2010年 02月
- Excel のゼロを非表示にする書式
- 高橋メソッド風 プレゼンスクリプト
- 積ん読 2010/02/25
- PostgreSQL で月末日の取得
- Excel で 繰り返して使う機能をロック
- Excel のゼロの非表示
- Oracle で簡単棒グラフ表示
- PostgreSQL の DISTINCT ON
- sudo: sorry, you must have a tty to run sudo
- psql の 展開表示
- Excel の [Ctrl]+[Enter]
- PostgreSQL の ネットワーク接続設定
- 積ん読 2010/02/14
- オープンソースカンファレンス2010 Kansai@Kobe 3/13
- プロンプトに実行結果を表示する
- Excel の ふりがな
- シェルで文字列のマッチング
- nonstandard use of escape in a string literal
- PostgreSQL のログファイル名に日付を付与する
- Apache が提供する情報を制限する ServerSignature 編
- Apache が提供する情報を制限する ServerTokens 編
- PostgreSQL のセッションの情報を取り出す関数
- マイクロソフト セカンド ショット キャンペーン
- sudo で 環境変数を引き継ぐ
- Digest: generating secret for digest authentication
- 積ん読 2010/02/02
- 積ん読 2010/02/01
- PostgreSQL の ソート順
Excel のゼロを非表示にする書式
以前、シートのオプションで 0 を非表示にする「Excel のゼロの非表示」を 書きましたが、個別に設定するもっと良い方法があったので紹介します。
Excel の数値の書式には ";" (セミコロン) でプラス、マイナスの場合を分けることができます。
0.0;(0)
この書式では、プラスの時は“小数点1桁まで表示”、マイナスの時は“カッコで囲んで表示”になります。
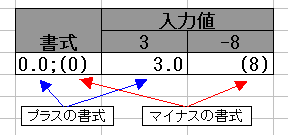
書式を 2 つに分けた場合、ゼロはプラスの書式で処理されます。
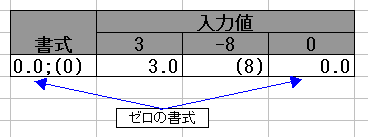
書式を 3 つに分けた場合、3 つ目がゼロの書式になります。
0.0;(0);[赤]0
この書式では、ゼロのときだけ赤字になります。
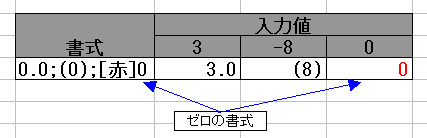
このゼロの書式を空にすることで ゼロを非表示にできます。
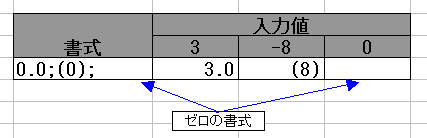
";"(セミコロン) が 1 つの場合と 2 つの場合では マイナス値を扱う書式が違ってくるので要注意です。
0.0;(0); ← ゼロは非表示 0.0;(0) ← ゼロはプラスの書式で表示
高橋メソッド風 プレゼンスクリプト
高橋メソッドという大きな字が特徴的なプレゼン手法(本家より引用)があるのですが 社内で簡単に技術的な説明をするときなどに いつも使わせてもらっています。
高橋メソッド http://www.rubycolor.org/takahashi/
いつもは、PowerPoint を使ったりしていたのですが HTML と JavaScript でもできそうな気がしたので Web ブラウザで動くプレゼン用スクリプトを作ってみました。
サンプルとして 高橋メソッドのサイト内の「高橋メソッドについて」という 高橋メソッドによる 高橋メソッドの紹介コンテンツを このプレゼンスクリプトで再現してみました。
<pre>タグだけで 簡単に作れるようにしてありますので 興味がある人は試して見てください。
積ん読 2010/02/25
- 激動の時代を駆け抜けた「Internet Explorer 6」の葬儀が開催へ - GIGAZINE (2010/02/24)
- グーグル、「Google Apps」に続き「YouTube」でもIE 6のサポートを終了 - Computerworld.jp (2010/02/24)
- 日本Sambaユーザー会がSamba3ノウハウ集日本語版を公開 - ITpro (2010/02/24)
PostgreSQL で月末日の取得
db=# SELECT DATE_TRUNC('month', now() + '1 months') + '-1 days';
?column?
