列目でソートします。
$ sort -k 2,2 score.txt tanaka 100 sato 64 yamada 90 suzuki 93
"2,2" という指定は 「 2 列目から 2 列目まで」という意味で 2 列目のみを使ってソートするときの指定です。 "2" だけを指定すると 「 2 列目から最後まで」という意味になります。
数字が“数値”として認識されていないので ソート順が変です。 "-n" オプションで、数値を“数値”と認識させます。
$ sort -k 2,2 -n score.txt sato 64 yamada 90 suzuki 93 tanaka 100
ついでに 値の大きい順(降順)にします。
$ sort -k 2,2 -n -r score.txt tanaka 100 suzuki 93 yamada 90 sato 64
ソートできました。
CSV ファイルのように列の区切り文字が空白でないときは 次のように "-t" オプションで区切り文字を指定できます。
$ sort -k 2,2 -n -r -t "," score.txt
awk コマンドでヘッダーやフッターを出力する
テキストを扱う awk というコマンドがあります。
このコマンド、かなり便利なのですが、 できることが多過ぎるので覚えるのは結構大変だったりします。 「基本的な使い方はわかるけど・・・」という人も多いのではないでしょうか。 自分へのメモの意味も含めて機能を紹介したいと思います。
次のテキストを処理します。( test.txt )
1 2 3 4 5 6 7 8 9 10 11 12
まず基本的な使い方です。
$ cat test.txt | awk '{print $2}'
2
5
8
11
awk の書式で {} の前にはパターンを書くことができます。
{} の前に何も書かないのは、全ての行にマッチ(全ての行に対して処理をする)という指定になります。 (これについてはまた別の機会に詳しく書きたいと思います)
今回は、BEGIN と END という特殊な指定を使いますが、BEGIN は「最初の行の前」にマッチする指定で END は「最後の行の後」にマッチする指定です。これを使ってヘッダーやフッターを出力します。
次のような指定ができます。
$ cat test.txt | \ > awk 'BEGIN {print "-- header --"} END {print "-- footer --"}' -- header -- -- footer --
BEGIN と END の指定しかないので、ヘッダーとフッターのみが出力されました。
プログラムの部分が長くなるので、別ファイル( prog.txt )に指定して 引数で読み込むようにします。
次のような指定をしてみます。
BEGIN {
print " f1 | f2 | f3 ";
print "----+----+----";
}
{
printf("%4d|%4d|%4d\n", $1, $2, $3);
}
BEGIN (前半)と 全ての行にマッチする指定(後半)をしました。
次のような結果になります。
$ cat test.txt | awk -f prog.txt f1 | f2 | f3 ----+----+---- 1| 2| 3 4| 5| 6 7| 8| 9 10| 11| 12
ヘッダーと本体が出力されました。
次はフッターに合計行を出したいと思います。
awk は計算もできます。
BEGIN {
print " f1 | f2 | f3 ";
print "----+----+----";
f1=0;
f2=0;
f3=0;
}
{
printf("%4d|%4d|%4d\n", $1, $2, $3);
f1=f1+$1;
f2=f2+$2;
f3=f3+$3;
}
END {
print "----+----+----";
printf("%4d|%4d|%4d\n", f1, f2, f3);
}
初期化処理は BEGIN に書くことができます。
次のような結果になります。
$ cat test.txt | awk -f prog.txt
f1 | f2 | f3
----+----+----
1| 2| 3
4| 5| 6
7| 8| 9
10| 11| 12
----+----+----
22| 26| 30
合計行を出力することができました。
ちょっとしたときにサッと書けるとカッコ良いですね。
積ん読 2010/05/29
- 簡単!Visual Studio 2010入門 第2回 Visual Studio 2010の基礎を知る - @IT (2010/05/26)
- デザイナのためのWeb学習帳(6) 無料ソフトで超入門! 動画キャプチャ→編集→配信 - @IT (2010/05/28)
- グーグルの「パックマン」ロゴができるまで--ウェブ技術でオリジナルを忠実に再現 - CNET Japan (2010/05/27)
- イトイ流Twitter論――糸井重里さんが「ほぼ日」に記した“ツイッターの初心。” - はてなブックマークニュース (2010/05/28)
- ツイッターの初心。 - ほぼ日刊イトイ新聞-ダーリンコラム (2010/05/24)
