2016年 10月
PostgreSQL でも watch
以前、Linux の watch コマンドについて書きましたが PostgreSQL にも 9.3 から \watch メタコマンドが追加されました。
\watch [SEC] execute query every SEC seconds
psql=# SELECT CURRENT_TIME; timetz -------------------- 23:02:53.492804+09 (1 row) psql=# \watch 1 Watch every 1s Mon Oct 17 23:02:57 2016 timetz ------------------- 23:02:57.03674+09 (1 row) Watch every 1s Mon Oct 17 23:02:58 2016 timetz -------------------- 23:02:58.038192+09 (1 row)
このように 前に実行した SQL を一定間隔で実行してくれます。
終了は [Ctrl]+[c]です。
デフォルトは watch コマンドと同じように 2秒間隔のようです。
psql=# SELECT CURRENT_TIME; timetz -------------------- 23:01:20.790009+09 (1 row) psql=# \watch Watch every 2s Mon Oct 17 23:01:25 2016 timetz -------------------- 23:01:25.005323+09 (1 row) Watch every 2s Mon Oct 17 23:01:27 2016 timetz -------------------- 23:01:27.007919+09 (1 row)
INSERT や UPDATE も繰り返し実行できます。
psql=# INSERT INTO test_a VALUES ('a', 'b'); INSERT 0 1 psql=# \watch 1 Watch every 1s Mon Oct 17 23:09:25 2016 INSERT 0 1 Watch every 1s Mon Oct 17 23:09:26 2016 INSERT 0 1
psql=# UPDATE test_a SET field2 = 'c' WHERE field1 = 'a'; UPDATE 10 psql=# \watch 1 Watch every 1s Mon Oct 17 23:10:05 2016 UPDATE 10 Watch every 1s Mon Oct 17 23:10:06 2016 UPDATE 10
データの監視や 処理の繰り返しなどに 利用できそうですね。
WORD でコピペしたときにスペースが入らないようにする
WORD でパスなどの一部をコピペするときに 不要なスペースが入ってしまうことがあります。
例えば、こんな風にパスを記述していて・・・

ファイル名をコピーして・・・

ペーストします。

赤い印のところにスペースが入っています。
スペースが入ってしまったことに気づかないと後で困りますし 英語の文章を書かなければ困ることもないので 設定でスペースを入らないようにしてしまいます。
オプションから「詳細設定」を開いて 「貼り付け時に自動調整する」の横にある「設定」ボタンを押します。
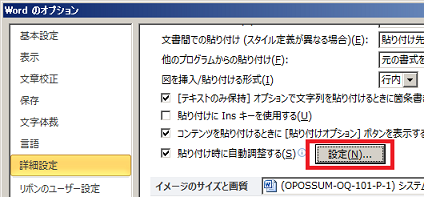
「文と単語の間隔を自動的に調整する」のチェックを外します。
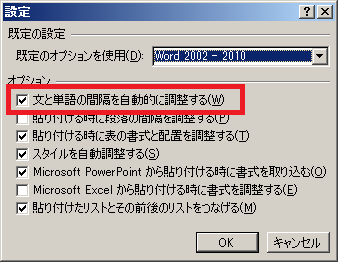
これでスペースが入らなくなります。

WORD でナビゲーションウィンドウで章構成を変更する
WORD 2010 くらいからだと思いますが アウトライン表示を使用しなくても、章構成を簡単に変更できるようになっていました。
まず、ナビゲーションウィンドウを表示します。
こんな感じで章の見出しが表示されます。
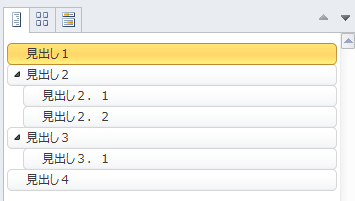
マウスで見出しを掴みます。
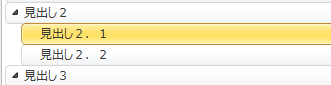
移動先にドロップします。