------------------------
2010-02-28 00:00:00+09
(1 row)
翌月の月初日から 1 日引きます。
Excel で 繰り返して使う機能をロック
あなたは知ってる?ダブルクリックだけでできるExcelの小技いろいろ - IDEA*IDEA 〜 百式管理人のライフハックブログ
この記事を読んで知ったのですが、ダブルクリック技の 1 つに 「繰り返して使う機能をロック」という機能があるそうです。
Excel 2000 で試してみたところ、 「書式のコピー/貼り付け」しか確認できなかったのですが とても便利だと感じたので紹介します。
まずは通常の使い方から。
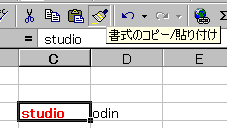
「書式のコピー/貼り付け」をクリックします。
アイコンは凹んだ状態になります。
その状態で別のセルをクリックします。
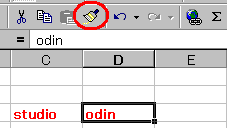
クリックしたセルに書式が貼り付けられます。
同時に「書式のコピー/貼り付け」のアイコンも元に戻ります。
今度は「書式のコピー/貼り付け」をダブルクリックします。
やはりアイコンは凹んだ状態になります。
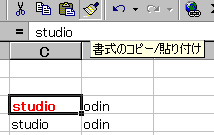
ただし、ダブルクリックした場合は、 別のセルに書式を貼り付けても、アイコンが凹んだままになります。
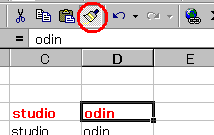
続けて、他のセルにも書式を貼り付け続けることができます。
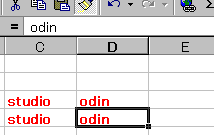
書式のコピペは 結構使用するので覚えておくと役に立ちそうです。
Excel のゼロの非表示
他人の作った Excel で 値 0 を 次のような条件付書式で 非表示にしているシートがありました。
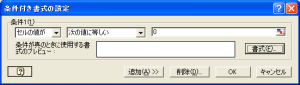
一部分の 0 だけであれば これでも良いのですが シート全体の場合、 オプションで非表示にすることができます。
「ツール」→「オプション」の「表示」タブに『ゼロ値』という オプションがあります。( Excel2000 の場合)

このオプションのチェックを外すと、次のようなシートの 0 が・・・

消えてしまいます。

このオプションは、設定したシートのみで有効で シートに保存されるので、そのまま人に渡すこともできます。
Excel は、オプションによって シートのみで有効のものや、Excel 全体や ブックで有効なものあるので 難しいです。
Oracle で簡単棒グラフ表示
Oracle の SQL で簡単に棒グラフを作る小ネタです。
表示制御のために COLUMN とかを使っていますが ポイントは LPAD 関数の使い方です。
SQL> COLUMN TNAME FORMAT A30 SQL> COLUMN BAR FORMAT A30 SQL> SELECT tname, LPAD('*', LENGTH(tname), '*') AS bar FROM TAB; TNAME BAR ------------------------------ ------------------------------ W_AB_T_OPTAR_POLOLOPL_CLOSED **************************** W_START ******* E_AB_T_PLANT ************ E_AB_T_EERCC_BODY ***************** E_AB_T_EERCC_HEAD ***************** E_AB_PLANT_DATA *************** E_AB_KUJIDE_BODY **************** E_AB_KUJIDE_HEAD **************** R_AB_T_OPTAR_CLOSED ******************* R_AB_T_OPTAR_KAMOKU ******************* R_AB_KK_DATA ************
このサンプルはテーブルの名前の長さという かなりどうでも良いものを棒グラフにしてますが (棒グラフ化しなくてもそのままですし)、 棒グラフ化することで 見えやすくなるものは結構あると思います。
PostgreSQL の DISTINCT ON
PostgreSQL には 通常の DISTINCT ではない DISTINCT ON というものがあります。
次のようなテーブルがあるとします。
db1=# SELECT * FROM distinct_test;
field1 | field2 | field3
--------+--------+--------
1 | 4 | 1
1 | 4 | 2
2 | 2 | 1
2 | 2 | 2
3 | -1 | 1
3 | -1 | 2
(6 rows)
まずは通常の DISTINCT です。
db1=# SELECT DISTINCT field1, field2
FROM distinct_test;
field1 | field2
--------+--------
1 | 4
2 | 2
3 | -1
(3 rows)
この場合、列に指定した field1, field2 の順番でソートされます。
列の指定の順番を変えます。
db1=# SELECT DISTINCT field2, field1
FROM distinct_test;
field2 | field1
--------+--------
-1 | 3
2 | 2
4 | 1
(3 rows)
今度は field2, field1 でソートされます。
