2018�N 11��
- Excel �� �Z���̏����́u���ށv���u�W���v�ɖ߂��V���[�g�J�b�g
- Excel �� VLOOKUP �ł͌��������Ƀ��C���h�J�[�h���g����
- PostgreSQL �� �z����e�[�u���̂悤�Ɉ���
- �ς�� 2018/11/22
- PostgreSQL �� ���l�̏����_�ȉ��� 0 �����
- Excel �� �Z���̒l�̔�\���ɂ���
- �ς�� 2018/11/20
- Excel �̃V�[�g�� VeryHidden �ݒ�
- Excel �̃��[�U�[��`�����ɂ���uG/�W���v������
- PostgreSQL �ŁA�ꎞ�I�ɑS�Ẵg���K�[���ɂ���
- Windows �� �V�X�e�� �G���[ 1219 �������Ȃ��Ƃ��̑Ώ��A
- �����t�@�C�������� tar �R�}���h�Ōł߂�
- �ς�� 2018/11/14
- Windows ��� .htaccess �̂悤�ȃt�@�C�����쐬����
- �ς�� 2018/11/08
- Windows �� �V�X�e�� �G���[ 1219 �������Ȃ��Ƃ��̑Ώ��@
- find �R�}���h�œ������w�肵�Č��o����
- find �R�}���h�œ���̃t�@�C���ȍ~�̍X�V�����o����
- ORACLE �Ŏ��s���� SQL������s�v���\������
- tar �R�}���h�Ńp�X��ύX���ēW�J������
- tar �R�}���h�ňꕔ������W�J������
- �ς�� 2018/11/01
Excel �� �Z���̏����́u���ށv���u�W���v�ɖ߂��V���[�g�J�b�g
�i�g�p���Ă��� Excel �� Excel 2016 �ł��j
�Z���̏����́u���ށv���u�W���v�ɖ߂��V���[�g�J�b�g�ł��B
����ɓ��t�^�ɂȂ��Ă��܂����Z���� ������^�̃Z���̐�����L���ɂ������Ƃ��� �L�[�{�[�h�����ő���ł��֗��ł��B
�V���[�g�J�b�g�͎��̂悤�ɂȂ�܂��B
[Ctrl] + [Shift] + [~]
�����܂� �����́u���ށv���u�W���v�ɖ߂������Ȃ̂� �����̃t�H���g��F�A �Z���̔w�i�F�Ȃǂ� ���̂܂܂ł��B Word �� [Ctrl] + [Shift] + [n] �̂悤�� �������N���A����킯�ł͂���܂���B
Excel �� VLOOKUP �ł͌��������Ƀ��C���h�J�[�h���g����
�i�g�p���Ă��� Excel �� Excel 2016 �ł��j
VLOOKUP ���[�N�V�[�g���� ���������Ƀ��C���h�J�[�h���g���� �Ƃ����� �g���Ă��܂��܂��B
���̂悤�� ���C���h�J�[�h�� "*" ���܂܂�Ă���ꍇ�A�A�A
=VLOOKUP("*��v��",C2:D3,2,FALSE)
"�V��v��" �Ȃ���ɂ���ƁA���S��v�Ȃ̂� �����炪�q�b�g���Ă��܂��܂��B
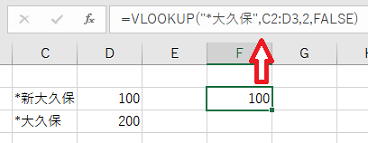
���̏ꍇ�A���̂悤�� ���C���h�J�[�h�� "*" �� "~" �� �G�X�P�[�v����K�v������܂��B
=VLOOKUP("~*��v��",C2:D3,2,FALSE)
"?" �����l�� "~" �ŃG�X�P�[�v���܂��B
=VLOOKUP("~?��v��",C2:D3,2,FALSE)
"~" ���̂��g�������Ƃ��� "~" �ŃG�X�P�[�v���܂��B
=VLOOKUP("~~��v��",C2:D3,2,FALSE)
VLOOKUP ���[�N�V�[�g���� ���������Ƀ��C���h�J�[�h���g�����Ƃ� ����Ȃɖ�����Ȃ����Ǝv���܂����A �t�� �Ӑ}�����܂܂�Ă���ꍇ�� �G�X�P�[�v���Ă��K�v�����邽�� ���ӂ��K�v�ł��B
PostgreSQL �� �z����e�[�u���̂悤�Ɉ���
�����ł��B
�i�g�p���Ă��� PostgreSQL �� PostgreSQL 9.3.12 �ł��j
PostgreSQL �� �z����e�[�u���̂悤�Ɉ������@�ł��B �f�[�^�̈ꊇ�o�^��A���̃e�X�g�Ȃǂɕ֗��ł��B
�܂��A�z��̒�`�͎��̂悤�ɂȂ�܂��B
'{value1,value2,value3}'
ARRAY ���Z�\�����g���Ǝ��̂悤�ɂȂ�܂��B
ARRAY['value1','value2','value3']
����͂܂� ARRAY ���Z�\���̕��� SQL �Ŏg�p���܂��B