- Ubuntu 10.04--注目すべき10の改善点 - ZDNet Japan (2010/05/28)
- IE6でも透過PNG を使う - バシャログ。 (2010/05/28)
vi が怖いときの view コマンド
「ファイルを vi で開くと間違って上書き保存してしまうのが怖い」と 言われたことがあります。 vi を終了する際に ":wq" と打ってしまうそうなのですが これでは確かに更新日時が変わってしまいます。
そこで view というコマンドがあります。
$ view a.txt
このコマンドはファイルを vi の読み取りモードの "-R" オプションを付けた状態で開いてくれます。
この状態であれば ":w" で保存しようとしても「読み取り専用です」とエラーになります。 ただし ":w!" のような強制保存はできてしまうので注意して下さい。
vi の操作で保存だけしたくない、というときに安心なコマンドです。
積ん読 2010/05/26
- Windows 7ネットワーク大解剖 Windowsネットワークへ参加する - ITpro (2010/05/25)
- 【今週の小技】 パスワード生成サイトへのショートカットを作った - IDEA*IDEA 〜 百式管理人のライフハックブログ (2010/05/25)
- 親は心配していない? - asahi.com (2010/05/24)
- Googleロゴに使われたブラウザ版「パックマン」を延長公開 - 教えて君.net (2010/05/26)
- Amazonで毎週更新のウェブ文芸誌「MATOGROSSO」創刊 - 教えて君.net (2010/05/24)
- 「Google Chrome」v5が安定版に、同期機能が強化されたほかHTML5への対応も進む - 窓の杜 (2010/05/26)
積ん読 2010/05/25
- Google、SSL暗号化対応の検索ページを発表 - TechCrunch (2010/05/23)
- 爆笑問題がオンエアで見た「情熱大陸」田中編 - はてなでテレビの土踏まず (2010/05/22)
- なぜ日本人は自由競争も所得再分配も嫌うのか? - Baatarismの溜息通信 (2010/05/22)
- 玉ねぎを水にザブンとつけて「涙くんさよなら」 - ライフハッカー (2010/05/25)
CSS の visited を利用してブラウザの訪問履歴をチェックする
CSS の visited を利用してブラウザの訪問履歴を取得されうるユーザは 76 % 以上に上る - Slashdot.jp
というような記事があったのですが、理屈はわかるものの 具体的な実装方法が思いつかないので 調べてみました。
getComputedStyle や currentStyle 辺りを使って visited の色に変更されているかを確認するようですね。
下のサイトなどを
参考に IE6 にも対応する形で作ってみました。
気になる人は HTML ソースを見てください。
(動作確認 IE6 Firefox3.6 )
【参考サイト】
getComputedStyle について調べてたら深みにハマったのでメモ - IT戦記
Yahooo! JAPAN のリンクをいくつか貼ってみました。 「訪問済みチェック」をクリックしてみてください。 URL の方をクリックすると、そのページにジャンプします。
訪問済みチェック → http://www.yahoo.co.jp/
訪問済みチェック → http://gourmet.yahoo.co.jp/
訪問済みチェック → http://realestate.yahoo.co.jp/
訪問済みチェック → http://variety.yahoo.co.jp/
ちなみに次期バージョンの Firefox では対策されるそうです。
Linux の find コマンドを使ってみる
find コマンドは 色々な条件でファイルを探してリストを出力してくれる 便利なコマンドです。 しかし、全てのオプションは とても覚えきれません。 そこで今回は“最低限これだけは”という内容に絞って 紹介したいと思います。
パスの指定
まずはパスの指定です。
find コマンドは指定したパス以下を検索します。
パスの指定をしないと カレントディレクトリを指定したことになります。 また、パスの指定によって結果の表示も変わってしまいます。 (オプションで変更することはできますが、今回は割愛します)
例えば、パスを「相対パス」で指定した場合、次のように 結果の出力も相対パスになります。
$ find ./hogehoge
./hogehoge
./hogehoge/a.txt
./hogehoge/b.txt
「絶対パス」で指定すれば 結果も絶対パスになります。
$ find /home/hogehoge
/home/hogehoge
/home/hogehoge/a.txt
/home/hogehoge/b.txt
抽出条件の指定
次に抽出条件です。
多くの場合、「ファイル名」か「更新日」になると思います。
ファイル名は "-name" オプションで 条件を指定できます。
$ find . -name "*.txt" ./hogehoge/a.txt ./hogehoge/b.txt
この例では "*.txt" にマッチするファイルのみを抽出しました。 マッチングには "*" や "?" を使うことができます。