これはまぁ、こういうものです。
DISTINCT ON を使ってみます。
DISTINCT ON (field1, field2) のカッコの中と
列の指定 "field1, field2, field3" が
違うことに注意してください。
db1=# SELECT DISTINCT ON (field1, field2) field1, field2, field3 FROM distinct_test; field1 | field2 | field3 --------+--------+-------- 1 | 4 | 1 2 | 2 | 1 3 | -1 | 1 (3 rows)
行数は DISTINCT で field1, field2 を指定したときと同じです。
つまり DISTINCT ON を使用すると カッコの中で指定した列で まとめられ、カッコの中で指定していない列(この例だと field3 )は 最初に見つかったものが出力されます。
「 DISTINCT でまとめたいけど、他の列も欲しい!」というときに便利ですね。 ただ、このままだと DISTINCT ON に指定していない列は どの値が出るのか保障されないため、ソートをかけてやる必要があります。
ORDER BY によるソートは次のようになります。
db1=# SELECT DISTINCT ON (field1, field2) field1, field2, field3 FROM distinct_test ORDER BY field1; field1 | field2 | field3 --------+--------+-------- 1 | 4 | 1 2 | 2 | 1 3 | -1 | 1 (3 rows) db1=# SELECT DISTINCT ON (field1, field2) field1, field2, field3 FROM distinct_test ORDER BY field2; ERROR: SELECT DISTINCT ON expressions must match initial ORDER BY expressions db1=# SELECT DISTINCT ON (field1, field2) field1, field2, field3 FROM distinct_test ORDER BY field3; ERROR: SELECT DISTINCT ON expressions must match initial ORDER BY expressions
DISTINCT ON の先頭で指定されている field1 以外の 列では エラーになってしまいます。
ORDER BY でソートするには、 DISTINCT ON で指定した列(指定順)の後に、DISTINCT ON 以外の列を書く必要があります。
db1=# SELECT DISTINCT ON (field1, field2) field1, field2, field3 FROM distinct_test ORDER BY field1, field2, field3 DESC; field1 | field2 | field3 --------+--------+-------- 1 | 4 | 2 2 | 2 | 2 3 | -1 | 2 (3 rows)
こうすることによって GROUP BY で MAX() を使ったのと 同じ値を取得すことができました。
sudo: sorry, you must have a tty to run sudo
sudo を cron などからバッチ処理で使用しようとすると 次のようなエラーが発生することがあります。
sudo: sorry, you must have a tty to run sudo
「端末から実行しないとダメ」と言ってるのですが どうしても cron で実行したい場合は、 sudo の設定ファイル /etc/sudoers の Defaults requiretty パラメータを修正します。
/etc/sudoers は visudo で編集します。
# visudo
【変更前】 Defaults requiretty 【変更前】 Defaults !requiretty
特定のユーザのみ許可したい場合は次のように設定します。
Defaults:hogehoge !requiretty
これで、ユーザ hogehoge は 端末なしで sudo できます。
psql の 展開表示
ブログなどのサイト上で SQL の実行結果を載せることがありますが 次のように出力されると ちょっと見辛いものがあります。
db1=# select * from pg_database where datname = 'postgres';
datname | datdba | encoding | datistemplate | datallowconn | datco
nnlimit | datlastsysoid | datvacuumxid | datfrozenxid | dattablespac
e | datconfig | datacl
----------+--------+----------+---------------+--------------+------
--------+---------------+--------------+--------------+-------------
--+-----------+--------
postgres | 10 | 6 | f | t |
-1 | 10792 | 499 | 499 | 16
63 | |
(1 row)
こういうときに展開表示を使います。
db1=# \x
Expanded display is on.