SELECT field1::VARCHAR
FROM UNNEST(ARRAY['value1','value2','value3']) AS field1;
�g���܂킵���ǂ��悤�� FROM ��Ŏg�p���Ă��܂��B
�|�C���g�� UNNEST ���ł��B UNNEST �����g�p����� �z����s�W���ɓW�J���邱�Ƃ��ł��܂��B
[�Q�l]
9.18. �z����Ɖ��Z�q - PostgreSQL 9.3.2����
SQL �̎��s���ʂ͎��̂悤�ɂȂ�܂��B
db=# SELECT field1::VARCHAR db-# FROM UNNEST(ARRAY['value1','value2','value3']) AS field1; field1 -------- value1 value2 value3 (3 rows)
������g���� ���悤�� SQL �Ŏg�p������̃e�X�g�p SQL ���ȒP�ɍ��܂��B
SELECT field1::VARCHAR, test_function(field1::VARCHAR) AS result
FROM UNNEST(ARRAY['value1','value2','value3']) AS field1;
�����܂ł͈ꎟ���z��ł����B
�z����e�[�u���̂悤�Ɉ����̂� �� 1 �ł͍���܂��ˁB
�����A2 �����z��ɂ���ƈ������ʓ|�ɂȂ邽�� �z��̕������`�� ARRAY ���Z�\����g�ݍ��킹�� ���̂悤�ɒ�`���܂��B
ARRAY['{100,value1,2018/10/01}','{200,value2,2018/10/02}']
����� SQL �Ŏg���܂��B
SELECT (fields::VARCHAR[])[1]::NUMERIC AS field1 , (fields::VARCHAR[])[2]::VARCHAR AS field2 , (fields::VARCHAR[])[3]::DATE AS field3 FROM UNNEST(ARRAY['{100,value1,2018/10/01}' ,'{200,value2,2018/10/02}']) AS fields;
�|�C���g�� "fields" �ɔz��̕������`������̂� ����� "VARCHAR[]" �ŃL���X�g���܂��B
SQL �̎��s���ʂ͎��̂悤�ɂȂ�܂��B
db=# SELECT (fields::VARCHAR[])[1]::NUMERIC AS field1 db-# , (fields::VARCHAR[])[2]::VARCHAR AS field2 db-# , (fields::VARCHAR[])[3]::DATE AS field3 db-# FROM UNNEST(ARRAY['{100,value1,2018/10/01}' db-# ,'{200,value2,2018/10/02}']) AS fields; field1 | field2 | field3 --------+--------+------------ 100 | value1 | 2018-10-01 200 | value2 | 2018-10-02 (2 rows)
�l�ɃJ���}���g�p����ꍇ�� ���̂悤�ɃG�X�P�[�v���܂��B
ARRAY['{100,val\,ue1,2018/10/01}','{200,value2,2018/10/02}']
�ς�� 2018/11/22
- �u�ꎞ��~�v�́u�i�߁v�H�@AI���x���ߖ��� - ITmedia NEWS (2018/11/22)
PostgreSQL �� ���l�̏����_�ȉ��� 0 �����
�����ł��B
�i�g�p���Ă��� PostgreSQL �� PostgreSQL 9.3.12 �ł��j
��̌^�� "NUMERIC(10,4)" �̂悤�ȏꍇ ���̂܂� SQL �Ńf�[�^���擾���� "123456" �� "123456.0000" �̂悤�Ɏ擾����܂��B
����́A�����_�ȉ��� 0 �������@�ł��B
�ȉ��� SQL �� �e�[�u���ƃf�[�^���쐬���܂��B
CREATE TABLE table1 (
field1 NUMERIC(10,4)
);
INSERT INTO table1 (field1)
VALUES (123456.0000)
, (123456.5000)
, (123456.0500)
, (123456.0050)
, (123456.0005);
SQL �����s�B
db=# CREATE TABLE table1 ( db(# field1 NUMERIC(10,4) db(# ); CREATE TABLE
db=# INSERT INTO table1 (field1) db-# VALUES (123456.0000) db-# , (123456.5000) db-# , (123456.0500) db-# , (123456.0050) db-# , (123456.0005); INSERT 0 5