ただし、マッチングの対象になるのはパスの最後のエントリー名(上の例では "a.txt" や "b.txt")のみで、途中のパスは対象になりません。 ディレクトリ自体が最後のエントリーの場合は、そのディレクトリ名が マッチングの対象になります。
$ find . -name "hoge*" ./hogehoge
更新日は "-mtime" オプションで ファイルが更新されてからの時間が指定できます。
$ find . -mtime +3 ./hogehoge/a.txt
値の指定は、プラス "+" の場合 〜日以上前(上の例の場合 3 日以上前)で マイナス "-" の場合 〜日以内となります。
$ find . -mtime -3 ./hogehoge ./hogehoge/b.txt
処理の実行
取得したパスに対して処理を行ないたいときがあります。
例えば「 3 日以上前の zip ファイルを削除する」といった場合ですが 対象の取得は 次のようなオプションで指定できます。
$ find /var/backup -mtime +3 -name "*.zip" /var/backup/a.zip /var/backup/b.zip
これに対して処理をするわけですから イメージとしてはパイプを使って 次のようになります。
$ find /var/backup -mtime +3 -name "*.zip" | while read path > do > rm $path > done
同じ動作を "-exec" オプションで指定することができます。
$ find /var/backup -mtime +3 -name "*.zip" -exec rm {} \;
"-exec" 以降、"\;" までがコマンドになります。
"{}" の部分に取得されたパスが入ります。
その他のオプション
その他のオプションでオススメなのは "-ls" です。 このオプションを付けると結果の出力を ls コマンドと同じような 形にしてくれます。
$ find . -ls 10767946 12 drwxr-xr-x 1 u g 4096 11月 20 2009 ./hogehoge 10768066 4 -rw-r--r-- 1 u g 512 11月 15 2009 ./hogehoge/a.txt 10768041 4 -rw-r--r-- 1 u g 512 11月 20 2009 ./hogehoge/b.txt
他にも色々なオプションがありますが 「どうしても使わないとならない」という場面以外では 他のコマンドと組み合わせて使う方が シンプルで見やすくなると思います。
積ん読 2010/05/22
- Googleロゴが“遊べる”パックマンに--256面までプレイ可能、隠しコマンドも - CNET Japan (2010/05/22)
- 宮崎県・畜産農家への寄付受付先まとめ - ライフハッカー (2010/05/21)
- GIGAZINEのTwitter公式アカウントを公開開始、ここに至るまでの経緯も公開 - GIGAZINE (2010/05/22)
積ん読 2010/05/20
- マルチモニター環境をより使いやすくする「Multi Monitor Extension」 ウィンドウ一発移動やマウスカーソル移動制限、壁紙指定などの機能集 - 窓の杜 (2010/05/19)
- 川口洋のセキュリティ・プライベート・アイズ(25) 実録・4大データベースへの直接攻撃 - @IT (2010/05/18)
- Apache でファイル共有 -WebDAV- - バシャログ。 (2010/05/20)
- IE6のバグ対策法をまとめた『Ultimate IE6 Cheatsheet』が便利ですね… - IDEA*IDEA 〜 百式管理人のライフハックブログ (2010/05/20)
積ん読 2010/05/19
- 君のつくる会社の仕事は、100年後の誰かが引き継ぎたい仕事だろうか - Keep Crazy;shi3zの日記 (2010/05/19)
- PowerShell的システム管理入門 ―― PowerShell 2.0で始める、これからのWindowsシステム管理術 ―― 第3回 ファイル/レジストリの操作 - @IT (2010/05/19)
- JavaScript のブロックスコープと名前空間 - Mozilla Developer Street (modest) (2010/05/19)
積ん読 2010/05/18
- 連載:Windowsフォーム開発入門【Visual Studio 2010対応】 Windowsフォーム初めの一歩 - @IT (2010/05/18)
- [CSS]画像を使用しないで、紙テープを折り返したようにするスタイルシート - コリス (2010/05/18)
- ここまでできる!CSS3を使ったチュートリアルまとめ - DesignWalker (2010/05/18)
- 街並みや工事現場がジオラマみたい!“微速度撮影”の美しい動画 - はてなブックマークニュース (2010/05/18)
- 「IE6は9年前の腐った牛乳」――Microsoftがアップグレード呼び掛け - ITmedia (2010/05/17)