この設定によって 次のように結果が縦に展開されます。
db1=# select * from pg_database where datname = 'postgres';
-[ RECORD 1 ]-+---------
datname | postgres
datdba | 10
encoding | 6
datistemplate | f
datallowconn | t
datconnlimit | -1
datlastsysoid | 10792
datvacuumxid | 499
datfrozenxid | 499
dattablespace | 1663
datconfig |
datacl |
psql の起動時から設定するときは -x オプションを使用します。
$ psql -x db1
Excel の [Ctrl]+[Enter]
Excel の入力系の技の 1 つに [Ctrl] を押しながら入力 (Enter) というものがあります。
それほど使う頻度は高くないと思いますが どちらもよく使用するキーなので 簡単に指で覚えることができます。
まず範囲を選択します。

次に値を入力します。
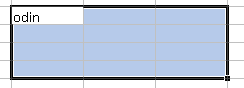
この状態で [Enter] だけを押すと、 通常の“選択範囲内での入力”になり 隣のセルにフォーカスが移動するだけです。
しかし、ここで [Ctrl] を押しながら [Enter] を押します。
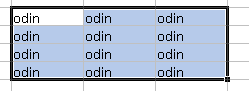
選択していた範囲のセル全てに 入力した値が設定されました。
もちろん、これだけではありません。
このショートカットは、数式を入力するときに真価を発揮します。
例えば、"=row()" を入れてみます。
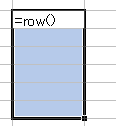
行番号が表示されました。
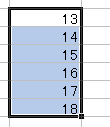
どのセルにも "=row()" が入るわけですが 当然値が違います。
集計する場合も便利です。
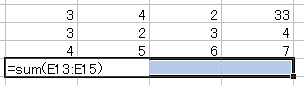
E13:E15 のようなセル指定も セルをコピーするときと同様に 展開してくれます。
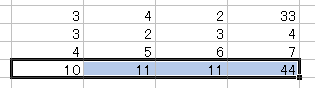
慣れるまでは、1 つのセルに入力した値をコピーする方が 楽なように感じると思いますが 多くの場合、コピーする範囲は最初から決まっているので 範囲を指定してからこの方法で入力する方が キーを押す回数も少なくて速くなると思います。
PostgreSQL の ネットワーク接続設定
PostgreSQL では pg_hba.conf を使って接続設定を行いますが その前に ネットワーク接続の設定を postgresql.conf に行う必要があります。 (デフォルトでも動くと思いますが)
PostgreSQL は、TCP/IP ソケット や UNIX ドメインソケット を使って接続します。 わからなければ、TCP/IP ソケット は、ネットワーク、UNIX ドメインソケット は ローカル → ローカルの非ネットワーク通信だと考えてください。 外部から接続する場合、TCP/IP ソケット を使いますが、 ローカルから使う場合は TCP/IP ソケット でも UNIX ドメインソケット でも通信できます。
設定は postgresql.conf の listen_addresses パラメータを使用しますが CentOS や Redhat では デフォルトでは 次のようにコメントアウトされています。 コメントアウトされている場合のデフォルト値は localhost です。
#listen_addresses = 'localhost' # what IP address(es) to listen on;
# comma-separated list of addresses;
# defaults to 'localhost', '*' = all
# (change requires restart)
この場合に PostgreSQL が LISTEN しているアドレスを netstat コマンドで 確認してみます。
localhost なので 次のように 127.0.0.1 で LISTEN していました。 また、ついでに UNIX ドメインソケットも見えます。
# netstat -an | grep LISTEN | grep 5432 tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN unix 2 [ ACC ] STREAM LISTENING 343193 /tmp/.s.PGSQL.5432
この設定では IP アドレスが 127.0.0.1 として アクセスされたものしか接続できません。 外部から 192.168.1.92 といった IP アドレスでアクセスされた場合は 接続できないわけです。
外部から接続させるには 通常 listen_addresses パラメータに '*' (アスタリスク) を設定します。
listen_addresses = '*'
この場合は netstat の結果が 0.0.0.0 となります。
# netstat -an | grep LISTEN tcp 0 0 0.0.0.0:5432 0.0.0.0:* LISTEN unix 2 [ ACC ] STREAM LISTENING 343193 /tmp/.s.PGSQL.5432
0.0.0.0 の場合 127.0.0.1 でも 192.168.1.92 でも接続することができます。
他にも カンマで区切って指定することもできます。
listen_addresses = 'localhost,192.168.1.92'
この場合は netstat の結果が 次のように複数出てきます。
# netstat -an | grep LISTEN tcp 0 0 192.168.1.92:5432 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN unix 2 [ ACC ] STREAM LISTENING 343193 /tmp/.s.PGSQL.5432
TCP/IP ソケット を使用せず UNIX ドメインソケットのみで使用する場合は listen_addresses パラメータに 空文字を設定します。
listen_addresses = ''
この場合は netstat の結果が 次のように複数出てきます。
# netstat -an | grep LISTEN
unix 2 [ ACC ] STREAM LISTENING 343193 /tmp/.s.PGSQL.5432
(Web サーバなどの) アプリケーションサーバと PostgreSQL サーバが同じマシンで 外部から接続させる必要がないのであれば、こうしておくと ネットワークを使用した接続を禁止できます。
積ん読 2010/02/14
- デザイナーがwebサービスを10週間で作れるようになる方法。または私は如何にしてPHPを愛するようになったか。 - ウェブ狂の詩 (2010/02/04)
- cmd.exe のコマンドラインの仕様を解析してみた - 永遠に未完 (2010/02/10)
オープンソースカンファレンス2010 Kansai@Kobe 3/13
オープンソースカンファレンス (OSC) が 3/13 (土) に 神戸で開催されることになりました。
オープンソースカンファレンス2010 Kansai@Kobe - Beef Up Kobe!