�܂��� ���ʂɃf�[�^���擾���Ă݂܂��B
db=# SELECT field1 db-# FROM table1; field1 ------------- 123456.0000 123456.5000 123456.0500 123456.0050 123456.0005 (5 rows)
�����_�ȉ��� 0 �� �����Ă��܂��ˁB
�ϐ��x�� "DOUBLE PRECISION" �^�� �L���X�g���܂��B
PostgreSQL �̃L���X�g�� �Z�~�R���� 2 �ł��B
xxxx::DOUBLE PRECISION
���� SQL �� ���̂܂܂̎擾�ifield1�j�� �L���X�g���Ď擾�ifield1+�j���r���Ă݂܂��B
db=# SELECT field1 db-# , field1::DOUBLE PRECISION AS "field1+" db-# FROM table1; field1 | field1+ -------------+------------- 123456.0000 | 123456 123456.5000 | 123456.5 123456.0500 | 123456.05 123456.0050 | 123456.005 123456.0005 | 123456.0005
�����_�ȉ��� 0 �� ���Ă��܂��ˁB
����� �v���O��������ł� �悭������@�ł��B
�������A"DOUBLE PRECISION" �� �s���m�ȉϐ��x�̐��l�f�[�^�^�ł��̂� ���x�̖��ɂ͒��ӂ���K�v������܂��B
Excel �� �Z���̒l�̔�\���ɂ���
�i�g�p���Ă��� Excel �� Excel 2016 �ł��j
Excel �� �u�Z���̒l���\���ɂ���v�Ƃ����A�����̐F�𔒂ɂ�����@������܂��B
�������A���R�Ȃ��炱�̕��@�ł� �w�i�̐F��ς��Ă��܂��� �l�������Ă��܂��܂��B
���̃��[�U�[��`�������g�p���邱�ƂŁA �Z���̒l���\���ɂ��邱�Ƃ��ł��܂��B
;;; (�Z�~�R����3��)
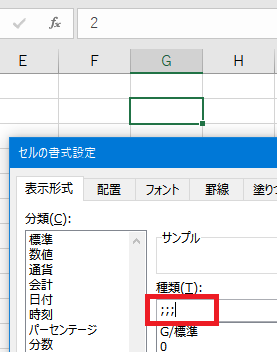
����� �l���\������Ȃ��Ȃ�܂��B
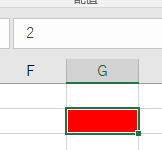
������� �l���\������Ă��Ȃ������ł��̂� �������痘�p���邱�Ƃ͂ł��܂��B
�����̐F��ς�����@�ƈ���� �Z�����e�L�X�g�G�f�B�^�ɃR�s�[�����Ƃ��͋��ŃR�s�[�ł����� �̎��������Ŏז����Ȃ��i�����̐F��ς��邾���̏ꍇ�͗̎��������ɉe������j�Ȃ� ���ɂ��ǂ��ʂ�����܂��B
�ς�� 2018/11/20
- �y�X�V�z�l�b�g�Ŋg�U�����R���摜�u�����̎�b�v ���̒������Ȃ����吶���u�����}���K�v�𓊍e���b��� - BuzzFeed (2018/11/17)
Excel �̃V�[�g�� VeryHidden �ݒ�
�i�g�p���Ă��� Excel �� Excel 2016 �ł��j
Excel �̔�\���V�[�g�Ƀf�[�^���i�[���� ���̃V�[�g���琔���ŎQ�Ƃ���A�Ȃ�Ă��Ƃ͂悭����܂��� ���̔�\���̃V�[�g���ȒP�ɂ͕\�����ꂽ���Ȃ��Ƃ��̕��@�ł��B
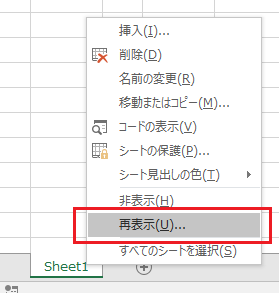
�u�u�b�N�̕ی�v�ŁA�V�[�g�\����ύX�s�ɂ��邱�Ƃł� �V�[�g���ĕ\���ł��Ȃ����邱�Ƃ͂ł��܂��B
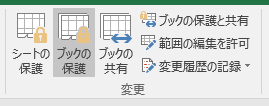
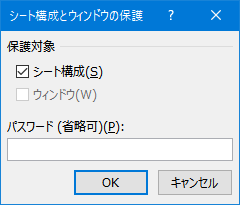
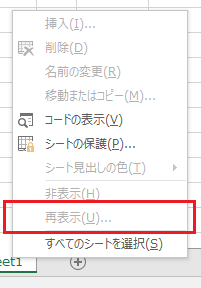
�����A���̏ꍇ�� �V�[�g�̒lj���V�[�g���̕ύX���ł��Ȃ��Ȃ��Ă��܂��܂��B
�����ŁA Excel �� VBA ������ �V�[�g�̐ݒ��ύX���܂��B
�u�R�[�h�̕\�� (V)�v���N���b�N�B
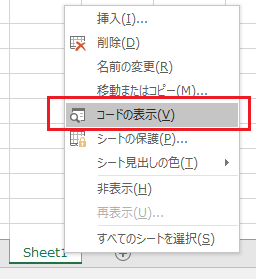
VBA �̉�ʂ��\������܂��B
�����ŁA��\���ɂȂ��Ă���V�[�g�uSheet2�v�́u�v���p�e�B�v�́uVisible�v���������Ă݂܂��B
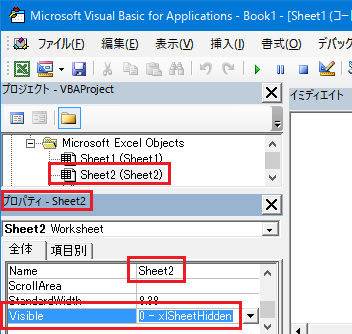
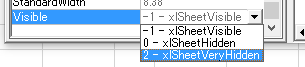
