2010年 04月
- 積ん読 2010/04/30
- 積ん読 2010/04/28
- Vista ではコマンドプロンプトにドラッグ&ドロップできない
- 積ん読 2010/04/26
- PostgreSQL の ANALYZE の動きを確認する
- 積ん読 2010/04/22
- PostgreSQL の VACUUM の動きを確認する
- 積ん読 2010/04/20
- パスワードを一括で変更する
- 積ん読 2010/04/17
- 積ん読 2010/04/15
- 積ん読 2010/04/13
- 積ん読 2010/04/12
- 積ん読 2010/04/11
- 積ん読 2010/04/08
- Bash で 配列を使ってみる その 2
- Bash で 配列を使ってみる その 1
- IFS (Internal Field Separator) の値を表示する
- 積ん読 2010/04/03
- Bash の for 文 その 2
- Bash の for 文
積ん読 2010/04/30
- これだけは押さえておきたいIIS FTPサーバ・セキュリティ(前編) ―― Gumblarに負けないコンテンツ更新システムの基礎作り ―― - @IT (2010/04/28)
- 【Windows 7 ユーザーズ・ワークベンチ】 64bit版Windows 7で困ること、うれしいこと - PC Watch (2010/04/28)
- プログラミング言語の速度とアプリケーションの速度がいかに関係ないかがわかるグラフ - kwatchの日記 (2010/04/30)
- Ubuntu 10.04 LTS リリース - Ubuntu Japanese Team (2010/04/30)
- ホスト、C/S、ERP、Web、クラウド、一体どうすればいいのでしょう - ITpro (2010/04/30)
- Rubyを中国の優れたエンジニアに根付かせたい - ITpro (2010/04/30)
- レッドハット、「RHEL 6」ベータ版をリリース--「Xen」は含まれず - ITpro (2010/04/27)
積ん読 2010/04/28
- 日本語化担当者が語るSmall Basic活用術 - @IT (2010/04/27)
- マイクロソフト、無償の開発環境“Visual Studio 2010 Express”シリーズを公開 Visual Basic/C#/C++の各言語およびWeb開発向けの計4製品が利用可能 - 窓の杜 (2010/04/28)
- 細かいJavaScriptの仕様や習慣やテク集 - 三等兵 (2010/04/27)
- [CSS]テキストボックスで表示しきれないテキストを表示するスタイルシート - コリス (2010/04/26)
Vista ではコマンドプロンプトにドラッグ&ドロップできない
Windows Vista では XP までのように ファイルをコマンドプロンプトにドラッグ&ドロップして ファイルのパスを貼ることができません。
方法が無いかと検索してみると次のような記事がありました。
【参考サイト】
ここが変わったWindows Vista 100連発! ― 第49回 “パスとしてコピー”でコマンドプロンプトにパス名を渡す
これによると Vista では [Shift] キーを押しながら右クリックすると 次のように「パスとしてコピー」するメニューが出てくるので これでファイルのパスをコピーしてから コマンドプロンプトに貼り付けるそうです。
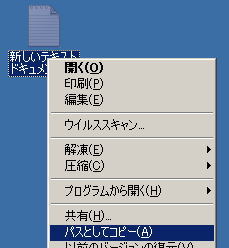
ドラッグ&ドロップが便利だったので残念です。
積ん読 2010/04/26
- 日常の中で刻まれていくマウスカーソルの軌跡がアートを生み出す「IOGraphica」 - 窓の杜 (2010/04/23)
- コンテンツをつかんで操作する新感覚ウェブサイト -Grip - コリス (2010/04/23)
- webページを綺麗にpdfにしてくれる、至れり尽くせりな"Web2PDF"。 - あまたの何かしら。 (2010/04/25)
PostgreSQL の ANALYZE の動きを確認する
前回 VACUUM の確認について書きましたが 今回は ANALYZE の確認について書きたいと思います。
まずはテーブル analyze_test を作成します。
db=# CREATE TABLE analyze_test (f1 VARCHAR(10), f2 INTEGER);
CREATE TABLE
ANALYZE も情報を pg_stat_all_tables から取得できます。
db=# SELECT * FROM pg_stat_all_tables db-# WHERE relname = 'analyze_test'; -[ RECORD 1 ]----+------------------------------ relid | 16469 schemaname | public relname | analyze_test seq_scan | 2 seq_tup_read | 9 idx_scan | idx_tup_fetch | n_tup_ins | 5 n_tup_upd | 1 n_tup_del | 1 n_tup_hot_upd | 1 n_live_tup | 4 n_dead_tup | 0 last_vacuum | last_autovacuum | last_analyze | last_autoanalyze |