- Linux初心者がやってしまいがちな10+の過ち - ZDNet Japan (2010/05/17)
積ん読 2010/05/16
- Ubuntu 10.04のキーボードショートカット集 - ライフハッカー (2010/05/15)
- Linuxでシステムに対して意図的に高負荷をかけたい場 - RX-7乗りの適当な日々 (2010/05/14)
- 客を責めたら終わりだしょ - Chikirinの日記 (2010/05/12)
- PHP関数リファレンスへのショートカット - バシャログ。 (2010/05/12)
Bash で計算してみる
sh などでは変数を計算に使用できないため 次のように expr コマンドを使って計算します。
$ echo `expr 3 + 22` 25
$ A=15 $ B=`expr $A - 12` $ echo $B 3
Bash では $ + 二重カッコ "$(( ))" で計算ができます。
$ echo $((3 + 22)) 25
$ A=15 $ B=$(($A - 12)) $ echo $B 3
カッコ内の変数は $ を省略できます。
$ A=15 $ B=$((A - 12)) $ echo $B 3
計算するだけの場合、カッコの前の $ は不要です。
$ A=15 $ ((B = A * 2)) $ echo $B 30
積ん読 2010/05/15
- ターミナルからちゃちゃっと計算したいときに使える一行スクリプト - IDEA*IDEA 〜 百式管理人のライフハックブログ (2010/05/14)
- アリは砂糖でも巣を作る?砂糖のビンにアリを入れた実験動画に注目 - はてなブックマークニュース (2010/05/14)
- 裁断機 PK-513L で本を 100冊裁断してみた - 経験した 9つの失敗とその回避方法 - 彼女からは、おいちゃんと呼ばれています (2010/05/12)
Linux の echo で改行させない
使用した例は、ちょこちょこ出していたのですが メモ代わりに単独でネタにしておきます。
オプションを付けずに echo を使うと 行末に改行が付きます。
$ echo ABC; echo XYZ
ABC
XYZ
"-n" オプションを付けることで 改行なしにできます。
$ echo -n ABC; echo -n XYZ ABCXYZ
積ん読 2010/05/14
- 【文字配置編】行間が広がるのはナゼ?対策は? - PC Online (2010/05/10)
- tarファイルに魔法をかけてみよう! その1 - @IT (2010/05/10)
- Google、「ハッキング学習用Webアプリ」を公開 - Slashdot.jp (2010/05/10)
- 簡単!Visual Studio 2010入門 第1回 初めてのVisual Studio 2010 - @IT (2010/05/11)
- モジラ、「Firefox 4」リリース計画を明らかに--重要課題は速度 - CNET Japan (2010/05/12)
- 64bit環境対応の無償パーティション管理ソフト「Partition Wizard Home Edition」 - 窓の杜 (2010/05/12)
- 「名前を付けてリンク先を保存…」が面倒なときはダウンロードマネージャを開いておくと便利(Firefox) → ALTクリックでOKだった… - IDEA*IDEA 〜 百式管理人のライフハックブログ (2010/05/12)
- 「の」を3つ以上連続して使わない - 悪文と良文から学ぶロジカル・ライティング:selfup (2010/05/13)
- 入力したパスワードのカラーパターンを横に表示しておけばミスがなくなるんじゃね?『Chroma-Hash』 - IDEA*IDEA 〜 百式管理人のライフハックブログ (2010/05/13)
- 防弾ホスティングからクラウドへ - ITpro (2010/05/13)
FTP コマンドで、接続先サーバのファイルの属性を変更する
FTP コマンドで 接続先サーバのファイルの属性を変える場合 "quote site" コマンドを使用します。
まずは FTP サーバに接続します。
C:\> ftp 192.168.1.100
quote site コマンドの後ろは 通常の chmod コマンドのように 「属性」「ファイル名」を指定します。
ftp> quote site chmod 755 test.txt
使い方はこれで終わりですが 実はこれは FTP サーバ側で chmod の使用がサポートされている必要があります。
そもそも quote は 接続先に直接コマンドを送信するコマンドで site は、接続先でサポートしているコマンドを 実行するコマンドなのです。
chmod がサポートされているかどうかは "quote site" の後ろに "help" を指定して確認します。
ftp> quote site help 214- The following SITE commands are recognized (* =>'s unimplement UMASK IDLE CHMOD HELP 214 Direct comments to ftp-bugs@KURO-BOX1.