�uVisible�v�����ɂ� "0 - xlSheetHidden" ���ݒ肳��Ă��܂��B ���ꂪ�ʏ�� Excel ���Őݒ肵���u��\���v��Ԃł��B
���́uVisible�v�����ɂ� �u�\���v��Ԃł��� "-1 - xlSheetVisible" �ȊO�� "2 - xlSheetVeryHidden" �Ƃ��� �����ɂ��������Ȑݒ肪����܂��B
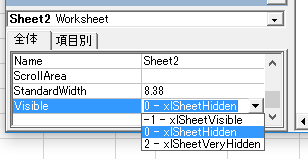
"2 - xlSheetVeryHidden" ��ݒ肵�Ă݂܂��B
����ƁAExcel �̃V�[�g���ł͍ĕ\���ł��Ȃ��Ȃ�܂����B
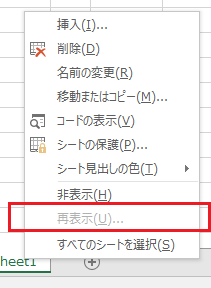
�������u�ʏ�̔�\���v�̃V�[�g�����ɂ���ꍇ�́A ���̃V�[�g�̍ĕ\���͉\�ł��B
��ɕ\�������Ȃ��A�Ƃ����킯�ł͂Ȃ��ł��� ���̃V�[�g�̉^�p�ƕ����邱�Ƃ��ł��܂��̂ŕ֗��ł��B
Excel �̃��[�U�[��`�����ɂ���uG/�W���v������
�i�g�p���Ă��� Excel �� Excel 2016 �ł��j
Excel �̃Z���̏����ݒ�̕��ށu���[�U�[��`�v�� �����l�ɁuG/�W���v�ƕ\������܂��B
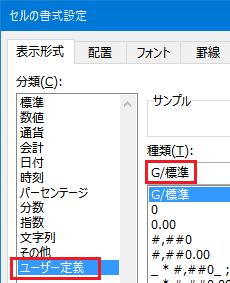
����������̂悤�ŁA���̂悤�ݒ肵�āA�A�A
G/�W���N�Q���Y

��������͂��Ă݂܂��B

���̂悤�ɂȂ�܂��B

�uG/�W���N�Q���Y�v�� "G/�W��" �̕����� "3" �ŁA"�N�Q���Y" �̕�����������Ƃ��ĘA�����ꂽ�悤�ł��B
���������͂����ꍇ�͂��̂܂܂ł��ˁB

"G/�W��" �ł͂Ȃ� "�W��" �ł������悤�ŁA ���̂悤�ɐݒ肷��ƁA�A�A
�W���f�X


���̂悤�ɂȂ�܂��B
"G" ���܂߂āu�Ȃ낤�H�v�Ǝv���Ă��܂������A ���̃T�C�g�ɏ����Ă���܂����B
[�Q�l]
Excel�i�G�N�Z���j�̕\���`���Ō�������uG/�W���v�Ƃ͉��̈Ӗ��H | Prau�i�v���E�jOffice�w�K��
"G/�W��" �Ƃ����̂́AExcel �̏�����Ԃ́A �����I�Ɏl�̌ܓ���w���\�������Ă���鏑���Ƃ̂��Ƃł��B


�܂�A"G/�W���N�Q���Y" �̂悤�ɐݒ肷��̂� �uExcel �̏�����Ԃ̏����v�Ɂu�������"�N�Q���Y�v��A��������A�Ƃ����Ӗ��ɂȂ�悤�ł��B
PostgreSQL �ŁA�ꎞ�I�ɑS�Ẵg���K�[���ɂ���
�����ł��B
�i�g�p���Ă��� PostgreSQL �� PostgreSQL 9.3.12 �ł��j
PostgreSQL �� �ł��邾�����ɉe����^���Ȃ��悤�� �ꎞ�I�ɑS�Ẵg���K�[���ɂ������Ǝv���Ă����� ���̂悤�ȕ��@������܂����B
[�Q�l]
PostgreSQL�ňꎞ�I��trigger��S�Ė���������@ - Qiita
SET session_replication_role = replica;
�N���C�A���g�ڑ��̕ϐ��usession_replication_role�v��ύX������@�� ���̕ϐ��́A�g���K����у��[���̔��s�𐧌䂷�邻���ł��B
[�Q�l]
18.11. �N���C�A���g�ڑ��f�t�H���g - PostgreSQL 9.3.2����
���ۂɎ����Ă݂܂��B
�܂��Atable1 �� table2 ���쐬�B
CREATE TABLE table1 (
field1 INTEGER
, field2 INTEGER
);
CREATE TABLE table2 (
field1 INTEGER
);
table1 �� INSERT ���� field1 �̒l�� field2 �ɃZ�b�g���� BEFORE �g���K�[���쐬�B
CREATE FUNCTION before_func1()
RETURNS TRIGGER AS $$
BEGIN
NEW.field2 := NEW.field1;
RETURN NEW;
END;
$$ LANGUAGE 'plpgsql';
CREATE TRIGGER before_trigger1
BEFORE INSERT ON table1
FOR EACH ROW EXECUTE PROCEDURE before_func1();
table1 �� INSERT ���� table2 �Ƀ��R�[�h�� INSERT ���� AFTER �g���K�[���쐬�B
CREATE FUNCTION after_function1()
RETURNS TRIGGER AS $$