関西は 京都で開催されてきましたが 神戸も追加されたようです。
以下は、事務局からの案内メールの抜粋です。
□■□ --【オープンソースカンファレンス2010 Kansai@Kobe】-- □■□ ★セミナー参加登録受付中!⇒⇒⇒ http://www.ospn.jp/osc2010-kobe/ ◆日時:3月13日(土)10:00-18:00 ◆入場:無料 ◆会場:神戸市産業振興センター (兵庫県神戸市) ◆主催:オープンソースカンファレンス実行委員会 ◆共催:地域ICT推進協議会(COPLI) ◆内容:オープンソース関連の最新情報提供 (展示・セミナー)
もちろん今年も 7月に Kansai@Kyoto も開催されます!
7/9 (金) 7/10 (土) @京都コンピュータ学院 です。
プロンプトに実行結果を表示する
シェル (bash) のプロンプト改造のネタです。
プロンプトは 環境変数 PS1 を変更することで 表示内容を自由に変えることができるのですが 今回は コマンドなどの実行結果 ($?) を表示させてみます。
$ PS1="\u:\w[code:\$?]$ " hogehoge:~[code:0]$
これで OK です。
次のように エラーが発生すると エラーコードが表示されます。
hogehoge:~[code:0]$ ls aaaaaaa ls: aaaaaaa: そのようなファイルやディレクトリはありません hogehoge:~[code:2] $
.bashrc などでわざわざ設定する必要はありませんが シェルを作成するときに 一時的に設定すれば 結果が確認しやすくなります。
Excel の ふりがな
Excel には「ふりがな」を扱う機能があります。
昔からメニューにあるのですが、意外と知られていないようです。
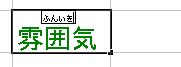
表示すると次のようになります。

「ふりがな」の値は、セルに値を入力すときに 自動で設定してくれます。 ですので、漢字一文字ずつを違う読みで入力した場合 次のように変な感じに設定されてしまうことがあります。

Office 2000 の場合、「書式」の中にメニューがあります。
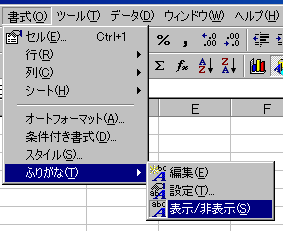
「設定」では、平仮名や片仮名、表示位置の設定ができます。 「編集」では、現在設定されている値を変更することができます。
結構重要なことですが、並び替えを行なうときは この「ふりがな」の値が利用されます。 ですので、同じ“生”という漢字を使っても 次のように並んでしまいます。

テキストエディタなどから貼り付けた場合は 「ふりがな」が設定されません。 次の図の右の列は「ふりがな」が設定されていないため 見たままの並び順になっています。

シェルで文字列のマッチング
シェルで文字列のマッチングするには、シェルの構文だけではできないので 次のように test をうまく使います。
$ if [ ! -z `echo $文字列 | grep "パターン"` ]; then
"-z" は、文字列の長さが 0 なら真になるオプションです。 バッククォーテーション内で echo した文字列が パターンにマッチすると その文字列を返すので それを比較に利用しています。
$ FILE=test_file_0209.csv $ if [ ! -z `echo $FILE | grep "^test_file_....\.csv$"` ]; then > echo "match" > else > echo "no match" > fi match
といった感じになります。
perl の正規表現を使いたい場合は "-P" オプションを付けます。
$ if [ ! -z `echo $文字列 | grep -P "パターン"` ]; then
nonstandard use of escape in a string literal
PostgreSQL で 次の WARNING が発生することがあります。
WARNING: nonstandard use of escape in a string literal HINT: Use the escape string syntax for escapes, e.g., E'\r\n'.