ANALYZE する前はこのような状態です。
また、pg_stat_all_tables の他に 列ごとの統計情報が pg_stats ビューから取得できます。
db=# SELECT * FROM pg_stats WHERE tablename = 'analyze_test';
(No rows)
ANALYZE する前は レコードが取得できません。
それでは ANALYZE を実行します。
db=# ANALYZE analyze_test;
ANALYZE
状態を確認します。
db=# SELECT * FROM pg_stat_all_tables db-# WHERE relname = 'analyze_test'; -[ RECORD 1 ]----+------------------------------ relid | 16469 schemaname | public relname | analyze_test seq_scan | 2 seq_tup_read | 9 idx_scan | idx_tup_fetch | n_tup_ins | 5 n_tup_upd | 1 n_tup_del | 1 n_tup_hot_upd | 1 n_live_tup | 4 n_dead_tup | 0 last_vacuum | last_autovacuum | last_analyze | 2010-04-24 15:49:12.383112+09 last_autoanalyze |
last_analyze に ANALYZE した時刻が格納されました。
列ごとの統計情報を確認します。
db=# SELECT * from pg_stats WHERE tablename = 'analyze_test'; -[ RECORD 1 ]-----+-------------------------- schemaname | public tablename | analyze_test attname | f1 null_frac | 0 avg_width | 6 n_distinct | -1 most_common_vals | most_common_freqs | histogram_bounds | {00001,00003,00004,00005} correlation | -0.2 -[ RECORD 2 ]-----+-------------------------- schemaname | public tablename | analyze_test attname | f2 null_frac | 0 avg_width | 4 n_distinct | -1 most_common_vals | most_common_freqs | histogram_bounds | {15,30,40,50} correlation | -0.2
ANALYZE したテーブルの列のレコードが追加されています。
histogram_bounds に列の値のサンプルが入っています。
(行が少ないので全ての値が入っています)
積ん読 2010/04/22
- つまるところ“クラウド”って何? - 日経ビジネスオンライン (2010/03/26)
- マイクロソフトが「Office 2010」の発売日と価格を発表、「Office IME 2010」の単体での無償提供も - GIGAZINE (2010/04/22)
- 約6年ぶりにバージョンアップした老舗IPメッセンジャー「IP Messenger」v2.07公開 - 窓の杜 (2010/04/21)
PostgreSQL の VACUUM の動きを確認する
PostgreSQL は データを更新したときや 削除したときに レコードに「不要」マークを付けるという処理を行ないます。
「不要」マークの付いたレコード(以下、不要なレコード)は そのままでは再利用できないのでデータを挿入しなくても 更新を繰り返すだけで テーブルの使用するスペースは広がっていきます。
VACUUM は、不要になったレコードのスペースを 再利用可能にします。 今回は、その動きを確認してみたいと思います。
まずは新しくテーブル vacuum_test を作成します。
db=# CREATE TABLE vacuum_test (f1 VARCHAR(10), f2 INTEGER);
CREATE TABLE
情報は pg_stat_all_tables カタログから取得します。
db=# SELECT n_live_tup,n_dead_tup,last_vacuum,last_autovacuum db-# FROM pg_stat_all_tables db-# WHERE relname = 'vacuum_test'; -[ RECORD 1 ]----+------------ n_live_tup | 0 n_dead_tup | 0 last_vacuum | last_autovacuum |
テーブルを作成した時点では上のようになっています。
VACUUM に関連する主な列のみ取得しています。
それぞれの列の意味は次のようになります。
| 列名 | 説明 |
|---|---|
| n_live_tup | 有効なレコード数 |
| n_dead_tup | 不要になったレコード数 |
| last_vacuum | 最後に VACUUM を実行した時刻 |
| last_autovacuum | 最後に 自動 VACUUM が実行された時刻 |