BEGIN
INSERT INTO table2 (field1) VALUES (NEW.field1);
RETURN NULL;
END;
$$ LANGUAGE 'plpgsql';
CREATE TRIGGER after_trigger1
AFTER INSERT ON table1
FOR EACH ROW EXECUTE PROCEDURE after_function1();
�e�[�u���ƃg���K�[���쐬������A���� SQL �����s���܂��B
INSERT INTO table1 (field1) VALUES (1);
table1 �� INSERT �B
db=# INSERT INTO table1 (field1) VALUES (1);
INSERT 0 1
table1 ���m�F�B
db=# SELECT * FROM table1;
field1 | field2
--------+--------
1 | 1
(1 row)
BEFORE �g���K�[�� field2 �ɒl���Z�b�g����Ă��܂��B
table2 ���m�F�B
db=# SELECT * FROM table2;
field1
--------
1
(1 row)
AFTER �g���K�[�� ���R�[�h�� INSERT ����Ă��܂��B
���ɃN���C�A���g�ڑ��̕ϐ��usession_replication_role�v�������܂��� �܂������l���m�F�B
db=# SHOW session_replication_role;
session_replication_role
--------------------------
origin
(1 row)
�����l�́uorigin�v�ł����B
�N���C�A���g�ڑ��̕ϐ��usession_replication_role�v�� �ureplica�v��ݒ肵�܂��B
db=# SET session_replication_role = replica;
SET
db=# SHOW session_replication_role;
session_replication_role
--------------------------
replica
(1 row)
�����ƕύX����Ă܂��B
�������Ɠ��� INSERT �������s�B
�i�e�[�u���̃��R�[�h�̓N���A�ςł��j
db=# INSERT INTO table1 (field1) VALUES (1);
INSERT 0 1
table1 ���m�F�B
db=# SELECT * FROM table1;
field1 | field2
--------+--------
1 |
(1 row)
BEFORE �g���K�[�����s����Ȃ��������� field2 �ɒl���Z�b�g����Ă��܂���B
table2 ���m�F�B
db=# SELECT * FROM table2;
field1
--------
(0 rows)
AFTER �g���K�[�����s����Ȃ��������� ���R�[�h�� INSERT ����Ă��܂���B
�g���K�[�͎��s����܂���ł����B
����͕֗��ł��ˁB
������̃Z�b�V�����ł͒ʏ�ʂ�̓�������܂��B
�������A���������ۂ���Ȃ��Ȃ�\��������̂� ���R�Ȃ���T�d�Ɏ��s����K�v������܂��B
Windows �� �V�X�e�� �G���[ 1219 �������Ȃ��Ƃ��̑Ώ��A
�����ł��B
�i�g�p���Ă��� Windows �� Windows 10 �ł��j
�O�Ɂu�V�X�e�� �G���[ 1219 �������Ȃ��Ƃ��̑Ώ��@�v�������܂����� ����́u�V�X�e�� �G���[ 1219�v�����������Ƃ��� �u�Ƃ肠�����A���������Ă������v�Ƃ������e�ł��B
�܂� NET USE �����܂��� �o�Ă��Ȃ����獢��킯�ł��B
C:\> NET USE
�V�����ڑ��͋L������܂���B
�ꗗ�ɃG���g�������݂��܂���B
���������Ƃ��� ���̏ꏊ���`�F�b�N���Ă݂܂��B
�u�R���g���[���p�l���v����u���[�U�A�J�E���g�v��I���B

�u���i���̊Ǘ��v���N���b�N�B
�E���ɂ���uWindows �F�؏��v���N���b�N�B
�ڑ����悤�Ƃ��Ă���T�[�o�̏�\�����ꂽ�� ���̂����Łu�V�X�e�� �G���[ 1219�v���o�Ă���\��������܂��B
�폜���Ė��Ȃ���u�폜�v���N���b�N�B
���̏��̓T�[�o�ڑ����Ɂu���i�����L������v�Ƀ`�F�b�N������ �o�^����܂��B
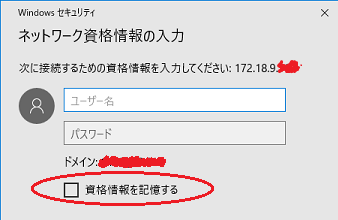