上の例の FTP サーバでは
chmod の他にも umask、idle が
サポートされています。
( * が付いている場合はサポートされていません)
積ん読 2010/05/11
- IFRSは本当に「誤解」されているのか - ITpro (2010/05/10)
- なぜソフトバンクはiPadにSIMロックをかけたのか - しゃおの雑記帳はてな支店 (2010/05/10)
- 第4のハイパーバイザー「KVM」開発者が語る、Xenとの大きな違い - Enterprise Watch (2009/10/26)
- 第2回 Xenをインストールして仮想環境を構築する - ITpro (2006/08/14)
積ん読 2010/05/10
- 【7%】 人生が教えてくれた45の教訓… - IDEA*IDEA 〜 百式管理人のライフハックブログ (2010/05/07)
- 2010年5月7日号 10.04 Japanese Remixのリリース・Ubuntu OpenWeek・10.04の注意点(3)・8.10のEOL・UWN#191 - gihyo.jp (2010/05/07)
- 特集:BusyBoxって何ぞや? 組み込みLinuxで際立つ「BusyBox」の魅力 - @IT MONOist (2008/02/04)
- さまざまなオープンソースライセンスをまとめてみた。 - 乱筆乱文お許し下さいorz (2010/05/09)
積ん読 2010/05/07
- 携帯電話のアンテナってどこにいったの? - ITpro (2010/04/05)
- 任天堂の赤い汚点「バーチャルボーイ」、早急な製品開発が失敗を誘引 - EE Times Japan (2009/06/15)
- すべての鍵穴はこうなってるべきじゃね?というシンプルなデザインが話題に - IDEA*IDEA 〜 百式管理人のライフハックブログ (2010/05/06)
- 画像は一切使ってない!?CSS3だけで描いた“ドラえもん”がすごい - はてなブックマークニュース (2010/05/06)
PostgreSQL の PREPARE
いきなり PREPARE と書いても 知らない人は「何それ?」となると思います。 PREPARE は PostgreSQL において SQL 文の予約をしてくれるメソッドです。 SQL 文の一時的な関数化と考えても良いかもしれません。
実際の使い方ですが、次のように宣言します。
db=# PREPARE sql_1 AS SELECT tablename from pg_tables; PREPARE
これで sql_1 という名前で登録できました。
予約した SQL 文を実行するには EXECUTE を使用します。
db=# EXECUTE sql_1; tablename ------------------------- sql_features sql_implementation_info sql_languages sql_packages sql_sizing sql_sizing_profiles
PREPARE には SELECT,INSERT,UPDATE,DELETE が使用できて 接続が切れるまで有効です。
SQL 文中の値を引数で変えることもできます。
db=# PREPARE sql_2 (varchar) AS SELECT tablename db-# from pg_tables db-# where tablename = $1; PREPARE
引数は 1つめから順番に 変数 $1,$2,$3... で受けます。
EXECUTE で実行するときに値を指定します。
db=# EXECUTE sql_2('pg_index');
tablename
-----------
pg_index
(1 row)
大きなメリットとして EXECUTE したときに実行計画などの準備をしないため ( PREPARE したときに準備されます) 同じ SQL 文を何度も使用する場合、速度が上がります。
cal コマンドで月曜日を先頭にする
cal コマンドで カレンダーを表示することができます。
$ cal 5月 2010 日 月 火 水 木 金 土 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 $ cal 9 2010 9月 2010 日 月 火 水 木 金 土 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
.bash_profile に入れてログイン時にカレンダーを表示させたり ちょっと曜日を知りたい時に使えるコマンドです。
ただ、私の場合 カレンダーは月曜日が先頭なのが嬉しいのですが 最近の cal はそんなオプション "-m" もあるようです。
$ cal -m 5月 2010 月 火 水 木 金 土 日 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
他にも年単位の表示や...