レコードを挿入します。
INSERT INTO vacuum_test VALUES ('00001', 10);
INSERT INTO vacuum_test VALUES ('00002', 20);
INSERT INTO vacuum_test VALUES ('00003', 30);
INSERT INTO vacuum_test VALUES ('00004', 40);
INSERT INTO vacuum_test VALUES ('00005', 50);
状態を確認します。
db=# SELECT n_live_tup,n_dead_tup,last_vacuum,last_autovacuum db-# FROM pg_stat_all_tables db-# WHERE relname = 'vacuum_test'; -[ RECORD 1 ]----+------------ n_live_tup | 5 n_dead_tup | 0 last_vacuum | last_autovacuum |
5 レコード挿入したので、有効なレコード数が 5 になりました。
次に 1 レコード削除します。
db=# DELETE FROM vacuum_test WHERE f1 = '00002';
DELETE 1
状態を確認します。
db=# SELECT n_live_tup,n_dead_tup,last_vacuum,last_autovacuum db-# FROM pg_stat_all_tables db-# WHERE relname = 'vacuum_test'; -[ RECORD 1 ]----+------------ n_live_tup | 4 n_dead_tup | 1 last_vacuum | last_autovacuum |
有効なレコード数が 4 になり 不要なレコード数が 1 になりました。
ついでに更新もします。
db=# UPDATE vacuum_test SET f2 = 15 WHERE f1 = '00001';
UPDATE 1
しつこく状態を確認します。
db=# SELECT n_live_tup,n_dead_tup,last_vacuum,last_autovacuum db-# FROM pg_stat_all_tables db-# WHERE relname = 'vacuum_test'; -[ RECORD 1 ]----+------------ n_live_tup | 4 n_dead_tup | 2 last_vacuum | last_autovacuum |
不要なレコード数が 1 増えました。
ここまでは準備です。 ようやく VACUUM を実行します。
db=# VACUUM vacuum_test;
VACUUM
状態を確認します。
db=# SELECT n_live_tup,n_dead_tup,last_vacuum,last_autovacuum db-# FROM pg_stat_all_tables db-# WHERE relname = 'vacuum_test'; -[ RECORD 1 ]----+------------------------------ n_live_tup | 4 n_dead_tup | 0 last_vacuum | 2010-04-20 22:20:20.560647+09 last_autovacuum |
不要なレコード数が 0 になりました。
last_vacuum に VACUUM を実行した時刻が入っています。
このように VACUUM で、不要になったレコードの スペースを再利用可能にすることができます。
積ん読 2010/04/20
- 『Universal Viewer』はほとんどのファイルを開けてくれるですって! - ライフハッカー (2010/04/19)
- 三洋機工がOpenOffice.orgを全社導入、コスト抑制見込む - ITpro (2010/04/13)
- 山形県が県庁での導入に向けOpenOffice.orgの評価を開始 - ITpro (2010/04/20)
パスワードを一括で変更する
Linux には パスワードを一括で変更できる chpasswd というコマンドがあります。 使い方は簡単で標準入力からユーザ名とパスワードのセットを渡すだけです。
例えば testuser1 のパスワードを hogehoge にする場合 次のように ユーザ名とパスワードをコロンで区切ってパイプします。
# echo "testuser1:hogehoge" | chpasswd
複数ユーザのパスワードを一括で変更する場合 次のように ファイルにユーザ名とパスワードのセットを記述します。
# vi passwd.txt
testuser1:hogehoge1 testuser2:hogehoge2 testuser3:hogehoge3
これをパイプで渡します。
# cat passwd.txt | chpasswd
全ユーザのパスワードを一括で初期化する場合など便利です。
積ん読 2010/04/17
- マイクロソフト、Webブラウザー用プラグイン「Silverlight 4」を正式公開 起動時間を30%短縮、実行速度を200%向上、そのほか多くの新機能を搭載 - 窓の杜 (2010/04/16)
- [CSS]角丸を少しでも滑らかに実装するスタイルシートのテクニック - コリス (2010/04/16)