�폜���Ė��Ȃ���u�폜�v���N���b�N�B
����Łu�V�X�e�� �G���[ 1219�v�������邱�Ƃ�����܂��B
�����t�@�C�������� tar �R�}���h�Ōł߂�
�����ł��B
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
find �R�}���h�Ŏ擾�����X�V�����V�����t�@�C�������� tar �R�}���h�� �ł߂���@�ł��B
�X�V���́A��r�Ώۂ̃t�@�C�����V�������̂��擾���܂��B �i���̕��@�ɂ��ẮA�O�ɏ����Ă����̂ŁA��������Q�Ƃ��Ă��������j
�܂��͊��ϐ��̐ݒ�B
��r�Ώۂ̃t�@�C���iBASE_FILE_PATH�j��
�ł߂�TAR�t�@�C���iTAR_FILE_PATH�j�̃p�X��ݒ肵�܂��B
$ BASE_FILE_PATH=./last_update.txt $ TAR_FILE_PATH=/tmp/xxxxxx
������TAR�t�@�C�������݂���Ƃ�낵���Ȃ����� �O�̂��߂ł����A0�o�C�g�ŏ㏑�����Ă����܂��B
$ cat /dev/null > ${TAR_FILE_PATH}.tar
find �R�}���h�Ńt�@�C�����擾���� tar �R�}���h�Ōł߂܂��B ���̂Ƃ��Atar �R�}���h�ł� �NjL "r" ���w�肷��̂� ���k�� "z" �͎w�肵�Ȃ��悤�ɂ��܂��B
$ find ./ -type f -newer ${BASE_FILE_PATH} -exec tar rf ${TAR_FILE_PATH}.tar {} \;
TAR �{�[�����������ň��k���܂��B
$ gzip -f ${TAR_FILE_PATH}.tar
�Ō�ɔ�r�Ώۂ̃t�@�C���� touch �R�}���h�ōX�V���Ă����� �������̌ォ��̍������擾���邱�Ƃ��ł��܂��B
$ touch ${BASE_FILE_PATH}
�ς�� 2018/11/14
- JavaScript�� { } �𗝉����� - Qiita (2018/11/09)
- �yWindows 10�z�u�����LINE���C���X�g�[������Ă����v�̐����������i2018�N11��11���j - LINE�̎d�g�� (2018/11/11)
- HTTP-over-QUIC�ƌĂ�Ă����v���g�R���̖��̂�HTTP/3�� - �X���h IT (2018/11/14)
Windows ��� .htaccess �̂悤�ȃt�@�C�����쐬����
�i�g�p���Ă��� Windows �� Windows 10 �ł��j
Windows ��ŕ��ʂ� .htaccess �̂悤�ȁu . �i�h�b�g�j�v ����n�܂�t�@�C�����쐬���悤�Ƃ���� �g���q�݂̂Ɣ��f����� ���̂悤�ɃG���[���o�Ă��܂��܂��B
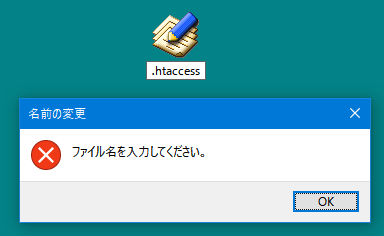
�ŋߒm�����̂ł����A���������Ƃ��� ���̂悤�Ƀt�@�C�����̍Ō�ɂ��u . �v�����܂��B

��������� �Ō�́u . �v�͏����� .htaccess �ɂȂ�܂��B

����̓t�H���_�Ȃǂł������ł��B
���̕��@���� �R�}���h�v�����v�g�⑼�̕��@���g��Ȃ��Ă� �ȒP�Ɂu . �v����n�܂�t�@�C������邱�Ƃ��ł��܂��B
�ς�� 2018/11/08
- Windows��IP�A�h���X����z�X�g���i�R���s���[�^�[���j����������@�inbtstat�R�}���h���g����NetBIOS������肷��j - ��IT (2018/04/05)
- Windows�Ńz�X�g������IP�A�h���X����������@ - ��IT (2018/04/19)
- Windows�̃p�X��蕶���́A�Ȃ��t�X���b�V���ɂȂ����̂��H - ASCII.jp (2018/10/28)
- Google Chrome�̃f�x���b�p�[�c�[����Web�T�[�o�^�A�v���Ƃ̃v���g�R����X�L�[���ׂ� - ��IT (2018/11/07)
Windows �� �V�X�e�� �G���[ 1219 �������Ȃ��Ƃ��̑Ώ��@
�����ł��B
�i�g�p���Ă��� Windows �� Windows 10 �ł��j
���̂悤�Ƀl�b�g���[�N�h���C�u�̊��蓖�Ă����悤�Ƃ����Ƃ��� �u�V�X�e�� �G���[ 1219�v���������邱�Ƃ�����܂��B
C:\> NET USE P: \\fileserver ...