これだけで章が移動しました。
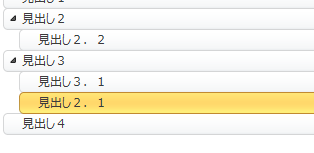
簡単で便利ですね。
SQL の LATERAL キーワード
PostgreSQL 9.3 から SQL に LATERAL というキーワードが記述できるようになっています。 また独自の拡張かと思いきや、この LATERAL は SQL標準 で規定されているそうです。 Oracle でも 12c からサポートされているようです。
[参考]
LATERALを使ってみよう ? Let's Postgres
使い方としては 遅延評価? みたいな感じでしょうか。 PostgreSQL では、LATERAL を副問い合わせや関数に対してして指定できるのですが、 FROM に指定した問い合せの結果を、副問い合わせの中で使用することができます。
たとえば、次のような SQL はエラーになります。
psql=# SELECT table1.field1, subquery1.field2 psql-# FROM table1 psql-# LEFT JOIN ( psql-# SELECT field2 FROM table2 psql-# WHERE table2.field1 = table1.field1) AS subquery1 psql-# ON TRUE;
これは 赤字の部分を副問い合わせで使用しているためです。
本来は、次のように副問い合わせから外に出す必要があります。
psql=# SELECT table1.field1, subquery1.field2 psql-# FROM table1 psql-# LEFT JOIN ( psql-# SELECT field2 FROM table2) AS subquery1 psql-# ON (subquery1.field1 = table1.field1);
ところが LATERAL を使うと 次のような書き方ができます。
psql=# SELECT table1.field1, subquery1.field2 psql-# FROM table1 psql-# LEFT JOIN LATERAL ( psql-# SELECT field2 FROM table2 psql-# WHERE table2.field1 = table1.field1) AS subquery1 psql-# ON TRUE;
LATERAL を指定した副問い合わせは 後から評価されるので 副問い合わせの中で FROM 句の問い合わせの列を使用することができます。
これだけだと 単に変な書き方ができる だけなのですが 後で評価されることが チューニングに役立つ場合があります。
例えば 部署(100件)と経費明細(500万件)から 部署ごとの経費を取得します。
psql=# SELECT ALL psql-# 部署.部署ID psql-# , 部署経費.合計金額 psql-# , 部署経費.明細件数 psql-# FROM psql-# 部署 psql-# LEFT JOIN psql-# ( psql-# SELECT ALL psql-# 部署ID psql-# , SUM(金額) AS 合計金額 psql-# , COUNT(*) AS 明細件数 psql-# FROM psql-# 経費明細 psql-# GROUP BY psql-# 部署ID psql-# ) AS 部署経費 psql-# ON psql-# ( psql-# 部署経費.部署ID = 部署.部署ID psql-# );
おそらくこんな SQL になると思います。
試した環境では 5,391ms でした。
LATERAL を使うと次のように書けます。
psql=# SELECT ALL psql-# 部署.部署ID psql-# , 部署.部署名 psql-# , 部署経費.合計金額 psql-# , 部署経費.明細件数 psql-# FROM psql-# 部署 psql-# LEFT JOIN psql-# LATERAL psql-# ( psql-# SELECT ALL psql-# SUM(金額) AS 合計金額 psql-# , COUNT(*) AS 明細件数 psql-# FROM psql-# 経費明細 psql-# WHERE psql-# 経費明細.部署ID = 部署.部署ID psql-# ) AS 部署経費 psql-# ON psql-# TRUE;
実はこの場合は逆に遅くなって 21,614 ms でした。 1行ずつ評価する方が時間がかかるようです。
キー項目ではない部署名を条件に追加します。
まず LATERAL を使わない SQL から。
psql=# SELECT ALL psql-# 部署.部署ID psql-# , 部署経費.合計金額 psql-# , 部署経費.明細件数 psql-# FROM psql-# 部署 psql-# LEFT JOIN psql-# ( psql-# SELECT ALL psql-# 部署ID psql-# , SUM(金額) AS 合計金額 psql-# , COUNT(*) AS 明細件数 psql-# FROM psql-# 経費明細 psql-# GROUP BY psql-# 部署ID psql-# ) AS 部署経費 psql-# ON psql-# ( psql-# 部署経費.部署ID = 部署.部署ID psql-# ) psql-# WHERE psql-# 部署.部署名 = 'システム1部';
Hash Right Join (actual time=3314.571..3314.574 rows=1 loops=1)
Hash Cond: ((t_kj_keihi_meisai.部署ID)::text = (部署.部署ID)::text)
-> HashAggregate (actual time=3314.411..3314.441 rows=141 loops=1)
-> Seq Scan on t_kj_keihi_meisai (actual time=0.121..716.138 rows=5021645 loops=1)
-> Hash (actual time=0.089..0.089 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Seq Scan on r_kj_jigyousho 部署 (actual time=0.022..0.085 rows=1 loops=1)
Filter: (部署名 = 'システム1部'::text)
Rows Removed by Filter: 99
これは 3,314ms でした。
次に LATERAL バージョン。
psql=# SELECT ALL psql-# 部署.部署ID psql-# , 部署.部署名 psql-# , 部署経費.合計金額 psql-# , 部署経費.明細件数 psql-# FROM psql-# 部署 psql-# LEFT JOIN psql-# LATERAL psql-# ( psql-# SELECT ALL psql-# SUM(金額) AS 合計金額 psql-# , COUNT(*) AS 明細件数 psql-# FROM psql-# 経費明細 psql-# WHERE psql-# 経費明細.部署ID = 部署.部署ID psql-# ) AS 部署経費 psql-# ON psql-# TRUE psql-# WHERE psql-# 部署.部署名 = 'システム1部';
Nested Loop (actual time=221.481..221.523 rows=1 loops=1)
-> Seq Scan on r_kj_jigyousho 部署 (actual time=0.029..0.070 rows=1 loops=1)
Filter: (部署名 = 'システム1部'::text)
Rows Removed by Filter: 99
-> Aggregate (actual time=221.448..221.449 rows=1 loops=1)
-> Bitmap Heap Scan on t_kj_keihi_meisai 経費明細 (actual time=217.928..219.075 rows=4633 loops=1)
Recheck Cond: ((部署ID)::text = (部署.部署ID)::text)
-> Bitmap Index Scan on t_yj_keihi_meisai_idx1 (actual time=217.882..217.882 rows=4633 loops=1)
Index Cond: ((部署ID)::text = (部署.部署ID)::text)
こちらは 221ms でした。 10倍以上速くなっています。
このように場合によっては かなり速くなることがあります。
また LATERAL を指定した場合 FROM の結果の行に対して 1行ずつ評価されるため INNER JOIN を指定した場合でも外部結合のように 元の結果の行を全て返すので注意が必要です。
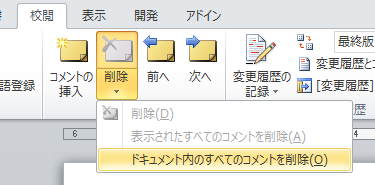
WORD でコメントを一括削除する
たまに忘れるのでメモ。
WORD 文書にはコメントを挿入することができますが 文書に挿入されたコメントを一括で削除するには 「校閲」のコメントの「削除」の更に下のメニューから 「ドキュメント内のすべてのコメントを削除」を選択します。