- タスクマネージャよりも便利な『Process Explorer』が更新!数多くの新機能も! - ライフハッカー (2010/04/16)
- Si新書『ビックリするほど役立つ!! 理工系のフリーソフト50』概要 大崎 誠・林 利明・小原裕太・金子雄太 著 - サイエンス・アイWeb (2010/04/13)
- Linuxファイルシステムまとめ - マイコミジャーナル (2010/04/15)
積ん読 2010/04/15
- Javaに未修正の脆弱性、Webページを閲覧するだけで攻撃を受けるおそれ IE6/7/8や「Firefox」「Google Chrome」などWebブラウザー全般が対象 - 窓の杜 (2010/04/13)
- Mozilla、プラグインプロセスを分離した「Firefox」のテスト版「Lorentz」を公開 プラグインがクラッシュしてもWebブラウザー本体は巻き込まれない仕様に - 窓の杜 (2010/04/09)
- 「Firefox Lorentz」の“Out of Process Plugins”機能 - 窓の杜編集部ブログ (2010/04/09)
- GE、17年使える次世代LED電球を発表 - Engadget Japanese (2010/04/13)
積ん読 2010/04/13
- Visual Studio 2010の日本語版は4月20日から提供 - ITpro (2010/04/13)
- Goo.gl 短縮URLからQRコードを簡単に作る方法 - ライフハッカー (2010/04/13)
積ん読 2010/04/12
- Firefox の安定性が大幅に改善しているという調査結果が発表されました - Mozilla Japan ブログ (2010/04/09)
- “イチロー”を評価しない、会社の不条理 - 日経ビジネスオンライン (2010/04/08)
- IE9の登場で画像フォーマットの本命に浮上するSVG - ITpro (2010/04/02)
- SVGは普及する。WebデザイナーはCSSとともにSVGが必須科目に - Publickey (2010/04/07)
- JavaScriptでSVGのレーダーチャートを描画するライブラリ Raphael Radar をつくった - I CAN ’CAUSE I THINK I CAN! (2010/03/08)
積ん読 2010/04/11
- クラウドを支える“ゆるさ” - ITpro (2010/04/08)
- 2ケタの2乗の計算がサクっとできる暗算ハック - ライフハッカー (2010/04/05)
- エイプリルフールに海外の数学教師が披露した素敵なジョーク - blogs.com|おもしろブログ記事のまとめサイト (2010/04/08)
- 人工孵化ウナギから子・孫も、世界初「完全養殖」 - YOMIURI ONLINE (2010/04/09)
- [CSS]画像を使用しないでもCSS3ならここまでできる実用的な実装サンプル - コリス (2010/04/09)
- 手軽にウェブページの細部までチェックできるFirefoxのアドオン -PixelZoomer - コリス (2010/04/07)
積ん読 2010/04/08
- 人間VSコンピューター この世紀の決戦を楽しむために - 俺の邪悪なメモ (2010/04/05)
- 作りながら理解するファイルシステムの仕組み - @IT (2010/04/01)
- 「Google日本語入力」開発版アップデート、IME ON/OFF設定に対応 - INTERNET Watch (2010/04/05)
- 北朝鮮が独自の国産OS「Red Star」を開発、技術的には「10年遅れ」 - GIGAZINE (2010/04/07)
- “Pwn2Own 2010”で報告された重大な脆弱性を修正した「Firefox」v3.6.3が公開 - 窓の杜 (2010/04/05)
Bash で 配列を使ってみる その 2
前回( Bash で 配列を使ってみる その 1 )は値の格納でしたが 今回は配列らしく for ループを使って値を出力します。
まずは 普通の? for 文です。 配列の値を全て出力するには次のように 添え字に "@" か "*" を使います。
$ ARRAY=(one two three four) $ echo ${ARRAY[@]} one two three four $ echo ${ARRAY[*]} one two three four
これを for 文で使用します。
$ ARRAY=(one two three four) $ for item in ${ARRAY[@]} > do > echo $item > done one two three four
ただし、これは 1 つ問題があります。
Bash の for 文 その 2 で書きましたが for 文は IFS (デフォルトはスペースなど) で区切られた文字列でループさせることができるので 配列の要素が IFS を含む文字列の場合、次のようにループが増えてしまいます。
$ ARRAY=("one1 one2 one3" two three four) $ echo ${ARRAY[0]} one1 one2 one3 $ for item in ${ARRAY[@]} > do > echo $item > done one1 one2 one3 two three four
これを防ぐためにプログラム言語のような for 文を使用します。