�V�X�e�� �G���[ 1219 ���������܂����B �������[�U�[�ɂ��A�T�[�o�[�܂��͋��L���\�[�X�ւ̕����̃��[�U�[���ł̕����̐ڑ��͋�����܂���B �T�[�o�[�܂��͋��L���\�[�X�ւ̈ȑO�̐ڑ������ׂĐؒf���Ă���A�Ď��s���Ă��������B
�����Ă��� NET USE ... /DELETE �ʼn������܂��� ���܂ɃG���[�������Ȃ��Ƃ�������܂��B
NET USE �Ō��Ă��ꗗ�ɕ\�����ꂸ�B
C:\> NET USE
�V�����ڑ��͋L������܂���B
�ꗗ�ɃG���g�������݂��܂���B
����ȂƂ��A�Ƃ肠�����̑Ώ��@�Ƃ��� ���̂悤�ɃT�[�o����IP�A�h���X�i�܂��͋t��IP�A�h���X����T�[�o���j�ɕύX���� �R�}���h�����s���܂��B
C:\> NET USE P: \\192.168.1.200 ...
�T�[�o�����ݒ肳��Ă��Ȃ��ꍇ�� �����̃p�\�R���� lmhosts �ȂǂɋL�ڂ���Ɨǂ��ł��B
find �R�}���h�œ������w�肵�Č��o����
�����ł��B
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
find �R�}���h�� -mtime �I�v�V�������g���� �t�@�C���̍X�V���������ɂ��āu�`���O�v�̂悤�Ȍ��o���ł��܂��B
$ find ./ -mtime -3
��̓I�ɓ������w�肵�Č��o����ɂ� ���̂悤�� -newermt �I�v�V�������g�p���܂��B �i-newermt �� m �� Modify �� m �ŁAa �ɂ���� Access�Ac ���� Change �ɂȂ�܂��j
$ find ./ -newermt "2018/10/30 12:00"
�i���t�̏����͐F�X�w��ł��܂��j
����Ŏw�肵�����������^�C���X�^���v���傫���i�w�肵�������͊܂܂�Ȃ��j�t�@�C�������o���邱�Ƃ��ł��܂��B
-newerXY reference
Compares the timestamp of the current file with reference. The reference argument is normally the name
of a file (and one of its timestamps is used for the comparison) but it may also be a string describing
an absolute time. X and Y are placeholders for other letters, and these letters select which time
belonging to how reference is used for the comparison.
a The access time of the file reference
B The birth time of the file reference
c The inode status change time of reference
m The modification time of the file reference
t reference is interpreted directly as a time
Some combinations are invalid; for example, it is invalid for X to be t. Some combinations are not
implemented on all systems; for example B is not supported on all systems. If an invalid or unsup�]
ported combination of XY is specified, a fatal error results. Time specifications are interpreted as
for the argument to the -d option of GNU date. If you try to use the birth time of a reference file,
and the birth time cannot be determined, a fatal error message results. If you specify a test which
refers to the birth time of files being examined, this test will fail for any files where the birth
time is unknown.
find �R�}���h�œ���̃t�@�C���ȍ~�̍X�V�����o����
�����ł��B
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
find �R�}���h�� -mtime �I�v�V�������g���� �t�@�C���̍X�V���������ɂ��āu�`���O�v�̂悤�Ȍ��o���ł��܂��B
$ find ./ -mtime -3
�����̍�ƂōX�V�����t�@�C���ȍ~�ɍ쐬�E�X�V���ꂽ�t�@�C�������o�������ꍇ -newer �Ƃ����I�v�V�������g���܂��B
$ find ./ -newer hogehoge.txt
-newer file
File was modified more recently than file. If file is a symbolic link and the -H option or the -L
option is in effect, the modification time of the file it points to is always used.