$ cal -y 2010 1月 2月 3月 日 月 火 水 木 金 土 日 月 火 水 木 金 土 日 月 火 水 木 金 土 1 2 1 2 3 4 5 6 1 2 3 4 5 6 3 4 5 6 7 8 9 7 8 9 10 11 12 13 7 8 9 10 11 12 13 10 11 12 13 14 15 16 14 15 16 17 18 19 20 14 15 16 17 18 19 20 17 18 19 20 21 22 23 21 22 23 24 25 26 27 21 22 23 24 25 26 27 24 25 26 27 28 29 30 28 28 29 30 31 31 4月 5月 6月 日 月 火 水 木 金 土 日 月 火 水 木 金 土 日 月 火 水 木 金 土 1 2 3 1 1 2 3 4 5 4 5 6 7 8 9 10 2 3 4 5 6 7 8 6 7 8 9 10 11 12 11 12 13 14 15 16 17 9 10 11 12 13 14 15 13 14 15 16 17 18 19 18 19 20 21 22 23 24 16 17 18 19 20 21 22 20 21 22 23 24 25 26 25 26 27 28 29 30 23 24 25 26 27 28 29 27 28 29 30 30 31 7月 8月 9月 日 月 火 水 木 金 土 日 月 火 水 木 金 土 日 月 火 水 木 金 土 1 2 3 1 2 3 4 5 6 7 1 2 3 4 4 5 6 7 8 9 10 8 9 10 11 12 13 14 5 6 7 8 9 10 11 11 12 13 14 15 16 17 15 16 17 18 19 20 21 12 13 14 15 16 17 18 18 19 20 21 22 23 24 22 23 24 25 26 27 28 19 20 21 22 23 24 25 25 26 27 28 29 30 31 29 30 31 26 27 28 29 30 10月 11月 12月 日 月 火 水 木 金 土 日 月 火 水 木 金 土 日 月 火 水 木 金 土 1 2 1 2 3 4 5 6 1 2 3 4 3 4 5 6 7 8 9 7 8 9 10 11 12 13 5 6 7 8 9 10 11 10 11 12 13 14 15 16 14 15 16 17 18 19 20 12 13 14 15 16 17 18 17 18 19 20 21 22 23 21 22 23 24 25 26 27 19 20 21 22 23 24 25 24 25 26 27 28 29 30 28 29 30 26 27 28 29 30 31 31
前後 1 ヵ月ずつの表示もあります。
$ cal -3 4月 2010 5月 2010 6月 2010 日 月 火 水 木 金 土 日 月 火 水 木 金 土 日 月 火 水 木 金 土 1 2 3 1 1 2 3 4 5 4 5 6 7 8 9 10 2 3 4 5 6 7 8 6 7 8 9 10 11 12 11 12 13 14 15 16 17 9 10 11 12 13 14 15 13 14 15 16 17 18 19 18 19 20 21 22 23 24 16 17 18 19 20 21 22 20 21 22 23 24 25 26 25 26 27 28 29 30 23 24 25 26 27 28 29 27 28 29 30 30 31
Linux で cd する前のディレクトリに戻る
ものすごい小ネタですが 知っていると便利です。
cd コマンドはディレクトリを移動することができます。
~:$ cd /var/log/apache2 /var/log/apache2:$ cd /etc/apache2/conf.d /etc/apache2/conf.d:$
1 つ前のディレクトリに戻りたくなったときは 次のように パスの代わりにハイフン "-" を指定します。
/etc/apache2/conf.d:$ cd - /var/log/apache2:$
履歴で持っているわけではないので 繰り返しハイフンを指定しても 2 つのディレクトリを行き来するだけです。
/etc/apache2/conf.d:$ cd - /var/log/apache2:$ cd - /etc/apache2/conf.d:$ cd - /var/log/apache2:$
ログと設定ファイルのディレクトリを 行き来するときなど便利です。
積ん読 2010/05/04
- 実践、Gumblar対策 Webサーバーへの不正なアップロードを防ぐ - ITpro (2010/04/30)
- 無料の「読書管理サービス」8選 - CNET Japan (2010/05/03)
- Windows の良いメンテナンス方法、悪いメンテナンス方法をご存知でしょうか? - ライフハッカー (2010/05/01)