これは SQL の中にバックスラッシュの文字リテラルが ある場合に起こるのですが HINT の通り 'E' を付けることで対応できます。
次のような SQL で発生します。
警告は出ますが、結果も取得できます。
db1=# SELECT REPLACE(field1, '\n', '\\n') FROM table1;
WARNING: nonstandard use of escape in a string literal
LINE 1: SELECT REPLACE(field1, '\n', '\\n') FROM table1
^
HINT: Use the escape string syntax for escapes, e.g., E'\r\n'.
WARNING: nonstandard use of \\ in a string literal
LINE 1: SELECT REPLACE(field1, '\n', '\\n') FROM table1
^
HINT: Use the escape string syntax for backslashes, e.g., E'\\'.
replace
------------------------------------------------------
test "test!"\ntest "test!"\ntest "test!"\nこんにちは
HINT に従って 文字リテラルに 'E' を付けます。
db1=# SELECT REPLACE(field1, E'\n', E'\\n') FROM table1; replace ------------------------------------------------------ test "test!"\ntest "test!"\ntest "test!"\nこんにちは
これで WARNING が出なくなりました。
PostgreSQL のログファイル名に日付を付与する
PostgreSQL はログをローテーションする機能を持っています。
Redhat であればデフォルトで 次のようにMonやWedなどの曜日の文字列が 付与されて、ローテーションする形になっています。
$ ls /var/lib/pgsql/data/pg_log
postgresql-Mon.log
postgresql-Tue.log
postgresql-Wed.log
これは postgres.conf の log_filename パラメータで 設定することができます。 Redhat のデフォルト(曜日)は次のように設定されています。
log_filename = 'postgresql-%a.log'
年月日を付与するには、次のように設定します。
log_filename = 'postgresql-%Y%m%d.log'
これで、次のようなログファイルができます。
$ ls /var/lib/pgsql/data/pg_log
postgresql-20091005.log
postgresql-20091006.log
postgresql-20091007.log
Apache が提供する情報を制限する ServerSignature 編
前回、ServerTokens ディレクティブについて説明しましたが 今回は ServerSignature ディレクティブです。
ServerSignature ディレクティブは CentOS の場合、デフォルトでは On になっています。
ServerSignature On
これが On になっていると Web サーバにアクセスして エラーになった場合に 次のように サーバの情報が表示されます。
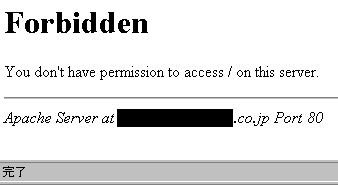
ここで表示される内容は ServerTokens ディレクティブの設定で変化します。 (上の例では "ProductOnly" を設定しています)
ServerSignature ディレクティブを Off に設定してみます。
ServerSignature Off
ServerSignature ディレクティブを Off に設定すると 次のように サーバの情報が表示されなくなります。

ちょっとしたことですが 情報の提示に対して 気を使ってる雰囲気を出すことも大事だと思います。
Apache が提供する情報を制限する ServerTokens 編
サーバの防衛の基本として、「攻撃者に多くの情報を提供しない」というものがあります。
現実に当てはめれば『独り暮らし』『平日の午前中は留守が多い』『セコムしてません』などの情報は 極力知られない方が良い、というのと同じですね。
今回は Web サーバ Apache の情報制限です。
CentOS などでは、 Apache をインストールすると デフォルトでは ServerTokens ディレクティブは次のように "OS" が設定されています。 (設定ファイルは /etc/httpd/conf/httpd.conf です)
ServerTokens OS
この場合、Webサーバにアクセスすると次のような値が戻ります。
HTTP/1.1 403 Forbidden
Date: Tue, 02 Feb 2010 05:36:28 GMT
Server: Apache/2.2.3 (CentOS)
Accept-Ranges: bytes
Content-Length: 5043
Connection: close
Content-Type: text/html; charset=UTF-8
Server: を見ると "Apache/2.2.3 (CentOS)" のように バージョン番号から OS まで 出力してしまっています。
これでは、仮に 2.2.3 に重大なセキュリティホールがあった場合、狙ってくださいと 言ってるようなものですよね。
というわけで、これを表示させないように変更します。
ServerTokens ProductOnly
このように設定すると、表示が "Apache" だけになります。
HTTP/1.1 403 Forbidden
Date: Tue, 02 Feb 2010 05:38:45 GMT
Server: Apache
Accept-Ranges: bytes
Content-Length: 5043