���̃I�v�V�����́A�����̃t�@�C���̃^�C���X�^���v���^�C���X�^���v���V�����t�@�C�������o���Ă���܂��B
�����̃t�@�C���̃^�C���X�^���v�g���傫���h���߁A���̃t�@�C�����̂͊܂܂�܂���B �����̃t�@�C�����Ώۂ̒��ɂ����Ă��A���o����Ȃ��悤�ɂȂ��Ă�킯�ł��B �悭�l�����Ă܂��ˁB
ORACLE �Ŏ��s���� SQL������s�v���\������
ORACLE �Ŏ��s�v���\�����������������̂ł��� ���R�Ƀe�[�u����������ł͂Ȃ� �ǂ����悤���Ǝv���Ă����Ƃ���A ���s����SQL�ɑ��Ď��s�v���\��������@������܂����B
���̂悤�ɁuDBMS_XPLAN.DISPLAY_CURSOR�v���g�p���܂��B
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR());
�Ō�Ɏ��s����SQL�̎��s�v�悪���̂悤�ɕ\������܂��B
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
SQL_ID dyk4dprp70d74, child number 0
-------------------------------------
SELECT DECODE('A','A','1','2') FROM DUAL
Plan hash value: 1388734953
-----------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-----------------------------------------------------------------
| 0 | SELECT STATEMENT | | | 2 (100)| |
| 1 | FAST DUAL | | 1 | 2 (0)| 00:00:01 |
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
-----------------------------------------------------------------
�����ADISPLAY_CURSOR �̎��s�ɂ́uV$SQL_PLAN�AV$SESSION�����V$SQL_PLAN_STATISTICS_ALL.�̊e�Œ�r���[�ɑ���SELECT�������K�v�ł��B�v�Ƃ̂��Ƃł��B
[�Q�l]
DBMS_XPLAN - OracleR Database PL/SQL�p�b�P�[�W����у^�C�v�E���t�@�����X
���s����SQL���w�肷��ɂ́A V$SQL �� SQL_ID �ׂ� �ȉ��̂悤�Ɏ��s���܂��B
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('SQL_ID'));
���s����SQL�ɂ����g���܂��� �e�[�u���������Ȃ��ėǂ��̂͏�����܂��B
tar �R�}���h�Ńp�X��ύX���ēW�J������
�����ł��B
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
tar �R�}���h�œW�J����Ƃ��� �i�[����Ă���p�X�����̂܂g������ �p�X�̈ꕔ��ύX���ēW�J�������Ƃ�������܂��B
[�i�[�������p�X] home/hogehoge/test1/xxxxxx [�W�J�������p�X] /home/hogehoge/test2/xxxxxx
���̂悤�ɃI�v�V�����ƕύX���e���w�肷�邱�ƂŁA �p�X��ύX���Ȃ���W�J���邱�Ƃ��ł��܂��B
$tar xzvf xxxxx.tar.gz --transform='s/test1/test2/g'
File name transformations:
--transform=EXPRESSION, --xform=EXPRESSION
use sed replace EXPRESSION to transform file
names
�f�B���N�g���́u / �v���ύX�������ꍇ�� ���̂悤�ɋ�蕶�����u | �v�ȂǂɕύX���Ă����Ɨǂ��Ǝv���܂��B
$tar xzvf xxxxx.tar.gz --transform='s|hogehoge/test1|hugahuga/test2|g'
tar �R�}���h�ňꕔ������W�J������
�����ł��B
�i�g���Ă��� Linux �� Ubuntu 14.04.3 LTS �ł��j
tar �R�}���h�œW�J����Ƃ��� ����̃t�@�C����A����̃f�B���N�g���ȉ��̃t�@�C��������W�J�������Ƃ�������܂��B
���̂悤�Ƀp�X���w�肷�邱�ƂŁA���̃t�@�C��������W�J���邱�Ƃ��ł��܂��B
$ tar xvzf xxxxx.tar.gz home/hogehoge/test.html
���l�ɁA�f�B���N�g���̃p�X���w�肷��ƁA���̃f�B���N�g���ȉ���W�J�ł��܂��B
$ tar xvzf xxxxx.tar.gz home/hogehoge
�p�X�̎w��ɂ̓��C���h�J�[�h���g�����Ƃ��ł��܂��B
$ tar xvzf xxxxx.tar.gz --wildcards */hogehoge.png
File name matching options (affect both exclude and include patterns):
--wildcards use wildcards (default for exclusion)
--no-wildcards verbatim string matching
�]�k�ł����ATAB�L�[�̓��͕⊮�� .tar.gz �t�@�C���̒��̃p�X�܂� �w��ł��ăr�b�N�����܂����B
�ς�� 2018/11/01
- �u������͂���Ɠ���Ԃ��������v�ƒ�����]�藝�itsujimotter�̃m�[�g�u�b�N�j - �K�W�F�b�g�ʐM GetNews (2018/10/29)