配列の添え字の最大を取得するには次のようにします。
$ ARRAY=("one1 one2 one3" two three four) $ echo ${#ARRAY[@]} 4 $ echo ${#ARRAY[*]} 4
これを for 文で使用します。
$ ARRAY=("one1 one2 one3" two three four) $ for (( i = 0; i < ${#ARRAY[@]}; i++ )) > do > echo ${ARRAY[$i]} > done one1 one2 one3 two three four
1 つめの配列も正しく出力されました。
Bash で 配列を使ってみる その 1
まずは値の格納です。 直接 1 つずつ指定する方法です。
$ A[0]=one $ A[1]=two
もう一つは一括で指定する方法です。
$ A=(one two three four)
配列の値を出力するには "{}" (ブランケット)を 使用する必要があります。
$ echo ${A[0]}
ブランケットを指定しないと 変数 "$A" と "[0]" という文字の出力になってしまいます。
ちなみに 次のように添え字 0 の値は 添え字を指定しない変数の値と同じになります。
$ echo ${A[0]} one $ echo $A one
ですのでブランケットを使用しない場合は次のように出力されます。
$ echo $A[0]
one[0]
IFS (Internal Field Separator) の値を表示する
Bash の for 文 その 2 で IFS を出したんですが、 デフォルトの IFS の中身を表示することができないかなと 考えていました。
普通に出力しても次のようになってしまいます。
$ echo "[$IFS]"
[
]
次のサイトに良い方法が載っていました。
【参考サイト】
IFS - http://www.curri.miyakyo-u.ac.jp/pub/doc/sh/node31.html
$ echo -n "$IFS" | od -b 0000000 040 011 012 0000003 $ echo -n "$IFS" | od -c 0000000 \t \n 0000003
040 011 012 は 8進数です。
値としては スペース(0x20)、水平タブ(0x09)、改行(0x0A)になります。
積ん読 2010/04/03
- これでできる! クロスブラウザJavaScript入門 第2回 完全版:ブラウザとデバッグ環境 - 技術評論社 (2010/03/29)
- n年ExcelユーザーがExcel 2007を使うときの直感的リファレンス - バシャログ。 (2010/03/30)
- さまざまなプログラミング言語のソースコードを構文に従って色分け「Highlight」 - 窓の杜 (2010/03/29)
Bash の for 文 その 2
Bash の for 文 の続きです。
文字列内のリスト
次のように文字列の空白で区切られた項目をリストとして ループさせることができます。
$ ITEMS="one two three four" $ for item in $ITEMS > do > echo $item; > done; one two three four
正しくは空白ではなく IFS (Internal Field Separator) で定義されているもので 文字列を分割します。 IFS を変更すると区切りを変えることができます。
$ ITEMS="one/two/three four" $ IFS="/" $ for item in $ITEMS > do > echo $item; > done; one two three four
引数のリスト
他に引数のリストでループさせるというのもあります。
$ function test () { > for item in $* > do > echo $item; > done; > } $ test one two three four one two three four
Bash の for 文
Bash で使える for 文には色々な形があります。
候補のリスト
$ for item in one two three four > do > echo $item > done one two three four
in の後に並べた値をループさせます。
ディレクトリ・ファイルのリスト
$ for item in /tmp/* > do > echo $item > done /tmp/aaaa.txt /tmp/bbbb.txt
マッチする ディレクトリやファイルのパスでループさせます。
コマンドの結果のリスト
$ for item in $(wc /tmp/a.txt) > do > echo $item > done 0 3 9
コマンド置換を使って、実行結果でループさせます。
これを利用して seq コマンドを使う方法があります。
$ for item in $(seq 1 3) > do > echo $item > done 1 2 3
Java などの言語によくある for 文
言語でよくみかける 初期条件や繰り返し条件が セミコロンで区切られてる形式も使えます。
$ for (( item = 0; item < 3; item++ )) > do > echo $item > done 0 1 2
二重カッコ (()) を使います。