Connection: close
Content-Type: text/html; charset=UTF-8
ServerTokens ディレクティブの デフォルト値は "Full" で、 これ以上は隠せないようです。
ちなみにこの設定は ServerSignature の表示内容にも影響します。 ServerSignature については、また次回。
PostgreSQL のセッションの情報を取り出す関数
PostgreSQL には SQL でセッションの情報を取得する関数が 色々と定義されています。 簡単に紹介していきたいと思います。
version()
接続した PostgreSQL サーバのバージョンの文字列を返します。
db1=# SELECT version();
version
-------------------------------------------------------------------
PostgreSQL 8.3.5 on i386-redhat-linux-gnu, compiled by GCC gcc (GC
(1 row)
current_database()
接続した データベースの名前を返します。
$ psql db1 postgres db1=# SELECT current_database(); current_database ------------------ db1 (1 row)
current_schema()
現在のスキーマ名を返します。
接続した直後は、postgresql.conf の search_path パラメータの 定義に依存した値を返します。 検索パスが空の場合は NULL を返します。
db1=# SELECT current_schema();
current_schema
----------------
public
(1 row)
CREATE TABLE などをする際に、スキーマ名を明示的に 定義しない場合、このスキーマ名が設定されます。
検索パスは set で変えることができます。
db1=# set search_path = 'hogehoge'; db1=# SELECT current_schema(); current_schema ---------------- hogehoge (1 row) db1=# set search_path = 'public','hogehoge'; db1=# SELECT current_schema(); current_schema ---------------- public (1 row)
検索パスにスキーマを複数指定した場合は、先頭のスキーマが 現在のスキーマとなります。
current_schemas(boolean)
検索パス内のスキーマを返します。 boolean に true をセットすると暗黙のスキーマも返します。
db1=# SELECT current_schemas(false); current_schemas ----------------- {postgres,public} (1 row) db1=# SELECT current_schemas(true); current_schemas ----------------- {pg_catalog,postgres,public} (1 row)
session_user
データベースに接続したユーザ名を返します。
$ psql db1 postgres db1=# SELECT session_user; session_user -------------- postgres (1 row) db1=# \q $ psql db1 hogehoge db1=# SELECT session_user; session_user -------------- hogehoge (1 row)
current_user, user
current_user と user は同じです。
current_user は、現在実行しているユーザ名を返します。 通常は session_user と同じですが、 SECURITY DEFINER 属性が付いた関数を実行した場合に 返す値が違ってきます。 SECURITY DEFINER 属性は、関数を作成したユーザの権限で 実行するオプションです。
$ psql db1 postgres db1=# SELECT session_user, current_user; session_user | current_user --------------+-------------- postgres | postgres (1 row)
SECURITY DEFINER 属性を付けた関数 test1() と 付けていない test2() を hogehoge ユーザで作成してみます。
$ psql db1 hogehoge db1=# SCREATE FUNCTION test1() RETURNS name AS 'SELECT current_user;' SECURITY DEFINER LANGUAGE SQL ; CREATE FUNCTION db1=# SCREATE FUNCTION test2() RETURNS name AS 'SELECT current_user;' LANGUAGE SQL ; CREATE FUNCTION
これを postgres ユーザで実行します。
$ psql db1 postgres db1=# select test1(); test1 ----------- hogehoge (1 row) db1=# select test2(); test1 ----------- postgres (1 row)
異なる値を返しました。 このように実際に実行している権限を確認する場合に current_user を使用します。
また、session_user を含め、ユーザ系は特殊で、括弧 () を付けずに 呼び出す必要があるので注意しましょう。
マイクロソフト セカンド ショット キャンペーン
Microsoft が MCP を 2 回受験できるキャンペーンをしています。
マイクロソフト セカンド ショット キャンペーン | プロメトリック