- Google マップにGoogleEarthの3Dビューが登場 - ライフハッカー (2010/05/03)
chown コマンドでグループも変更する
Unix/Linux には ファイルの所有権を変更する chown というコマンドがあります。 このコマンドは ユーザだけでなくグループも同時に変更することができます。
所有権のユーザだけ変える書式は次のようになります。
# chown testuser1 /home/testuser1/test.txt
グループも同時に変える場合は コロン ":" で区切って グループ名を指定します。
# chown testuser1:testgroup1 /home/testuser1/test.txt
GNU 版では、コロンの代わりに ドット "." も使えますが プロキシの認証などユーザの区切りに コロンはよく使用するので コロンで覚えておく方が無難だと思います。
ユーザ名とコロンだけで グループ名を指定しない場合は 指定したユーザ名(下の場合は testuser1 )の ログイングループを指定したことになります。
# chown testuser1: /home/testuser1/test.txt
ログイングループを調べなくても良いので 覚えておくと便利です。
上の例とは逆にユーザ名を指定しない場合は グループの変更になります。 これは chgrp と同じです。
# chown :testgroup1 /home/testuser1/test.txt
オマケですが、cp などのコマンドと同様に -R オプションで再帰(サブディレクトリ以下にも適用)ができます。
# chown -R testuser1:testgroup1 /home/testuser1
Excel のフィル
Excel には「連続データの作成」という便利な技があります。
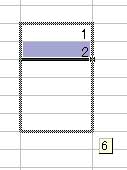
よく上の図のようにマウスで範囲を広げて生成しているのを 見かけるのですが、範囲が広い場合、マウスがスライドし過ぎて かなり下の行まで行ってしまうことがあります。

これを防ぐというか、 そもそも「連続データの作成」は、『フィル』という機能の中にあるので 編集メニューから選んで実行することができます。
まず範囲を選択します。 このときはドラッグ&ドロップする必要はないので [Shift] キーなどを使ってゆっくり選択できます。
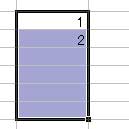
次にメニューから「編集」→「フィル」→「連続データの作成」と 選択します。
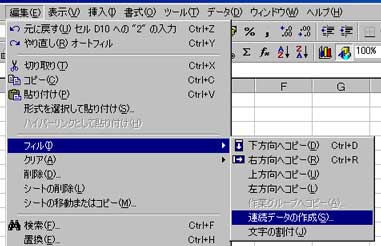
ポップアップウィンドウが出ます。
1 ずつ加算していく場合はデフォルトで OK です。
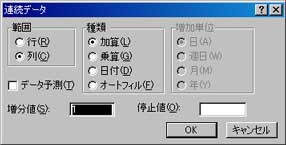
これで連続データが作成できました。
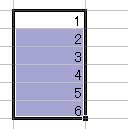
『フィル』には他にも機能がありますが あまり使うことはないと思います。 ドラッグ&ドロップによる「連続データの生成」で マウスが滑って どうしても上手く選択できないときに この機能を思い出してみてください。
なにわオラクル倶楽部のノベルティ
先日、なにわオラクル倶楽部で 10point のノベルティの 『 Oracle キティちゃん』をゲットしました。

なにわオラクル倶楽部 というのは オラクルの西日本支社が主催して行なっている 技術者向けのコミュニティです。
過去にも紹介しましたが、隔週水曜日の 18:30 〜 20:00 の時間帯で 質の高い講習を実施してくれるので Oracle 初心者の新人プログラマなんかにも 役に立つ実戦的な勉強会です。
また、ノベルティとして、3 回目、5 回目、10 回目の 参加で Oracle のグッズをくれます。 毎回参加シールを貰えるので それを会員カードの裏に貼っていきます。
記念品を貰うために行くわけではありませんが そんなちょっとした遊びを交えて 楽しく勉強していく形は とても面白いと感じます。
オラクル社では支店ごとに 「どさんこオラクル倶楽部(北海道支店)」 「オラクルイヌワシ倶楽部(東北支店)」 「ほ!Clickオラクル倶楽部(北陸支店)」 「よかたいオラクル倶楽部(九州支店)」 「おらくる人倶楽部(沖縄支店)」 といった形でコミュニティを設けています。
開催形式はコミュニティごとに異なるようですので 興味がある人は 近くで開催されているものを調べてみると良いと思います。
積ん読 2010/05/01
- もはや地上波とネットを区別する意味ない--radikoで見えたラジオ業界の地殻変動 - CNET Japan (2010/04/30)
- WinSCPスクリプト入門:コマンドやバッチファイルとの連携による自動処理 - SourceForge.JP (2010/04/20)
- 6年前に立てられた「CPU未来予測スレ」の答え合わせは…? - 教えて君.net (2010/04/26)