2010年1月25日(月) 〜 2010年6月30日(水) の期間に、1回の受験料で 同じ科目が 2 回受験できます。
春に向けてのスキルアップに利用してみてはどうでしょうか。
sudo で 環境変数を引き継ぐ
sudo を使うと root の権限でコマンドを実行することができますが デフォルトの設定では、環境変数も変わってしまうため 権限だけ root にすることができません。
というわけで、環境変数を引き継ぐようにしてみます。
sudo の設定ファイル /etc/sudoers を visudo で編集します。
# visudo
次のような箇所があります。
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE INPUTRC KD
LS_COLORS MAIL PS1 PS2 QTDIR USERNAME \
LANG LC_ADDRESS LC_CTYPE LC_COLLATE LC_IDEN
LC_MEASUREMENT LC_MESSAGES LC_MONETARY LC_N
LC_PAPER LC_TELEPHONE LC_TIME LC_ALL LANGUA
_XKB_CHARSET XAUTHORITY"
これは引き継ぐ環境変数を設定しています。
特定のユーザ (testuser1) で、全ての環境変数を引き継ぐには 次のような行を追加します。
Defaults:testuser1 !env_reset
testuser1 で sudo を使うと 環境変数を引き継いでくれます。
Digest: generating secret for digest authentication
httpd で error_log に次のようなメッセージが出ることがあります。
[notice] Digest: generating secret for digest authentication ... [notice] Digest: done
これは Digest 認証用のモジュール mod_auth_digest.so が ロードされているためのようです。
notice なので問題はないですが、 Digest 認証用を使用していないのであれば mod_auth_digest.so をロードしないように コメントアウトすれば出なくなります。
積ん読 2010/02/02
- Emacs Lisp基礎文法最速マスター - rubikitch loves (Emacs Ruby CUI) (2010/02/01)
- Vimスクリプト基礎文法最速マスター - 永遠に未完成 (2010/02/01)
- Java基礎文法最速マスター - 何かしらの言語による記述を解析する日記 (2010/01/30)
- awk 基礎文法最速マスター - AWK Users JP
- Lua基礎文法最速マスター - 良いもの。悪いもの。 (2010/02/02)
- jQuery基礎文法最速マスター - [to-R] (2010/02/02)
積ん読 2010/02/01
- Haskell基礎文法最速マスター - think and error (2010/01/31)
- Bash基礎文法最速マスター - 何かしらの言語による記述を解析する日記 (2010/01/31)
- VBA基礎文法最速マスター - 何かしらの言語による記述を解析する日記 (2010/01/29)
- VBScript 基礎文法最速マスター - CX's VBScript Diary (2010/01/31)
- JavaScript基礎文法最速マスター - なんとなく日記 (2010/01/31)
PostgreSQL の ソート順
CentOS や Redhat で PostgreSQL を入れた時に 日本語のソート順がおかしくなることがあります。
item_nm
----------------------
くり
なし
もも
みかん
りんご
いちじく
さくらんぼ
50 音順ではなく文字数の順番で 並んでしまうことがあります。
$ pg_controldata /var/lib/pgsql/data
Debian 系は /usr/lib/postgresql/x.y/bin/pg_controldata に あります。 (x.y は 8.1 などのバージョンです)
$ /usr/lib/postgresql/x.y/bin/pg_controldata \
/var/lib/postgresql/x.y/main/
この結果で、LC_COLLATE や LC_CTYPE が 下のように出力される場合、 日本語のソートがおかしくなります。
LC_COLLATE: en_US.UTF-8 LC_CTYPE: en_US.UTF-8
CentOS などでは、/etc/init.d/pgsql を実行したときに $PGDATA (/var/lib/pgsql/data) が存在しないと initdb を実行するのですが そのときのオプションに --no-local の指定がないので OS の環境がそのままセットされてしまうわけです。
ちなみに PostgreSQL CE の試験でも 日本語を使用する場合は --no-local を指定するのが良いとされていました。
こうなっている場合、initdb からやりなおす必要があります。 既存のデータはダンプを取っておけばリストアすることができます。
$PGDATA (/var/lib/pgsql/data) をリネームして 手動で "initdb --no-local" を実行することで pg_controldata の結果が次のようになります。
LC_COLLATE: C LC_CTYPE: C
ソート順も正しくなります。
item_nm
----------------------
いちじく
くり
さくらんぼ
なし
みかん
もも
りんご
OS 全体を変えても問題ない場合は、 /etc/sysconfig/i18n を修正するという手もあるようです。
LANG="ja_JP.UTF-8" # (修正後)
この場合 --no-local を設定する必要がなくなるので 既存の $PGDATA を消して /etc/init.d/pgsql を実行するだけです。
いずれにせよ、既存のデータがある場合 initdb を実行する前に 退避させておかないといけないので 注意してください。
